
不管是研究套利策略,还是多因子策略,都需要多品种的历史数据,所以下面介绍一下,如何调用vnpy的数据下载模块,来下载全市场的期货数据。
1)设置合约品种
首先,我们要先生成一个字典,来指定需要下载的数据,关键字段有3个:
这样,在RQData中,我们要下载螺纹钢指数合约的历史数据,需要转成的代号为RB99.SHFE。
然后,由于是全市场行情的数据,所以字典的数据结构如下:key是交易所,value是列表,里面包含各种期货品种,这样,只要在遍历一下这个字典,就可以得到所有,如RB99.SHFE这样结构的字符串。
symbols = {
"SHFE": ["CU", "AL", "ZN", "PB", "NI", "SN", "AU", "AG", "RB", "WR", "HC", "SS", "BU", "RU", "NR", "SP", "SC", "LU", "FU"],
"DCE": ["C", "CS", "A", "B", "M", "Y", "P", "FB","BB", "JD", "RR", "L", "V", "PP", "J", "JM", "I", "EG", "EB", "PG"],
"CZCE": ["SR", "CF", "CY", "PM","WH", "RI", "LR", "AP","JR","OI", "RS", "RM", "TA", "MA", "FG", "SF", "ZC", "SM", "UR", "SA", "CL"],
"CFFEX": ["IH","IC","IF", "TF","T", "TS"]
}
symbol_type = "99"
2) 设置下载时间
我们只需要设置下载的开始和结束时间即可,需要注意的是,vnpy数据下载模块的入参是datetime.datetime格式,所以,要做到格式的一致,代码如下:
from datetime import datetime
start_date = datetime(2005,1,1)
end_date = datetime(2020,9,10)
3)批量下载全市场数据
批量下载数据,并不难,其运作步骤如下:
from vnpy.trader.rqdata import rqdata_client
from vnpy.trader.database import database_manager
from vnpy.trader.constant import Exchange, Interval
from vnpy.trader.object import HistoryRequest
def load_data(req):
data = rqdata_client.query_history(req)
database_manager.save_bar_data(data)
print(f"{req.symbol}历史数据下载完成")
for exchange, symbols_list in symbols.items():
for s in symbols_list:
req = HistoryRequest(
symbol=s+symbol_type,
exchange=Exchange(exchange),
start=start_date,
interval=Interval.DAILY,
end=end_date,
)
load_data(req=req)写好脚本后,我们运行一下代码,可以看到很快就下完全市场期货的日线数据啦。

若要下载小时或者分钟级别数据,只要把日线周期(Interval.DAILY)改成对应的小时,或者分钟即可。
有了历史数据后,自然产生每天定时更新数据的需求
1)设置定时器
我们希望在收盘后,某个时间点如下午5点启动脚本,来自动下载数据。这本质上是包含了一个父进程和一个子进程。
父进程可以是一个永远在运行的python程序,如while循环,然后设置触发条件,如当时间刚好到下午5点就启动子进程下载更新数据,其他时间则睡觉等待。
代码如下:
from datetime import datetime, time
from time import sleep
current_time = datetime.now().time()
start_time = time(17,0)
while True:
sleep(10)
if current_time == start_time:
download_data()
2)获取数据库数据
更新数据时候,我们要以数据库里面最新的数据的时间点,作为开始时间,而结束时间就是当天。比如,昨天刚好下载完所有市场的数据,那么今天我们只需要下载从昨天到今天的所有数据即可。
这样实现起来也不难,步骤如下:
1)调用database_manager.get_bar_data_statistics来得到字典格式的数据数据库所有信息
data = database_manager.get_bar_data_statistics()
2)获取各品种最新数据的时间信息,并且插入到data字典中
for d in data:
newest_bar = database_manager.get_newest_bar_data(
d["symbol"], Exchange(d["exchange"]), Interval(d["interval"])
)
d["end"] = newest_bar.datetime
然后我们看看data字典,发现真的包含所有行情的数据,但我们是基于RQData来定期更新信息的,所以要进行筛选,得到国内期货品种(通过交易所来判断)并且是日线级别的数据。
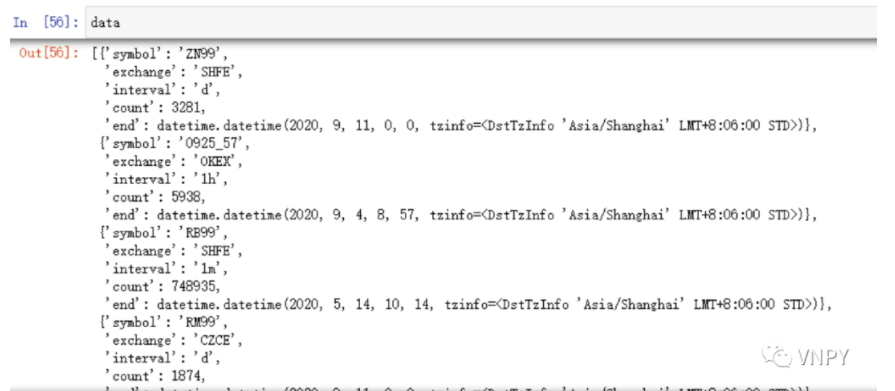
3)基于交易所和K线周期筛选品种,得到新的字典symbols,其中key包含合约代码,交易所,value就是数据库的结束时间,如下图:
symbols = {}
for i in data:
if i["interval"] == "d" and i["exchange"] in Exchanges:
vt_symbol = f"{i['symbol']}.{i['exchange']}"
end = i["end"].date()
symbols[vt_symbol] = end
4)设置下载结束时间为当天,基于symbols字典的信息,遍历组合得到HistoryRequest,然后再调用上面定义好的load_data函数下载数据并写入数据库中。
end_date = datetime.now().date()
for vt_symbol, start_date in symbols.items():
symbol = vt_symbol.split(".")[0]
exchange = vt_symbol.split(".")[1]
req = HistoryRequest(
symbol=symbol,
exchange=Exchange(exchange),
start=start_date,
interval=Interval.DAILY,
end=end_date,
)
load_data(req=req)
下载好之后,我们再获取数据库里面最新的K线时间,发现成功更新到今天了。
2019年已经进入最后倒计时,vn.py总算是赶上末班车发布了v2.0.9版本:期权交易。
本周一,国内三大沪深300指数相关的期权已经同时上线,分别是:
2.0.9版本主要更新了围绕期权交易方面的接口和应用,和之前一样,对于使用VN Studio的用户,启动VN Station后,直接点击界面右下角的【更新】按钮就能完成自动更新升级。
对于没有安装的用户,请下载VNStudio-2.0.9,体验一键安装的量化交易Python发行版,下载链接:
https://download.vnpy.com/vnstudio-2.0.9.exe
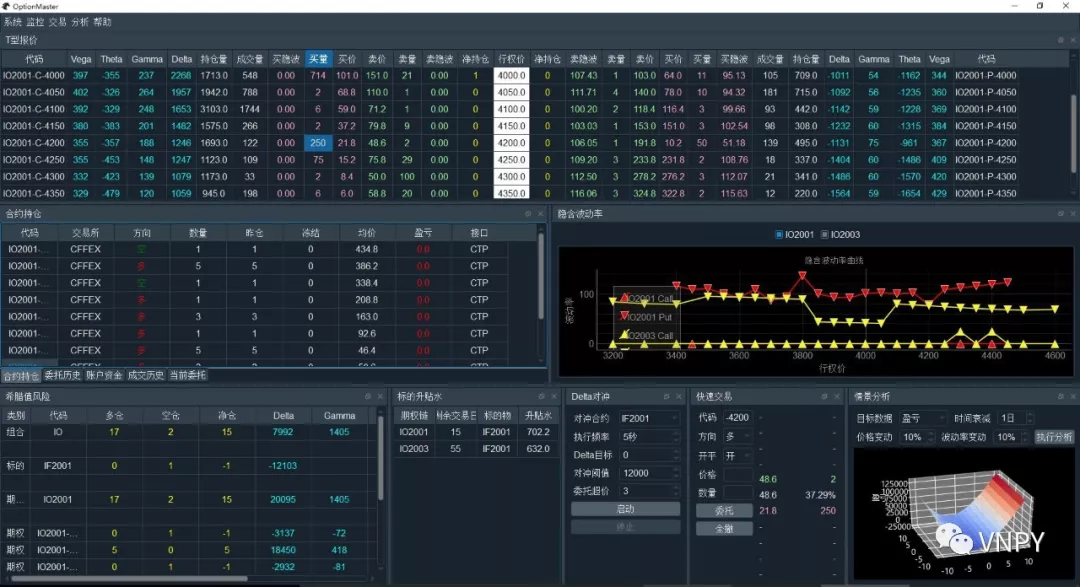
OptionMaster是vn.py框架内针对【期权波动率交易】专门设计的上层应用模块。
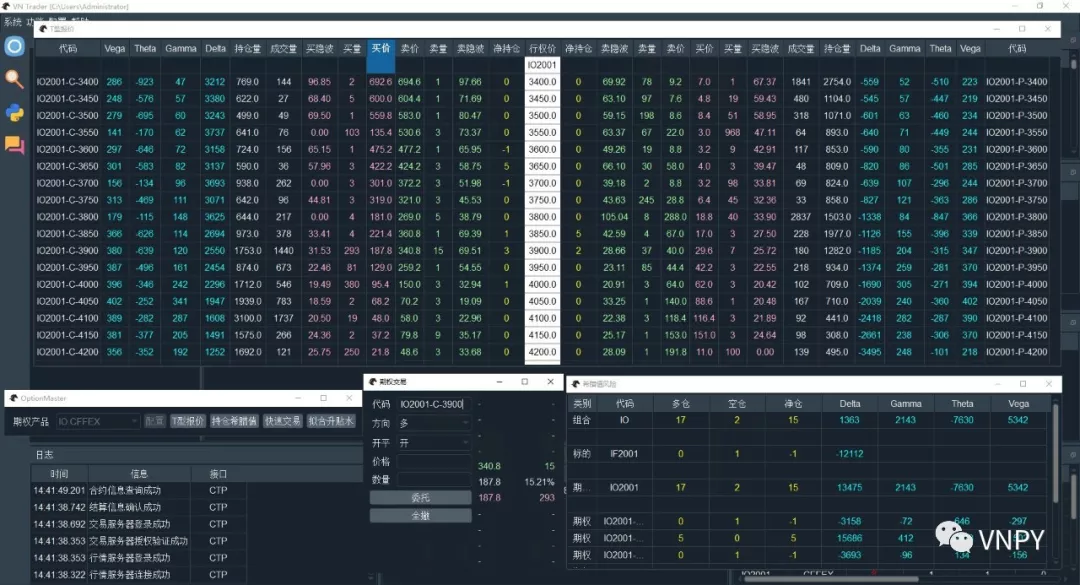
初始化配置

打开OptionMaster后,会看到上图中的长条形组件。【期权产品】下拉框中会显示当前已连接的交易接口上可选的期权产品组合。
注意底层接口必须支持期权合约的交易,这里才会有对应期权产品的显示,否则是不会有任何信息的(比如连接SimNow的CTP测试环境就没有)。
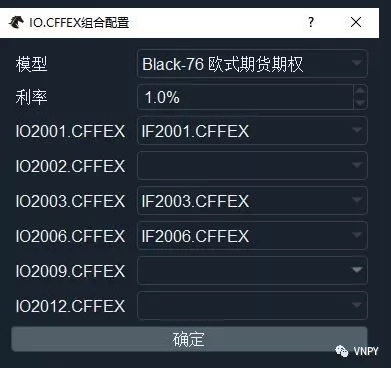
点击【配置】按钮后,弹出上图所示的组合配置对话框,在这里选择要用的期权定价模型,设置期权定价中用到的无风险利率,以及每个期权链定价所用的标的物合约。
注意期权链的标的物可以选择留空,此时该期权链在后续的交易中将不会被添加到期权组合中,可以降低一部分定价相关的计算延时。
期权定价
做期权交易,第一步总是离不开正确的定价,针对国内的期权类型,OptionMaster模块中内置了三大定价模型:
每个定价模型中,从计算方向来区分,又可以分为:
所有模型中都包含了输入数值的边界检查功能,避免计算出某些异常数值。
数据模型
期权相关的量化交易,和CTA策略等单标的量化交易相比,最大的区别之一就在于会同时交易大量的合约,包括不同行权价的期权、不同行权月份的期权以及标的物期货和股票(线性资产)。
同时以上合约之间的价格、成交、持仓等情况变化还会互相影响。在任意时间点结合当前最新行情数据的情况下,期权交易员需要能够实时跟踪整个期权交易组合的波动率曲面和希腊值风险情况。
OptionMaster中专门构建了多层嵌套式的立体数据结构,来解决以上多合约数据计算中的复杂性问题:
当以上数据结构中的任意一个数据发生变化时,会同时触发与之相关的所有计算,保证整体数据结构的一致性。
T型报价
T型报价是期权交易中最常用的行情显示方式,中间白色的一列为行权价,左侧为看涨期权,右侧为看跌期权。
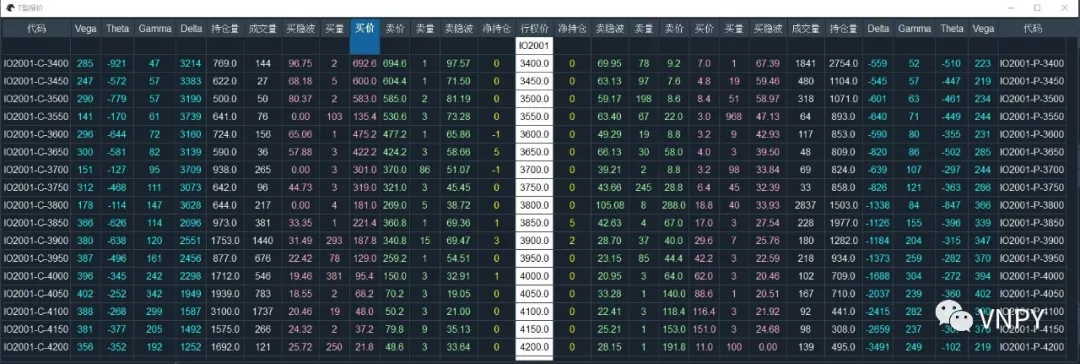
上图中,除了由交易接口层推送过来的原始行情数据外(买卖价格、挂单数量、成交量、持仓量等),还包含了实时计算的买卖价隐含波动率和每个期权的现金希腊值。
传统意义上的理论希腊值,直接基于期权定价模型计算,衡量的是当某一变量发生变化时期权价格的变化情况。这种方法从数学的角度容易理解,但是从交易员的实盘使用来说却十分麻烦。
假设某个50ETF期权合约的Delta数值,使用Black-Scholes期权定价公式计算出来的结果为0.5482,意味着每当ETF价格上涨1元时,该期权的价格应该上涨0.5482元。
而50ETF当前的价格大约是3元,上涨1元是足足超过30%的涨幅,对交易员来说,知道【标的物价格上涨30%期权能赚0.5482元】不能说完全没有参考价值,但效果可能也就跟【每天喝10瓶可乐一定会胖】差不多。
所以在实践中,专业期权交易员更多使用的是现金希腊值,衡量的是当某一变量发生1%变化时该期权对应的现金盈亏情况。还是用上面的这个50ETF期权合约,其现金Delta为:
0.5484(理论Delta)x 3(标的价格)x 10000 (合约乘数)x 1% = 165
这里的165,意味着每当ETF价格上涨1%时,持有1手该期权合约的盈利金额是165元,实盘交易中用来判断某个合约当前的风险水平无疑要方便得多。
除了Delta数据外,理论Gamma/Theta/Vega等希腊值也可以同样转化为更加直观的现金希腊值。
希腊值风险
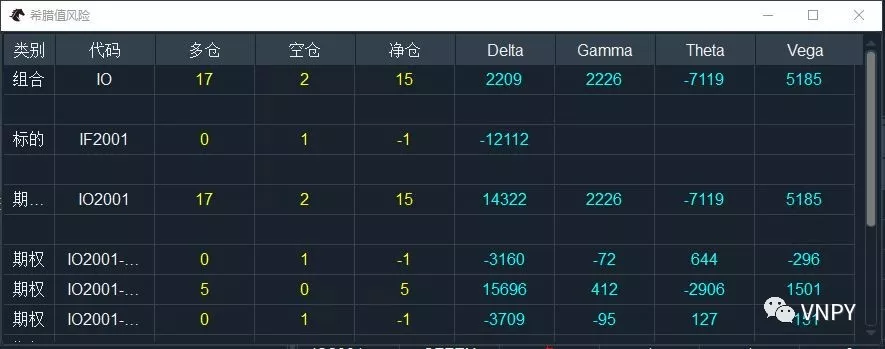
有了现金希腊值,可以在交易前方便直观的了解某一期权合约的风险水平。但在交易完成后,手头持有一堆期权和标的物持仓时,我们更需要持仓希腊值来跟踪当前整个账户的期权风险暴露:
持仓希腊值 = 现金希腊值 x 合约持仓
上图中的持仓希腊值的风险,分为单合约、期权链、期权组合三个层次统计,方便交易员结合各种不同类型的波动率交易策略使用(如做多近月波动率、做空远月波动率)。
快速交易
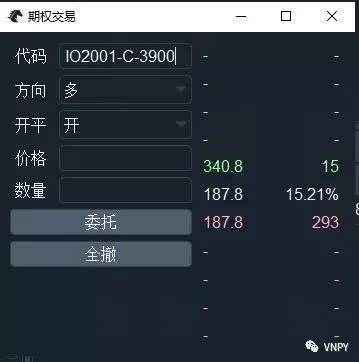
和VN Trader主界面的交易下单组件使用类似,在上图中的【代码】编辑框中输入合约代码后回车,即可显示该合约的行情盘口数据。或者在T型报价组件上,寻找到好的交易机会后,双击单元格即可完成合约代码的自动填充和行情显示。
选好方向、开平,输入价格、数量后,点击【委托】按钮即可立即发出交易委托,点击【全撤】按钮则可一次性将当前处于活动状态的委托(未成交、部分成交)全部撤单。
2.0.9版本中同样更新完善了和期权相关的交易接口,目前针对期权合约可用的包括:
目前所有的ETF期权程序化交易(包括sopt),都需要曾经向上交所报备过、有程序化交易权限的老账户,有小道消息传闻新账户的报备将在最近放开。
最后,附上开发中的OptionMaster Pro期权交易系统,采用vn.py框架以及OptionMaster模块组件开发。
除了在核心的定价模型方面进行了Cython低延时优化,也加入了波动率曲面实时跟踪、持仓风险情景3D分析、期权组合Delta自动对冲算法等功能。
最后,还有针对期权高频套利设计的电子眼算法引擎(开发中尚未完成):
考虑到几大股指期权刚上线,期权程序化交易方面的监管尚未明朗,OptionMaster Pro目前仅对机构用户提供试用。
需要下载软件的用户,请加vn.py机构用户群(QQ群号676499931),本群只对机构用户开放,加群申请中请注明:姓名/机构/部门。
了解更多知识,请关注vn.py社区公众号。

TradeBlazer交易开拓者(简称TB),可能是许多投资者开始接触量化时的第一根拐杖,也是国内用户量最大的量化平台之一。
但随着时间过去,国内量化投资者编程水平的逐渐提高,越来越多的人开始转向Python这样的开源生态体系。
在转换平台的过程中,由于编程语法、数据结构、驱动机制等方面的区别,不少人遇到了各种困难,掉在某些坑里可能几周都爬不出来。
本篇文章中我们就来通过一个的经典趋势跟踪策略AtrRsiStrategy,来详细讲解如何一步步将TB策略代码移植到vn.py上的过程。
完整的ATR-RSI策略逻辑如下:
注意点:我们总是假设在当前K线走完计算信号并且发出委托,成交永远发生在下一根K线。即T时刻计算信号,发出委托;最快也要T+1时刻该委托才能成交。这也是下面停止单和限价单撮合的充分条件。
创建RSI指标函数
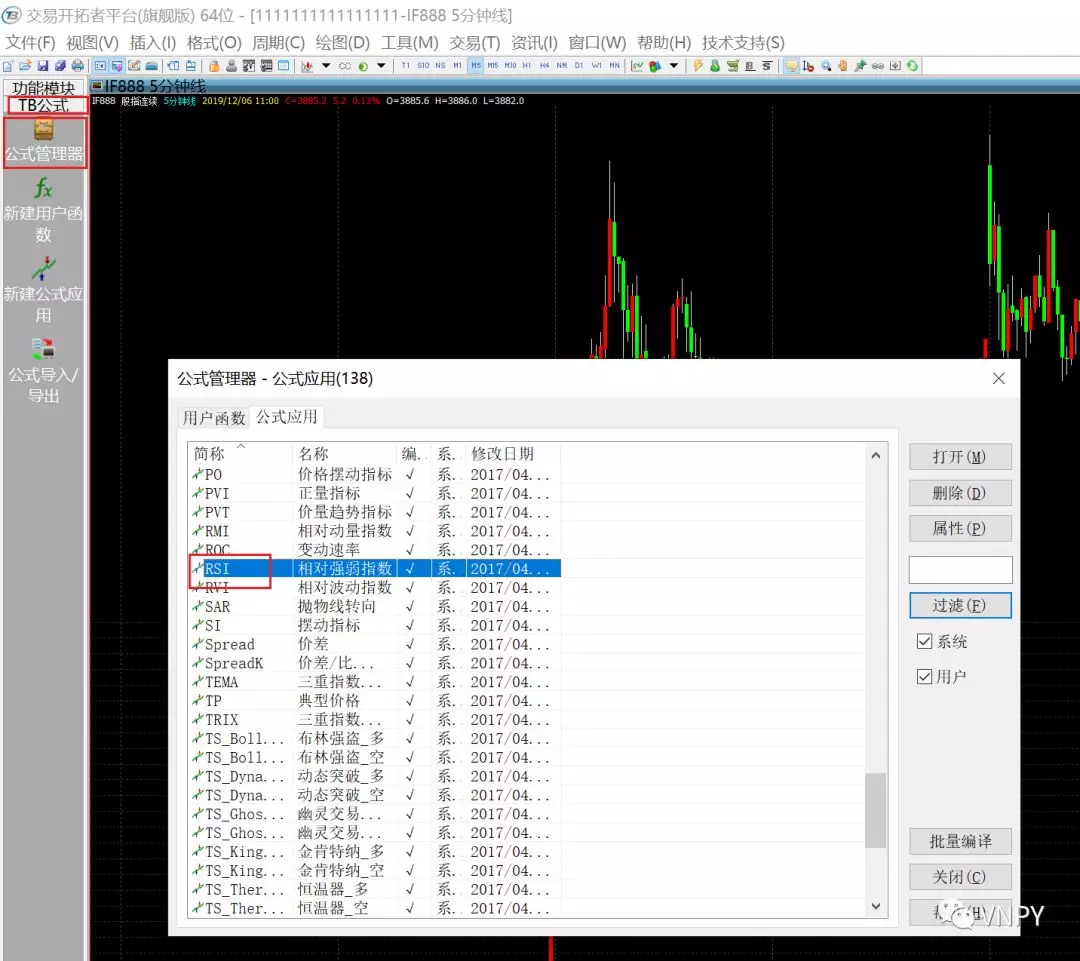
创建ATR-RSI策略
Params
Numeric rsi_length(5);
Numeric rsi_entry(16);
Vars
NumericSeries rsi_array(0);
NumericSeries rsi_value(0);
NumericSeries rsi_buy(0);
NumericSeries rsi_sell(0);
Begin
// Calculate Rsi Value
rsi_buy = 50 + rsi_entry;
rsi_sell = 50 - rsi_entry;
rsi_array = rsirsi(rsi_length);
rsi_value = rsi_array[1];
计算当前ATR指标,atr_value = atr_array[1];以及当前ATR均值,atr_ma= atr_ma_array[1]
Params
Numeric atr_length(22);
Numeric atr_ma_length(10);
Vars
NumericSeries atr_value(0);
NumericSeries atr_ma(0);
NumericSeries atr_arry(0);
NumericSeries atr_ma_array(0);
Begin
// Calculate Atr Value and Atr Ma
atr_arry = AvgTrueRange(atr_length);
atr_ma_array = Average(atr_arry[atr_ma_length], atr_ma_length);
atr_value = atr_arry[1]; // last bar for atr_value
atr_ma = atr_ma_array[1]; // last bar for atr_ma_value
空仓情况下,发出限价单委托开仓:
If(MarketPosition == 0)
{
intra_trade_low = Low[1];
intra_trade_high = High[1];
// 【Long condition】
If(rsi_value > rsi_buy AND atr_value > atr_ma)
{
long_limit = Close[1] + 5;
If(long_limit>=Low)
{
Buy(fixed_size, Min(Open, long_limit));
}
}
// 【Short condition】
Else If(rsi_value < rsi_sell AND atr_value > atr_ma)
{
short_limit = Close[1] - 5;
If(short_limit <=High)
{
SellShort(fixed_size, Max(Open, short_limit));
}
}
}
百分比移动止盈止损离场:
// postition >0
Else If(MarketPosition >0)
{
intra_trade_high = Max(intra_trade_high, High[1]);
intra_trade_low = Low[1];
long_stop = intra_trade_high * (1 - trailing_percent / 100);
If(Low <= long_stop)
{
Sell(MarketPosition, Min(Open, long_stop));
}
}
// postiton < 0
Else If(MarketPosition <0)
{
intra_trade_low = Min(intra_trade_low, Low[1]);
intra_trade_high = High[1];
short_stop = intra_trade_low *(1+ trailing_percent /100);
If(High >= short_stop)
{
BuyToCover(-MarketPosition, Max(Open, short_stop));
}
}
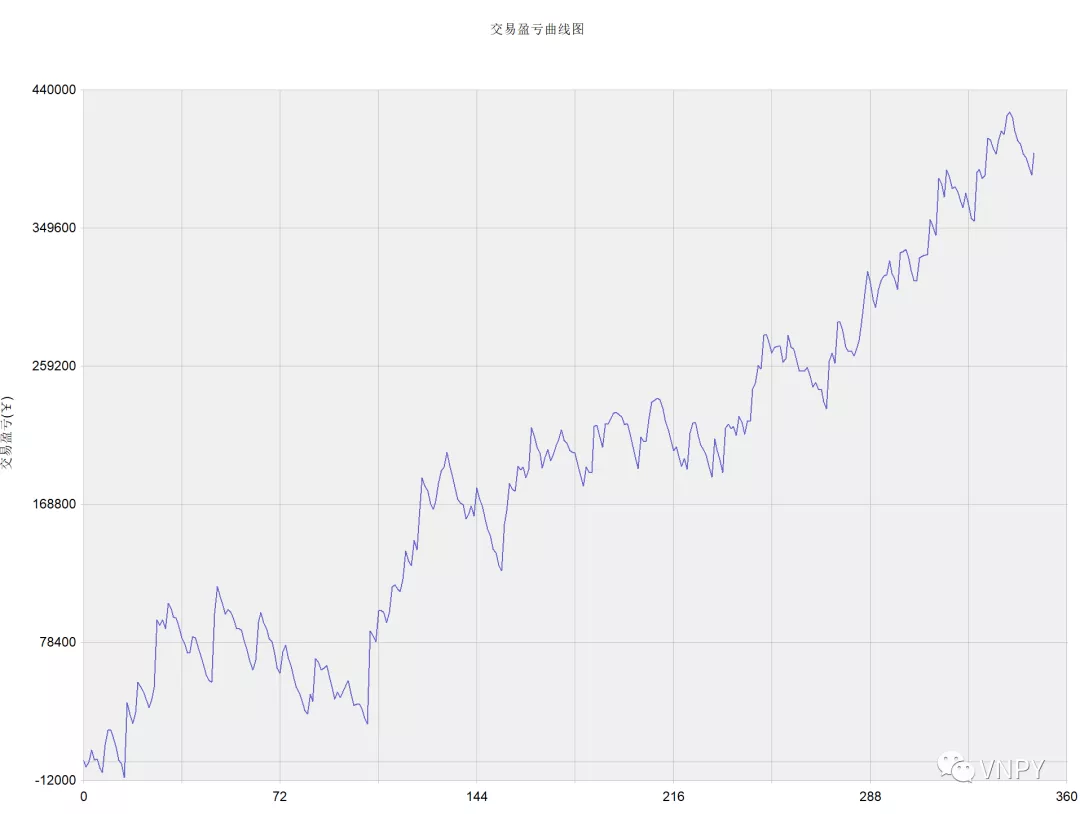
策略回测结果
TB完整代码
Params
Numeric atr_length(22);
Numeric atr_ma_length(10);
Numeric rsi_length(5);
Numeric rsi_entry(16);
Numeric trailing_percent(0.8);
Numeric fixed_size(1);
Vars
NumericSeries rsi_array(0);
NumericSeries atr_value(0);
NumericSeries atr_ma(0);
NumericSeries rsi_value(0);
NumericSeries rsi_buy(0);
NumericSeries rsi_sell(0);
NumericSeries intra_trade_high(0);
NumericSeries intra_trade_low(0);
NumericSeries atr_arry(0);
NumericSeries atr_ma_array(0);
NumericSeries long_stop(0);
NumericSeries short_stop(0);
NumericSeries long_limit(0);
NumericSeries short_limit(0);
Begin
// Calculate Rsi Value
rsi_buy = 50 + rsi_entry;
rsi_sell = 50 - rsi_entry;
rsi_array = rsirsi(rsi_length);
rsi_value = rsi_array[1];
// Calculate Atr Value and Atr Ma
atr_arry = AvgTrueRange(atr_length);
atr_ma_array = Average(atr_arry[atr_ma_length], atr_ma_length);
atr_value = atr_arry[1]; // last bar for atr_value
atr_ma = atr_ma_array[1]; // last bar for atr_ma_value
If(MarketPosition == 0)
{
intra_trade_low = Low[1];
intra_trade_high = High[1];
// 【Long condition】
If(rsi_value > rsi_buy AND atr_value > atr_ma)
{
long_limit = Close[1] + 5;
If(long_limit>=Low)
{
Buy(fixed_size, Min(Open, long_limit));
}
}
// 【Short condition】
Else If(rsi_value < rsi_sell AND atr_value > atr_ma)
{
short_limit = Close[1] - 5;
If(short_limit <=High)
{
SellShort(fixed_size, Max(Open, short_limit));
}
}
}
// postition >0
Else If(MarketPosition >0)
{
intra_trade_high = Max(intra_trade_high, High[1]);
intra_trade_low = Low[1];
long_stop = intra_trade_high * (1 - trailing_percent / 100);
If(Low <= long_stop)
{
Sell(MarketPosition, Min(Open, long_stop));
}
}
// postiton < 0
Else If(MarketPosition <0)
{
intra_trade_low = Min(intra_trade_low, Low[1]);
intra_trade_high = High[1];
short_stop = intra_trade_low *(1+ trailing_percent /100);
If(High >= short_stop)
{
BuyToCover(-MarketPosition, Max(Open, short_stop));
}
}
End
TB策略的逻辑完全由行情驱动,即每次有行情变化(Tick更新、K线走完)时会完整执行代码中的所有逻辑。与之不同的是,vn.py内置的CTA策略模板,提供了诸多的事件驱动回调函数,如:Tick更新驱动(on_tick函数)、K线驱动(on_bar函数)、成交驱动(on_trade)、委托驱动(on_order)等。
要移植TB上的策略,只需在vn.py策略代码的on_bar回调函数中实现对应的策略逻辑即可:
def on_bar(self, bar: BarData):
"""
Callback of new bar data update.
"""
self.cancel_all()
am = self.am
am.update_bar(bar)
if not am.inited:
return
atr_array = am.atr(self.atr_length, array=True)
self.atr_value = atr_array[-1]
self.atr_ma = atr_array[-self.atr_ma_length:].mean()
self.rsi_value = am.rsi(self.rsi_length)
if self.pos == 0:
self.intra_trade_high = bar.high_price
self.intra_trade_low = bar.low_price
if self.atr_value > self.atr_ma:
if self.rsi_value > self.rsi_buy:
self.buy(bar.close_price + 5, self.fixed_size)
elif self.rsi_value < self.rsi_sell:
self.short(bar.close_price - 5, self.fixed_size)
elif self.pos > 0:
self.intra_trade_high = max(self.intra_trade_high, bar.high_price)
self.intra_trade_low = bar.low_price
long_stop = self.intra_trade_high * \
(1 - self.trailing_percent / 100)
self.sell(long_stop, abs(self.pos), stop=True)
elif self.pos < 0:
self.intra_trade_low = min(self.intra_trade_low, bar.low_price)
self.intra_trade_high = bar.high_price
short_stop = self.intra_trade_low * \
(1 + self.trailing_percent / 100)
self.cover(short_stop, abs(self.pos), stop=True)
self.put_event()
完整的代码实现请参考Github仓库中的策略源代码。
策略回测结果
K线数据访问区别
TB
vn.py
委托撮合逻辑区别
TB
vn.py
策略回测结果区别
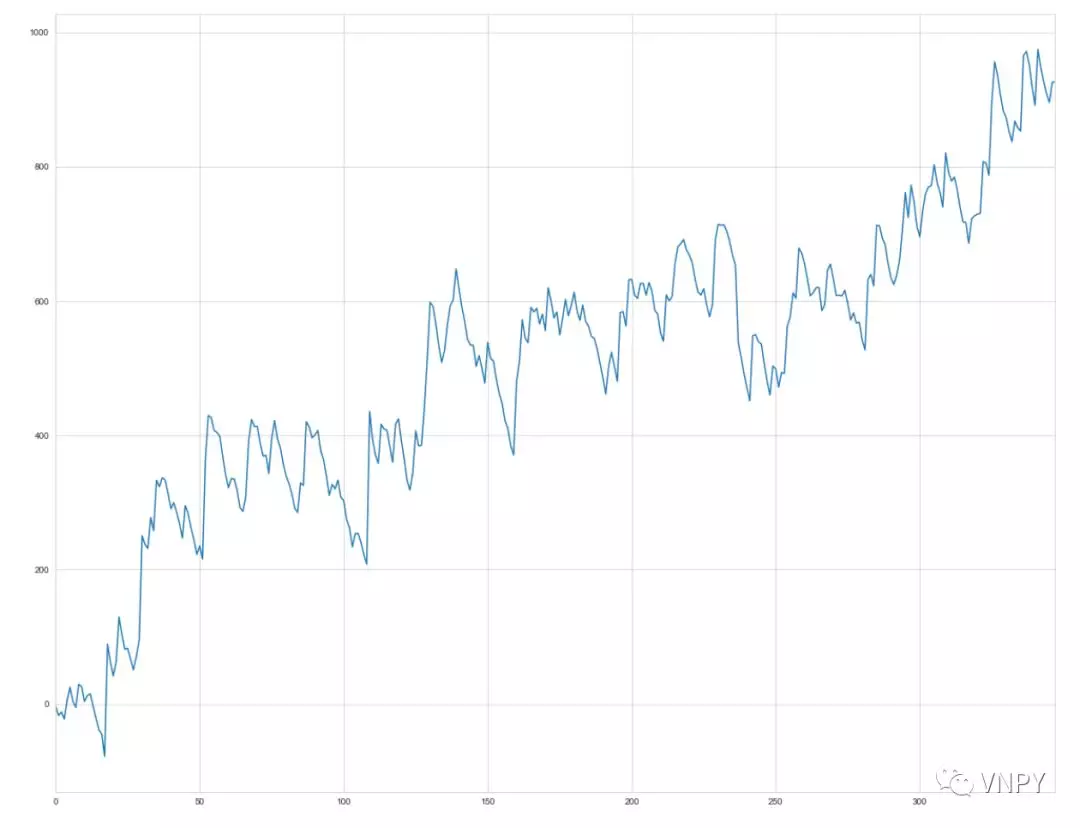
即使在策略逻辑层面已经做到一致,TB和vn.py的回测资金曲线图依旧可能存在某些细节方面的区别。主要原因是数据源方面的不同,TB使用的是自身提供的历史数据源,而vn.py默认推荐使用的是RQData数据服务。
了解更多知识,请关注vn.py社区公众号。

逐笔成交统计想用通用化,难点在于去限定一次完整开平交易的开始点和结束点,抽象来说就是寻找特殊的断点对所有成交记录进行划分。
断点的选择
而在算法状态机控制中,我们可以知道数字0是一个非常有用的评判标准,即我们构建一列数据,让它数值在完全平仓后变成0,就知道真正的平仓时间。
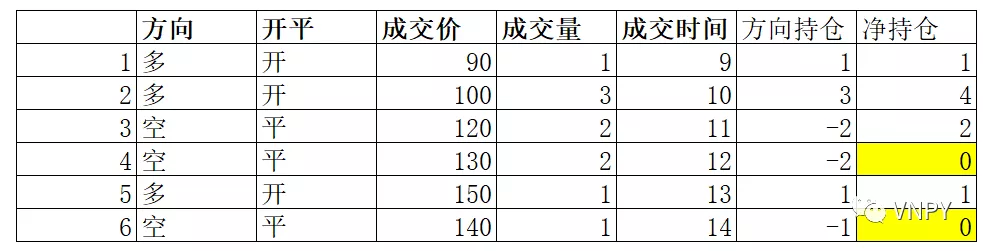
在实践中,累计净持仓恰恰好符合这个标准,我们把多头仓位设为”+”,空头仓位设为“-”,得到如下表的【方向持仓】,对【方向持仓】进行累计得到【净持仓】。
这样,我们基于【净持仓】为0可以得到每次开平交易的结束点。而该结束点为成交记录的断点。
使用断点划分成交记录
为了简单演示,下面我们只显示【净持仓】(列)为0的成交信息(行),如下表所示,一共发生了5开完整的开平仓交易。每笔交易的结束点对应的交易序号分别为3、5、8、12、20。这5个结束点即为对所有成交信息的断点。

之后,我们要引入2个新的概念:
存量是静态的,可以理解为对累计统计量的信息进行时间切片;而增量是动态的,代表时间切片信息的变化量,所以他们二者的关系如下:
T0时刻存量 + T0->T1增量 = T1时刻存量
换句话说,
T0->T1增量 = T1时刻存量 - T0时刻存量
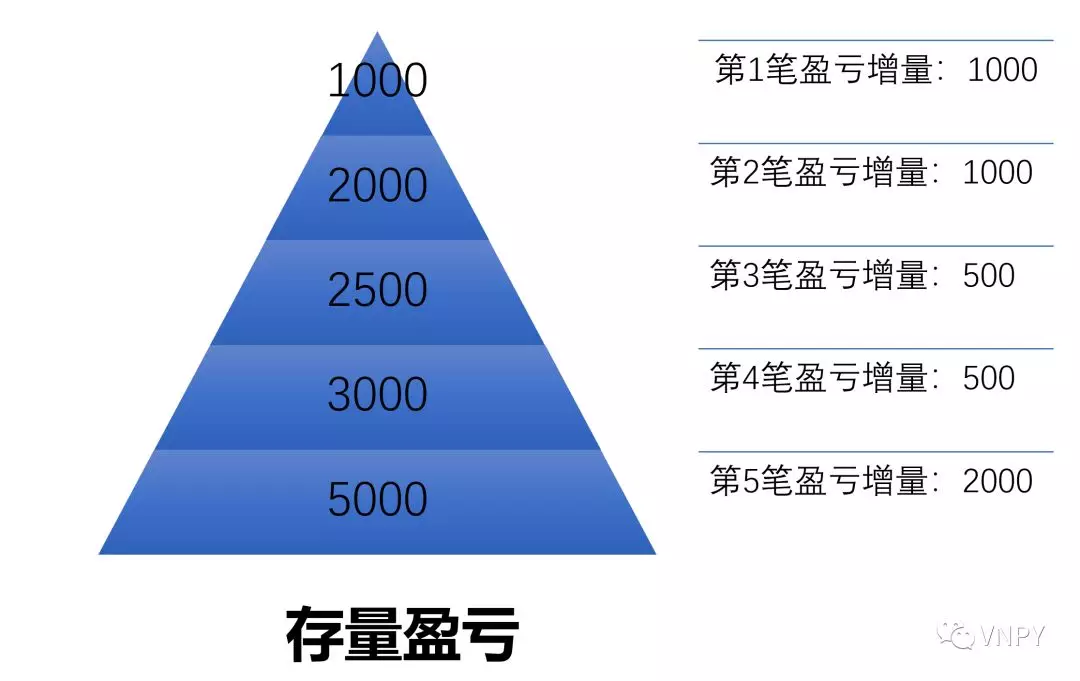
回到逐笔回测统计主题上,增量这个概念,就能代表最新的完整开平仓交易,例如其每笔盈亏,对累计盈亏的影响。
如下图所示,在完成第一笔开平仓交易后,累计盈亏是1000;完成了第二笔完整的开平仓交易,累计盈亏是2000,那么二者的差别,即2000-1000=1000。这增加1000的盈利,就是属于第二笔开平仓交易的。
所以,通过对每个断点存量信息的对比,我们就可以得到每笔开平仓成交后的统计量:
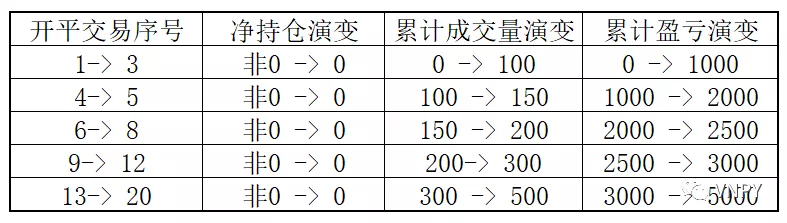
这些开平仓的统计量可以如下表所示的开平成交量、开平盈亏,也可以是开平仓交易的持仓时间、手续费、滑点以及净盈亏:
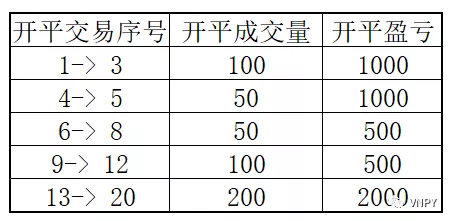
计算开平交易结果
import pandas as pd
from datetime import datetime
import matplotlib.pyplot as plt
import numpy as np
pd.set_option('mode.chained_assignment', None)
def calculate_trades_result(trades):
"""
Deal with trade data
"""
dt, direction, offset, price, volume = [], [], [], [], []
for i in trades.values():
dt.append(i.datetime)
direction.append(i.direction.value)
offset.append(i.offset.value)
price.append(i.price)
volume.append(i.volume)
# Generate DataFrame with datetime, direction, offset, price, volume
df = pd.DataFrame()
df["direction"] = direction
df["offset"] = offset
df["price"] = price
df["volume"] = volume
df["current_time"] = dt
df["last_time"] = df["current_time"].shift(1)
# Calculate trade amount
df["amount"] = df["price"] * df["volume"]
df["acum_amount"] = df["amount"].cumsum()
# Calculate pos, net pos(with direction), acumluation pos(with direction)
def calculate_pos(df):
if df["direction"] == "多":
result = df["volume"]
else:
result = - df["volume"]
return result
df["pos"] = df.apply(calculate_pos, axis=1)
df["net_pos"] = df["pos"].cumsum()
df["acum_pos"] = df["volume"].cumsum()
# Calculate trade result, acumulation result
# ej: trade result(buy->sell) means (new price - old price) * volume
df["result"] = -1 * df["pos"] * df["price"]
df["acum_result"] = df["result"].cumsum()
# Filter column data when net pos comes to zero
def get_acum_trade_result(df):
if df["net_pos"] == 0:
return df["acum_result"]
df["acum_trade_result"] = df.apply(get_acum_trade_result, axis=1)
def get_acum_trade_volume(df):
if df["net_pos"] == 0:
return df["acum_pos"]
df["acum_trade_volume"] = df.apply(get_acum_trade_volume, axis=1)
def get_acum_trade_duration(df):
if df["net_pos"] == 0:
return df["current_time"] - df["last_time"]
df["acum_trade_duration"] = df.apply(get_acum_trade_duration, axis=1)
def get_acum_trade_amount(df):
if df["net_pos"] == 0:
return df["acum_amount"]
df["acum_trade_amount"] = df.apply(get_acum_trade_amount, axis=1)
# Select row data with net pos equil to zero
df = df.dropna()
return df
def generate_trade_df(trades, size, rate, slippage, capital):
"""
Calculate trade result from increment
"""
df = calculate_trades_result(trades)
trade_df = pd.DataFrame()
trade_df["close_direction"] = df["direction"]
trade_df["close_time"] = df["current_time"]
trade_df["close_price"] = df["price"]
trade_df["pnl"] = df["acum_trade_result"] - \
df["acum_trade_result"].shift(1).fillna(0)
trade_df["volume"] = df["acum_trade_volume"] - \
df["acum_trade_volume"].shift(1).fillna(0)
trade_df["duration"] = df["current_time"] - \
df["last_time"]
trade_df["turnover"] = df["acum_trade_amount"] - \
df["acum_trade_amount"].shift(1).fillna(0)
trade_df["commission"] = trade_df["turnover"] * rate
trade_df["slipping"] = trade_df["volume"] * size * slippage
trade_df["net_pnl"] = trade_df["pnl"] - \
trade_df["commission"] - trade_df["slipping"]
result = calculate_base_net_pnl(trade_df, capital)
return result
汇总生成资金曲线
def calculate_base_net_pnl(df, capital):
"""
Calculate statistic base on net pnl
"""
df["acum_pnl"] = df["net_pnl"].cumsum()
df["balance"] = df["acum_pnl"] + capital
df["return"] = np.log(
df["balance"] / df["balance"].shift(1)
).fillna(0)
df["highlevel"] = (
df["balance"].rolling(
min_periods=1, window=len(df), center=False).max()
)
df["drawdown"] = df["balance"] - df["highlevel"]
df["ddpercent"] = df["drawdown"] / df["highlevel"] * 100
df.reset_index(drop=True, inplace=True)
return df
统计整体策略效果
def statistics_trade_result(df, capital, show_chart=True):
""""""
end_balance = df["balance"].iloc[-1]
max_drawdown = df["drawdown"].min()
max_ddpercent = df["ddpercent"].min()
pnl_medio = df["net_pnl"].mean()
trade_count = len(df)
duration_medio = df["duration"].mean().total_seconds()/3600
commission_medio = df["commission"].mean()
slipping_medio = df["slipping"].mean()
win = df[df["net_pnl"] > 0]
win_amount = win["net_pnl"].sum()
win_pnl_medio = win["net_pnl"].mean()
win_duration_medio = win["duration"].mean().total_seconds()/3600
win_count = len(win)
loss = df[df["net_pnl"] < 0]
loss_amount = loss["net_pnl"].sum()
loss_pnl_medio = loss["net_pnl"].mean()
loss_duration_medio = loss["duration"].mean().total_seconds()/3600
loss_count = len(loss)
winning_rate = win_count / trade_count
win_loss_pnl_ratio = - win_pnl_medio / loss_pnl_medio
total_return = (end_balance / capital - 1) * 100
return_drawdown_ratio = -total_return / max_ddpercent
output(f"起始资金:\t{capital:,.2f}")
output(f"结束资金:\t{end_balance:,.2f}")
output(f"总收益率:\t{total_return:,.2f}%")
output(f"最大回撤: \t{max_drawdown:,.2f}")
output(f"百分比最大回撤: {max_ddpercent:,.2f}%")
output(f"收益回撤比:\t{return_drawdown_ratio:,.2f}")
output(f"总成交次数:\t{trade_count}")
output(f"盈利成交次数:\t{win_count}")
output(f"亏损成交次数:\t{loss_count}")
output(f"胜率:\t\t{winning_rate:,.2f}")
output(f"盈亏比:\t\t{win_loss_pnl_ratio:,.2f}")
output(f"平均每笔盈亏:\t{pnl_medio:,.2f}")
output(f"平均持仓小时:\t{duration_medio:,.2f}")
output(f"平均每笔手续费:\t{commission_medio:,.2f}")
output(f"平均每笔滑点:\t{slipping_medio:,.2f}")
output(f"总盈利金额:\t{win_amount:,.2f}")
output(f"盈利交易均值:\t{win_pnl_medio:,.2f}")
output(f"盈利持仓小时:\t{win_duration_medio:,.2f}")
output(f"总亏损金额:\t{loss_amount:,.2f}")
output(f"亏损交易均值:\t{loss_pnl_medio:,.2f}")
output(f"亏损持仓小时:\t{loss_duration_medio:,.2f}")
if not show_chart:
return
plt.figure(figsize=(10, 12))
acum_pnl_plot = plt.subplot(3, 1, 1)
acum_pnl_plot.set_title("Balance Plot")
df["balance"].plot(legend=True)
pnl_plot = plt.subplot(3, 1, 2)
pnl_plot.set_title("Pnl Per Trade")
df["net_pnl"].plot(legend=True)
distribution_plot = plt.subplot(3, 1, 3)
distribution_plot.set_title("Trade Pnl Distribution")
df["net_pnl"].hist(bins=100)
plt.show()
def output(msg):
"""
Output message with datetime.
"""
print(f"{datetime.now()}\t{msg}")
统计纯多头和纯空头交易
纯多头交易就是只有多开->空平的交易,而纯空头交易就是反过来。
为了筛选出纯多开交易,只要在DataFrame中判断其平仓方向的空的即可;纯空头交易则反过来,平仓方向为多。
def buy2sell(df, capital):
"""
Generate DataFrame with only trade from buy to sell
"""
buy2sell = df[df["close_direction"] == "空"]
result = calculate_base_net_pnl(buy2sell, capital)
return result
def short2cover(df, capital):
"""
Generate DataFrame with only trade from short to cover
"""
short2cover = df[df["close_direction"] == "多"]
result = calculate_base_net_pnl(short2cover, capital)
return result
整合所有计算步骤
最后,我们将上文中所有的函数进行整合,封装到单个函数中,用于实现策略回测效果的一键生成:
def exhaust_trade_result(
trades,
size: int = 10,
rate: float = 0.0,
slippage: float = 0.0,
capital: int = 1000000,
show_long_short_condition=True
):
"""
Exhaust all trade result.
"""
total_trades = generate_trade_df(trades, size, rate, slippage, capital)
statistics_trade_result(total_trades, capital)
if not show_long_short_condition:
return
long_trades = buy2sell(total_trades, capital)
short_trades = short2cover(total_trades, capital)
output("-----------------------")
output("纯多头交易")
statistics_trade_result(long_trades, capital)
output("-----------------------")
output("纯空头交易")
statistics_trade_result(short_trades, capital)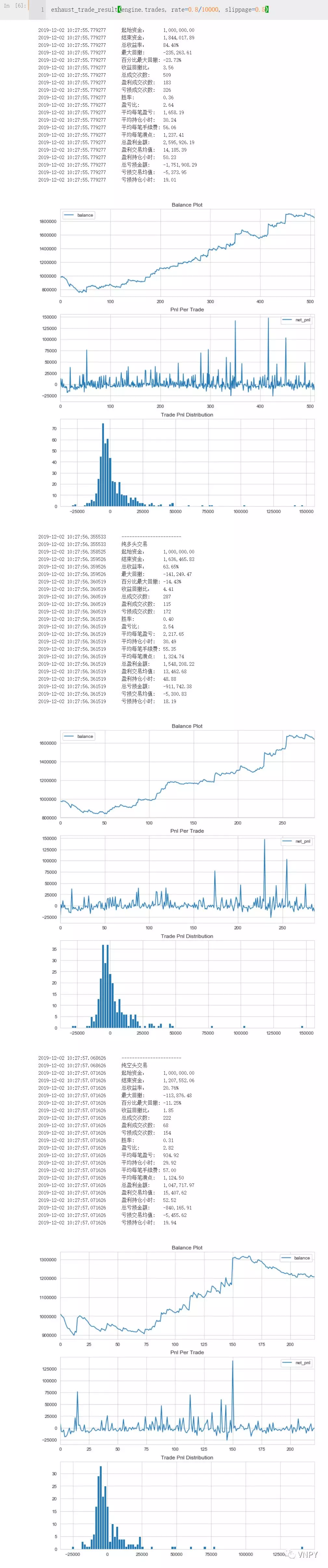
最后附上完整的源代码
import pandas as pd
from datetime import datetime
import matplotlib.pyplot as plt
import numpy as np
pd.set_option('mode.chained_assignment', None)
def calculate_trades_result(trades):
"""
Deal with trade data
"""
dt, direction, offset, price, volume = [], [], [], [], []
for i in trades.values():
dt.append(i.datetime)
direction.append(i.direction.value)
offset.append(i.offset.value)
price.append(i.price)
volume.append(i.volume)
# Generate DataFrame with datetime, direction, offset, price, volume
df = pd.DataFrame()
df["direction"] = direction
df["offset"] = offset
df["price"] = price
df["volume"] = volume
df["current_time"] = dt
df["last_time"] = df["current_time"].shift(1)
# Calculate trade amount
df["amount"] = df["price"] * df["volume"]
df["acum_amount"] = df["amount"].cumsum()
# Calculate pos, net pos(with direction), acumluation pos(with direction)
def calculate_pos(df):
if df["direction"] == "多":
result = df["volume"]
else:
result = - df["volume"]
return result
df["pos"] = df.apply(calculate_pos, axis=1)
df["net_pos"] = df["pos"].cumsum()
df["acum_pos"] = df["volume"].cumsum()
# Calculate trade result, acumulation result
# ej: trade result(buy->sell) means (new price - old price) * volume
df["result"] = -1 * df["pos"] * df["price"]
df["acum_result"] = df["result"].cumsum()
# Filter column data when net pos comes to zero
def get_acum_trade_result(df):
if df["net_pos"] == 0:
return df["acum_result"]
df["acum_trade_result"] = df.apply(get_acum_trade_result, axis=1)
def get_acum_trade_volume(df):
if df["net_pos"] == 0:
return df["acum_pos"]
df["acum_trade_volume"] = df.apply(get_acum_trade_volume, axis=1)
def get_acum_trade_duration(df):
if df["net_pos"] == 0:
return df["current_time"] - df["last_time"]
df["acum_trade_duration"] = df.apply(get_acum_trade_duration, axis=1)
def get_acum_trade_amount(df):
if df["net_pos"] == 0:
return df["acum_amount"]
df["acum_trade_amount"] = df.apply(get_acum_trade_amount, axis=1)
# Select row data with net pos equil to zero
df = df.dropna()
return df
def generate_trade_df(trades, size, rate, slippage, capital):
"""
Calculate trade result from increment
"""
df = calculate_trades_result(trades)
trade_df = pd.DataFrame()
trade_df["close_direction"] = df["direction"]
trade_df["close_time"] = df["current_time"]
trade_df["close_price"] = df["price"]
trade_df["pnl"] = df["acum_trade_result"] - \
df["acum_trade_result"].shift(1).fillna(0)
trade_df["volume"] = df["acum_trade_volume"] - \
df["acum_trade_volume"].shift(1).fillna(0)
trade_df["duration"] = df["current_time"] - \
df["last_time"]
trade_df["turnover"] = df["acum_trade_amount"] - \
df["acum_trade_amount"].shift(1).fillna(0)
trade_df["commission"] = trade_df["turnover"] * rate
trade_df["slipping"] = trade_df["volume"] * size * slippage
trade_df["net_pnl"] = trade_df["pnl"] - \
trade_df["commission"] - trade_df["slipping"]
result = calculate_base_net_pnl(trade_df, capital)
return result
def calculate_base_net_pnl(df, capital):
"""
Calculate statistic base on net pnl
"""
df["acum_pnl"] = df["net_pnl"].cumsum()
df["balance"] = df["acum_pnl"] + capital
df["return"] = np.log(
df["balance"] / df["balance"].shift(1)
).fillna(0)
df["highlevel"] = (
df["balance"].rolling(
min_periods=1, window=len(df), center=False).max()
)
df["drawdown"] = df["balance"] - df["highlevel"]
df["ddpercent"] = df["drawdown"] / df["highlevel"] * 100
df.reset_index(drop=True, inplace=True)
return df
def buy2sell(df, capital):
"""
Generate DataFrame with only trade from buy to sell
"""
buy2sell = df[df["close_direction"] == "空"]
result = calculate_base_net_pnl(buy2sell, capital)
return result
def short2cover(df, capital):
"""
Generate DataFrame with only trade from short to cover
"""
short2cover = df[df["close_direction"] == "多"]
result = calculate_base_net_pnl(short2cover, capital)
return result
def statistics_trade_result(df, capital, show_chart=True):
""""""
end_balance = df["balance"].iloc[-1]
max_drawdown = df["drawdown"].min()
max_ddpercent = df["ddpercent"].min()
pnl_medio = df["net_pnl"].mean()
trade_count = len(df)
duration_medio = df["duration"].mean().total_seconds()/3600
commission_medio = df["commission"].mean()
slipping_medio = df["slipping"].mean()
win = df[df["net_pnl"] > 0]
win_amount = win["net_pnl"].sum()
win_pnl_medio = win["net_pnl"].mean()
win_duration_medio = win["duration"].mean().total_seconds()/3600
win_count = len(win)
loss = df[df["net_pnl"] < 0]
loss_amount = loss["net_pnl"].sum()
loss_pnl_medio = loss["net_pnl"].mean()
loss_duration_medio = loss["duration"].mean().total_seconds()/3600
loss_count = len(loss)
winning_rate = win_count / trade_count
win_loss_pnl_ratio = - win_pnl_medio / loss_pnl_medio
total_return = (end_balance / capital - 1) * 100
return_drawdown_ratio = -total_return / max_ddpercent
output(f"起始资金:\t{capital:,.2f}")
output(f"结束资金:\t{end_balance:,.2f}")
output(f"总收益率:\t{total_return:,.2f}%")
output(f"最大回撤: \t{max_drawdown:,.2f}")
output(f"百分比最大回撤: {max_ddpercent:,.2f}%")
output(f"收益回撤比:\t{return_drawdown_ratio:,.2f}")
output(f"总成交次数:\t{trade_count}")
output(f"盈利成交次数:\t{win_count}")
output(f"亏损成交次数:\t{loss_count}")
output(f"胜率:\t\t{winning_rate:,.2f}")
output(f"盈亏比:\t\t{win_loss_pnl_ratio:,.2f}")
output(f"平均每笔盈亏:\t{pnl_medio:,.2f}")
output(f"平均持仓小时:\t{duration_medio:,.2f}")
output(f"平均每笔手续费:\t{commission_medio:,.2f}")
output(f"平均每笔滑点:\t{slipping_medio:,.2f}")
output(f"总盈利金额:\t{win_amount:,.2f}")
output(f"盈利交易均值:\t{win_pnl_medio:,.2f}")
output(f"盈利持仓小时:\t{win_duration_medio:,.2f}")
output(f"总亏损金额:\t{loss_amount:,.2f}")
output(f"亏损交易均值:\t{loss_pnl_medio:,.2f}")
output(f"亏损持仓小时:\t{loss_duration_medio:,.2f}")
if not show_chart:
return
plt.figure(figsize=(10, 12))
acum_pnl_plot = plt.subplot(3, 1, 1)
acum_pnl_plot.set_title("Balance Plot")
df["balance"].plot(legend=True)
pnl_plot = plt.subplot(3, 1, 2)
pnl_plot.set_title("Pnl Per Trade")
df["net_pnl"].plot(legend=True)
distribution_plot = plt.subplot(3, 1, 3)
distribution_plot.set_title("Trade Pnl Distribution")
df["net_pnl"].hist(bins=100)
plt.show()
def output(msg):
"""
Output message with datetime.
"""
print(f"{datetime.now()}\t{msg}")
def exhaust_trade_result(
trades,
size: int = 10,
rate: float = 0.0,
slippage: float = 0.0,
capital: int = 1000000,
show_long_short_condition=True
):
"""
Exhaust all trade result.
"""
total_trades = generate_trade_df(trades, size, rate, slippage, capital)
statistics_trade_result(total_trades, capital)
if not show_long_short_condition:
return
long_trades = buy2sell(total_trades, capital)
short_trades = short2cover(total_trades, capital)
output("-----------------------")
output("纯多头交易")
statistics_trade_result(long_trades, capital)
output("-----------------------")
output("纯空头交易")
statistics_trade_result(short_trades, capital)
了解更多知识,请关注vn.py社区公众号。

建议对坐标进行限制,优化曲线移动时候体验。(有时候,移动过大导致找不到隐含波动率曲线)

如
在【隐含波动率曲线】,鼠标右键点击【export】出现报错, 显示无法import QtSvg
在实盘交易中,逐日盯市(Marking-to-Market)是基于当日的收盘价、仓位数据、成交数据等来统计每日的盈亏,用于交易所对于客户盈亏情况的每日清算以及保证金管理。
在策略回测中,逐日盯市统计的算法也可以用于对策略盈亏曲线的计算和绘制。一个好的策略,资金曲线总是整体向上,并且相对平滑无太大回撤的,换句话说,就是夏普比率和收益回撤比都比较高。2.0版本的vn.py框架的CTA回测引擎,为了更直观的评估策略的整体效果,内置的盈亏统计采用了逐日盯市的模式。
但因为将每日所有的成交数据都映射到了最终收盘时的结果,逐日盯市统计的方式,无法在每笔开平仓交易的层面来分析盈亏情况,例如:手续费和滑点相对平均盈亏的占比、策略交易胜率和盈亏比等统计指标。
考虑到以上信息对于策略开发和研究的重要性,在本文中我们设计了一种新的逐笔开平对冲算法,来解决相关回测统计指标计算的问题。
在讲解代码前,先通过例子来简单介绍一下逐笔对冲统计这个概念:
上面的例子中可以知道该笔开平仓赚了12元,在实际成交中我们还需要考虑手续费和滑点:
计算完每笔交易的手续费和滑点后,我们就可以最终得到该笔开平仓交易的净盈亏情况。除了最简单的一开一平外,现实中许多策略的开平交易情况可能复杂得多,总体上可以分为:
计算完逐笔开平仓盈亏后,我们就可以统计每次交易的胜率和盈亏比了,更进一步还可以对交易方向进行筛选,来看看纯多头交易和纯空头交易的盈亏情况。
以下是vn.py中CTA回测引擎缓存回测成交信息的代码:
# Push trade update
self.trade_count += 1
if long_cross:
trade_price = min(order.price, long_best_price)
pos_change = order.volume
else:
trade_price = max(order.price, short_best_price)
pos_change = -order.volume
trade = TradeData(
symbol=order.symbol,
exchange=order.exchange,
orderid=order.orderid,
tradeid=str(self.trade_count),
direction=order.direction,
offset=order.offset,
price=trade_price,
volume=order.volume,
time=self.datetime.strftime("%H:%M:%S"),
gateway_name=self.gateway_name,
)
trade.datetime = self.datetime
self.strategy.pos += pos_change
self.strategy.on_trade(trade)
self.trades[trade.vt_tradeid] = trade
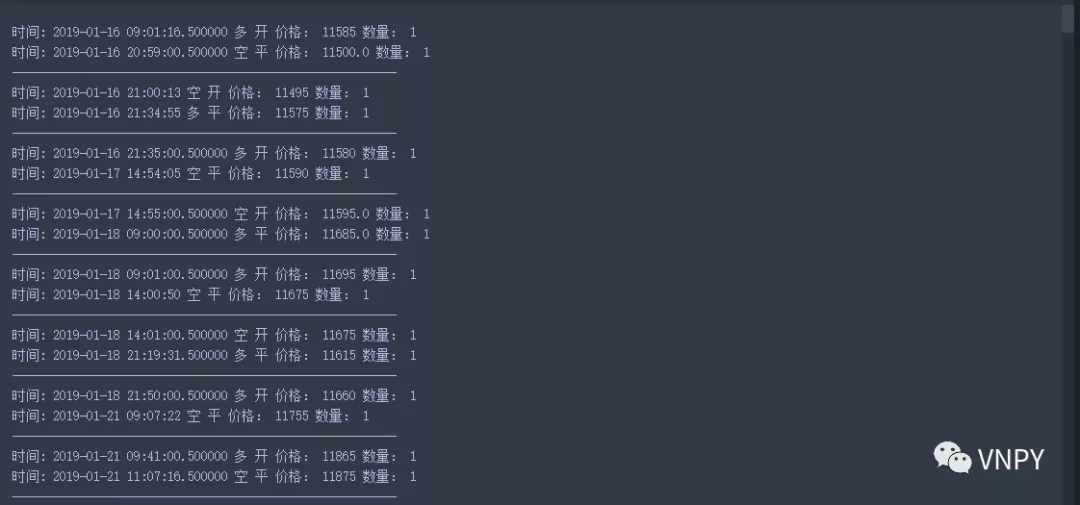
每一笔成交信息都以TradeData的数据格式缓存在trades字典中,我们可以通过打印输出该字典来直观地看看TradeData的数据结构。
对成交缓存数据的结构有个大概的了解后,接下来遍历engine.trades的值,依次打印:
在遍历过程中,若检测到是平仓操作,即value.offset.value == "平”,则另外打印分隔线,便于肉眼观察每笔开平仓所对应的时间、价格等:
trade = engine.trades
for value in trade.values():
print("时间:",value.datetime,value.direction.value,value.offset.value, "价格:",value.price, "数量:",value.volume)
if value.offset.value == "平":
print("---------------------------------------------------------")

尽管只是在Jupyter Notebook中简单的进行打印输出,已经能够一目了然的看到每次开平仓交易的基本信息。
其中的回测价格信息可以对照实盘成交回报信息进行对比,去计算真实成交和回测成交的价差,统计真实滑点,每隔一段时间(如一个月后)对回测中用到的滑点参数进行调整,力求回测尽量与实盘交易一致。
这里我们从简单的情况开始着手,首先做出假设条件:
由于不需要考虑较为复杂的一次委托多次成交情况,每次开仓成交后的下一笔必定是成交量相等的平仓成交,那么可以设计出如下的计算逻辑:
1.构建原始成交数据DataFrame,其中包括:日期时间、成交方向、开平仓、价格、数量;
2.把【价格】列表向后平移一个单位,得到上一笔成交记录;
a)若【成交方向】、【开平仓】为“多平”,意味着本次交易为空开->多平,那么盈亏=(开仓价格-平仓价格)* 成交数量;持仓时间=平仓时间-开仓时间;
b)若【成交方向】、【开平仓】为“空平”,意味着本次交易为多开->空平,那么盈亏=(平仓价格-开仓价格)* 成交数量;持仓时间=平仓时间-开仓时间;
4.对最后一行进行额外处理:若【开平】为“开”,【平仓价】和【持仓时间】设置为"待定",【盈亏】设为0;
5.使用dropna把【盈亏】为空值的行去掉;
6.对DataFrame的索引重新排序;
7.计算【累计盈亏】并画出图。
同时在实盘交易中做每日收盘后的统计时,我们可以设置DataFrame只显示当月的成交记录,便于重点观察最近一段时间的盈亏情况、持仓时间等:
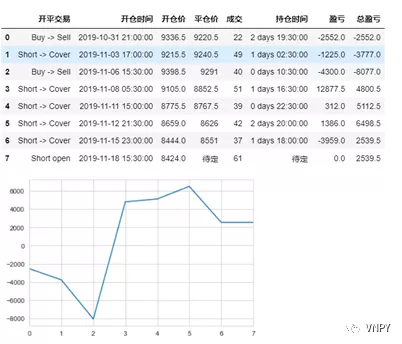
上图中,我们可以一目了然地看出每一组完整的开平仓交易的最终盈亏以及持仓时间。
搞定了简单的情况,接下来我们可以将算法变得更加通用化,满足更多场景:一次开仓多次平仓、多次开仓一次平仓以及更加复杂的多次开仓多次平仓。
了解更多知识,请关注vn.py社区公众号。

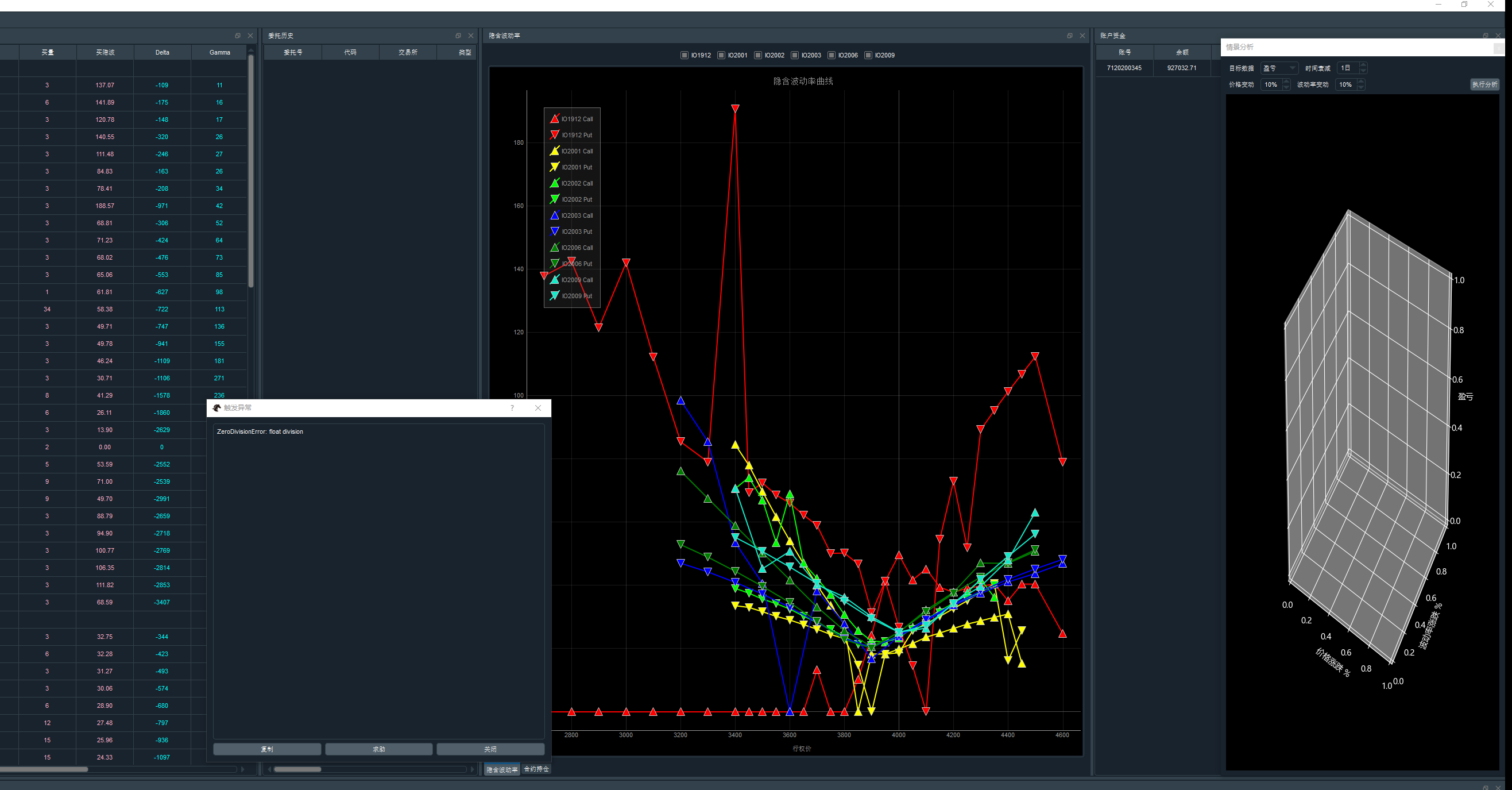
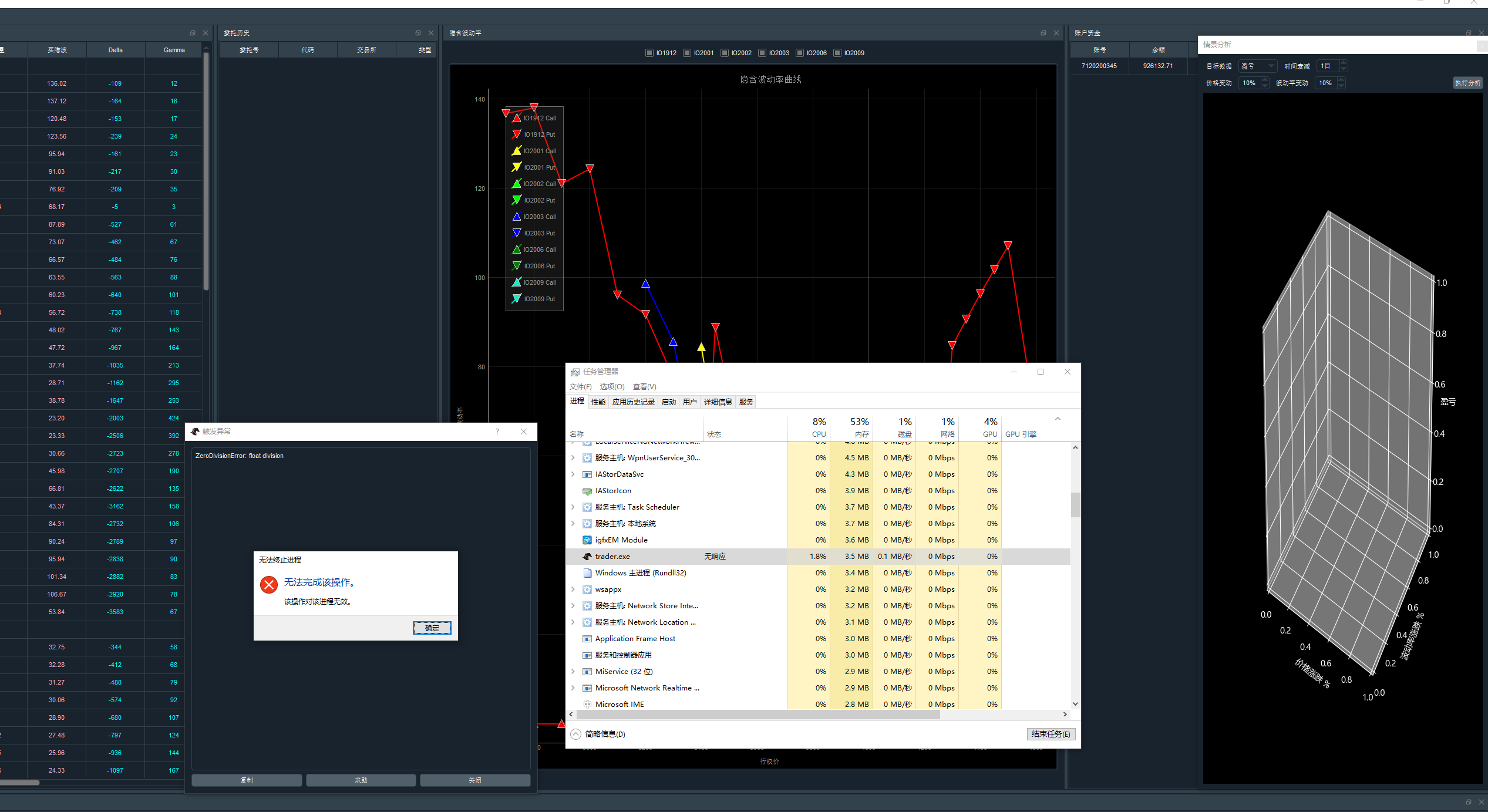
登陆Option Master后,
1) 选择中金所的IO期权 并且与当月IF股指期货作为对冲。
2) 其他组件均正常显示,除了【场景分析】不显示3D图。点击【执行分析】后,报错:Zero Division Error:Float DIvision
3) 报错出现后,有时候window后台无法关闭进程,显示的是【无响应】
4)但是Option Master能正常订阅行情并且波动率曲线微笑能跟着变化
作为量化开源框架,vn.py的一大好处在于自由度高,用户可以基于开放的源代码来专门实现自己特定的功能。对于常用的量化系统配置,VN Trader提供了全局配置工具方便用户直接在图形界面上进行修改。
进入VN Trader后,点击菜单栏上的【配置】按钮弹出【全局配置】窗口:
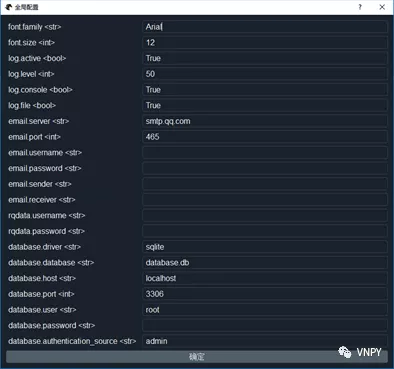
尽管参数看着挺多,但总体上可以分成以下5大类:
下面我们来对这5大类的配置进行详细说明。
font.size:设置VN Trader整体字体大小,需要根据自己显示器的实际分辨率效果进行修改,如下图中的15号字体。
日志输出
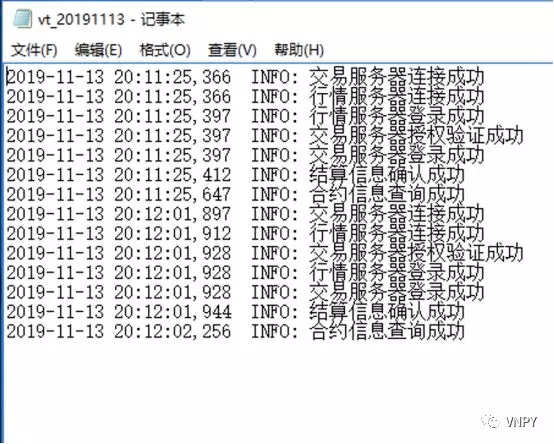
VN Trader的日志文件,默认位于运行时目录的.vntrader\log目录下,完整路径为:
C:\users\administrator.vntrader\log
其中administrator为当前Windows系统的登录用户名。
综合来说,如果想要记录更多的VN Trader系统运行细节信息,建议将level等级调低获取更多的信息,下面是开启Log.console和Log.File后的效果:
日志文件则会根据启动VN Trader时的日期自动创建:
每天盘中自动化交易时,我们可能希望每有委托成交,能够收到实时的通知;或者若出现异常情况,如数据错误、连接断开等,也要通知一下。
vn.py内置了邮件引擎EmailEngine,只要进配置好邮箱的账号、密码、服务器等信息,后续即可调用MainEngine.send_email函数来非常方便的发送邮件通知。
在这里我们通过QQ邮箱进行演示:

得到授权码后,回到VN Trader的邮件相关的配置:
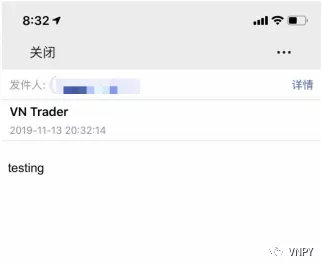
配置完成后,重启VN Trader,点击菜单栏【帮助】->【测试邮件】发送测试邮件,若能顺利收到,则说明邮件设置成功。
比起在手机上装邮箱客户端,使用微信来接受实时的消息通知,无疑要方便得多,而且只需要准备一个QQ邮箱:
最后将VN Trader的全局配置中email.receiver改成该QQ号对应的QQ邮箱即可实施在手机端接收vn.py监控消息了。
RQData是目前国内期货和股票数据方面,性价较高的三方数据提供商之一。购买RQData后(或者申请试用账号),会获得了其license文件,只需将其中的内容填入以下字段即可:
rqdata.password:RQData的license。
(注意这里的username和password不是米筐官网登录用的账号和密码!)
vn.py目前支持4个常用数据库:
其中SQLite为vn.py的默认数据库,它的优势主要表现在2点:
当然,其他数据库在特定的场景下也都有着自己的优势,如:更快的加载速度、支持多用户同时访问等。改为使用其他数据库,首先需要准备完该数据库的服务器以及图形客户端,然后在VN Trader全局配置进行相关的全局配置。
vn.py默认数据库,不需要修改任何配置。在第一次启动VN Trader时,程序会自动在用户目录下的.vntrader文件夹中生成database.db文件,后续所有相关的历史行情数据都会放在该文件中。
基础的配置只需要配置连接的数据库名称、主机名和端口号,至于用户登录信息和授权信息,可以留空。

和MySQL配置几乎一模一样,只需要将端口database.port改为5432:
2019年vn.py核心团队的最后一期小班课报名进行中!
两天共计10小时的密集提高课程
8套高端CTA策略源代码分享
DoubleChannel
KeltnerBandit
RsiMomentum
SuperTurtle
TrendThrust
Cinco
Cuatro
SuperCombo
动态风险仓位管理模型
策略内嵌复杂算法交易
详情请戳:第四期vn.py小班课上线:CTA策略开发!
了解更多知识,请关注vn.py社区公众号。

基于物理上的限制,各CPU厂商在核心频率上的比赛已经被多核所取代。为了更有效的利用多核处理器的性能,多线程的编程方式被越来越多地应用到了各类程序中,而随之带来的则是线程间数据一致性和状态同步的困难。
作为已经30岁的Python,自然早已支持多线程的功能,但坊间却始终存在着一种误解:Python的多线程是假的(或者虚拟机模拟的)。
Python虚拟机(或者叫解释器)使用了引用计数法的垃圾回收方式(另一种是以Java虚拟机为例的根搜索算法),这种垃圾回收方式使得Python虚拟机在运行多线程程序时,需要使用一把名为GIL(Global Interpreter Lock,全局解释器锁)的超级大锁,来保证每个对象上的引用计数正确。
从操作系统来看,每个CPU在同一时间都能够且只能执行一个线程。而在Python虚拟机上,任何一个线程的运行,都需要包含以下三个步骤:
因此,某个线程想要执行,必须先拿到GIL,我们可以把GIL看作是“通行证”,并且在一个Python进程中GIL也只有一个。所以哪怕硬件上CPU有再多的核心,任意时刻都只能有一个线程能拿到GIL来执行,这也是之前提到的误解来源。
Python多线程的痛点在于每次释放GIL锁,线程进行锁竞争、切换线程,会消耗资源。这导致很多时候,尤其是计算密集型任务为主的程序,多核多线程比单核多线程更差:
因此,在Python中想要充分压榨多核CPU的性能,必须依赖多进程的模式。每个进程有各自独立的GIL,互不干扰,这样就可以真正意义上的并行执行。
Python语言中内置了专门用于实现多进程的multiprocessing库,使用上相当傻瓜,通过multiprocessing.Process类来创建一个新的子进程对象,再启动这个对象,这样一个多进程任务就开始执行了。
等CPU分配一个独立核心去干活,func函数就在这个子进程中开始执行了,这里唯一要注意args是默认输入元组参数。
p = multiprocessing.Process(target=func, args=(a,))
p.start()除了一个一个的启动子进程外,也可以使用multiprocessing.Pool来创建进程池对象,把需要干的工作任务打包好,放在这个池子里面,这样一个任务执行完CPU核心空闲下来后,就能自动从进程池中去获取一个新的任务继续干活。
基本的使用步骤如下:
多进程参数优化
学习多进程模块怎么用,最好的例子之一就是vn.py的CTA策略回测引擎中的参数优化功能,加载同样的历史数据基于不同的参数,执行历史数据回放和策略盈亏统计,属于典型的多进程应用场景。
多进程优化函数位于:
vnpy.app.cta_strategy.backtesting.BacktestingEngine.run_optimization
该函数中的执行步骤如下:
def run_optimization(self, optimization_setting: OptimizationSetting, output=True):
""""""
# Get optimization setting and target
settings = optimization_setting.generate_setting()
target_name = optimization_setting.target_name
if not settings:
self.output("优化参数组合为空,请检查")
return
if not target_name:
self.output("优化目标未设置,请检查")
return
# Use multiprocessing pool for running backtesting with different setting
pool = multiprocessing.Pool(multiprocessing.cpu_count())
results = []
for setting in settings:
result = (pool.apply_async(optimize, (
target_name,
self.strategy_class,
setting,
self.vt_symbol,
self.interval,
self.start,
self.rate,
self.slippage,
self.size,
self.pricetick,
self.capital,
self.end,
self.mode
)))
results.append(result)
pool.close()
pool.join()
# Sort results and output
result_values = [result.get() for result in results]
result_values.sort(reverse=True, key=lambda result: result[1])
if output:
for value in result_values:
msg = f"参数:{value[0]}, 目标:{value[1]}"
self.output(msg)
return result_values
启动多进程优化的任务后,打开Windows的任务管理器,可以看到此时CPU所有的8个核心都已经在满载运行了。
2019年vn.py核心团队的最后一期小班课开始报名:
两天共计10小时的密集提高课程
8套高端CTA策略源代码分享
DoubleChannel
KeltnerBandit
RsiMomentum
SuperTurtle
TrendThrust
Cinco
Cuatro
SuperCombo
动态风险仓位管理模型
策略内嵌复杂算法交易
详情请戳:第四期vn.py小班课上线:CTA策略开发!
了解更多知识,请关注vn.py社区公众号。

策略开发离不开数据分析:
从另一角度来说,CTA策略开发前的建模分析流程如下:
第1步:对行情数据进行画图
首先,调用vn.py数据库模块的database_manager.load_bar_data函数从数据库载入数据到内存中。
load_bar_data函数的输入参数有5个:
load_bar_data函数输出的是一个包含系列BarData格式行情数据的列表bars。
from vnpy.trader.database import database_manager
output("开始加载历史数据")
bars = database_manager.load_bar_data(
symbol=symbol,
exchange=exchange,
interval=interval,
start=start,
end=end,
)
output(f"历史数据加载完成,数据量:{len(bars)}")
def output(msg):
""""""
print(f"{datetime.now()}\t{msg}")
用for循环读取bars列表中的BarData数据,然后分别缓存时间、开盘价、最高价、最低价、收盘价到专门的列表中,最终合成DataFrame, 设置DataFrame索引为K线数据的时间。
# Generate history data in DataFrame
t = []
o = []
h = []
l = []
c = []
for bar in bars:
time = bar.datetime
open_price = bar.open_price
high_price = bar.high_price
low_price = bar.low_price
close_price = bar.close_price
t.append(time)
o.append(open_price)
h.append(high_price)
l.append(low_price)
c.append(close_price)
self.orignal = pd.DataFrame()
self.orignal["open"] = o
self.orignal["high"] = h
self.orignal["low"] = l
self.orignal["close"] = c
self.orignal.index = t
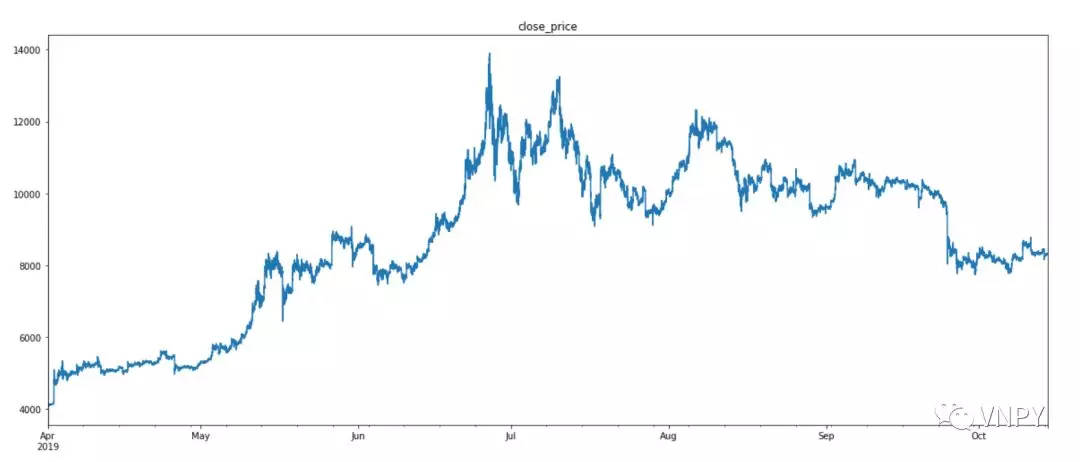
对收盘价进行画图,设置图的尺寸和标题。然后用肉眼初步确认时间序列图无数据缺失或者明显“异常”行情。
output("第一步:画出行情图,检查数据断点")
self.orignal["close"].plot(figsize=(20, 8), title="close_price")
plt.show()
第2步:随机性检验
调用statsmodels库的acorr_ljungbox函数,对收盘价进行白噪声检验,函数返回一个p值,p值越大表示原假设成立的可能性越大,即数据是随机的可能性越大。
一般p值与0.05进行对比:
from statsmodels.stats.diagnostic import acorr_ljungbox
def random_test(close_price):
"""
白噪声检验
"""
acorr_result = acorr_ljungbox(close_price, lags=1)
p_value = acorr_result[1]
if p_value < 0.05:
output("第二步:随机性检验:非纯随机性")
else:
output("第二步:随机性检验:纯随机性")
output(f"白噪声检验结果:{acorr_result}\n")

第3步:平稳性检验
同样,调用statsmodels库的adfuller函数对收盘价进行单位根检验,函数返回的是一个字典,我们对字典里面的字段进行判断:
CTA策略研究的是非平稳性时间序列,平稳时间序列适用于期货价差的统计套利。
from statsmodels.tsa.stattools import adfuller as ADF
def stability_test(close_price):
"""
平稳性检验
"""
statitstic = ADF(close_price)
t_s = statitstic[1]
t_c = statitstic[4]["10%"]
if t_s > t_c:
output("第三步:平稳性检验:存在单位根,时间序列不平稳")
else:
output("第三步:平稳性检验:不存在单位根,时间序列平稳")
output(f"ADF检验结果:{statitstic}\n")

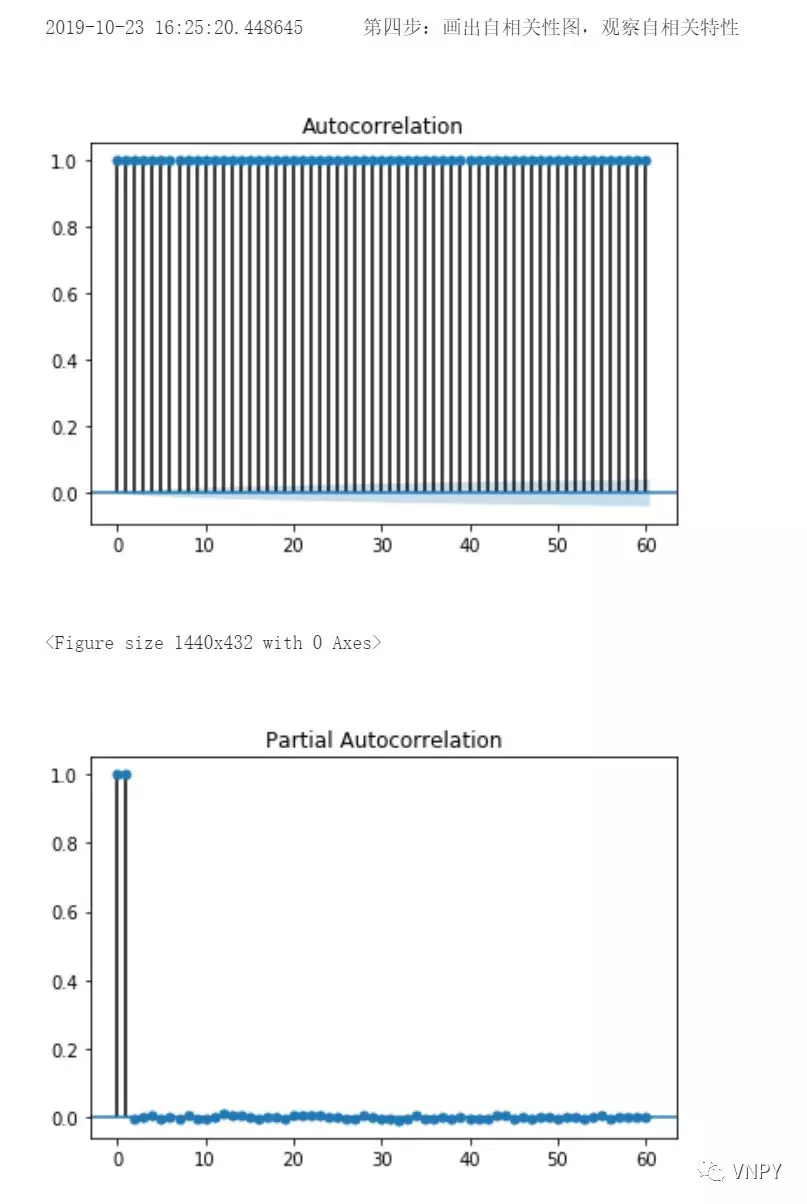
第4步:画出自相关图
同样,调用statsmodels库的plot_acf函数和plot_pacf函数对收盘价画自相关和偏自相关图:
置信区间被画成圆锥形。默认情况下,置信区间被设置为95%,这表明,圆锥之外的值很可能是相关的,而不是统计上的意外。
也就是说,圆锥以外的值越多,时间序列自相关性越强,越适用于研究CTA策略。
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
def autocorrelation_test(close_price):
"""
自相关性检验
"""
output("第四步:画出自相关性图,观察自相关特性")
plot_acf(close_price, lags=60)
plt.show()
plot_pacf(close_price, lags=60).show()
plt.show()
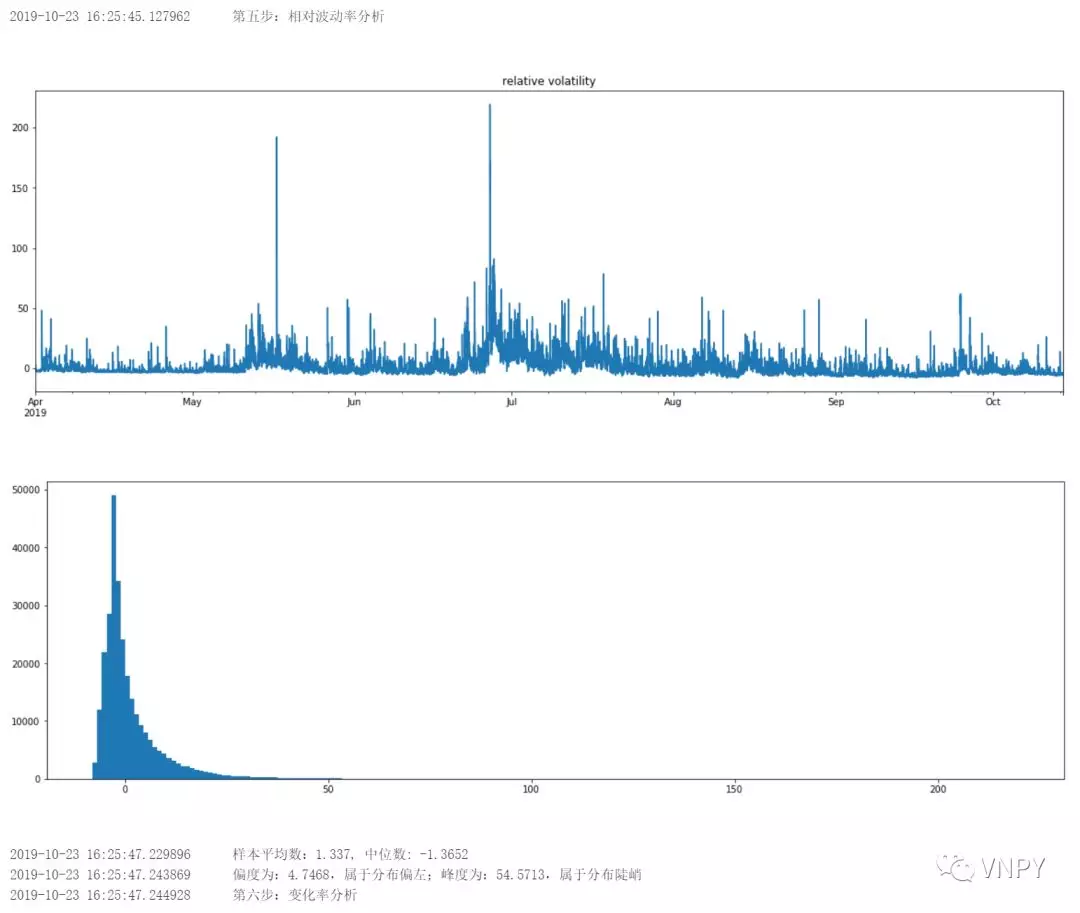
第5步:相对波动率分析
若相对波动率分布属于右偏(肥尾在右边),且分布陡峭,在统计学上具有尖峰肥尾的特色,适用于研究CTA策略。
def relative_volatility_analysis(self, df: DataFrame = None):
"""
相对波动率
"""
output("第五步:相对波动率分析")
df["volatility"] = talib.ATR(
np.array(df['high']),
np.array(df['low']),
np.array(df['close']),
self.window_volatility
)
df["fixed_cost"] = df["close"] * self.rate
df["relative_vol"] = df["volatility"] - df["fixed_cost"]
df["relative_vol"].plot(figsize=(20, 6), title="relative volatility")
plt.show()
df["relative_vol"].hist(bins=200, figsize=(20, 6), grid=False)
plt.show()
statitstic_info(df["relative_vol"])
def statitstic_info(df):
"""
描述统计信息
"""
mean = round(df.mean(), 4)
median = round(df.median(), 4)
output(f"样本平均数:{mean}, 中位数: {median}")
skew = round(df.skew(), 4)
kurt = round(df.kurt(), 4)
if skew == 0:
skew_attribute = "对称分布"
elif skew > 0:
skew_attribute = "分布偏左"
else:
skew_attribute = "分布偏右"
if kurt == 0:
kurt_attribute = "正态分布"
elif kurt > 0:
kurt_attribute = "分布陡峭"
else:
kurt_attribute = "分布平缓"
output(f"偏度为:{skew},属于{skew_attribute};峰度为:{kurt},属于{kur
t_attribute}
\n")
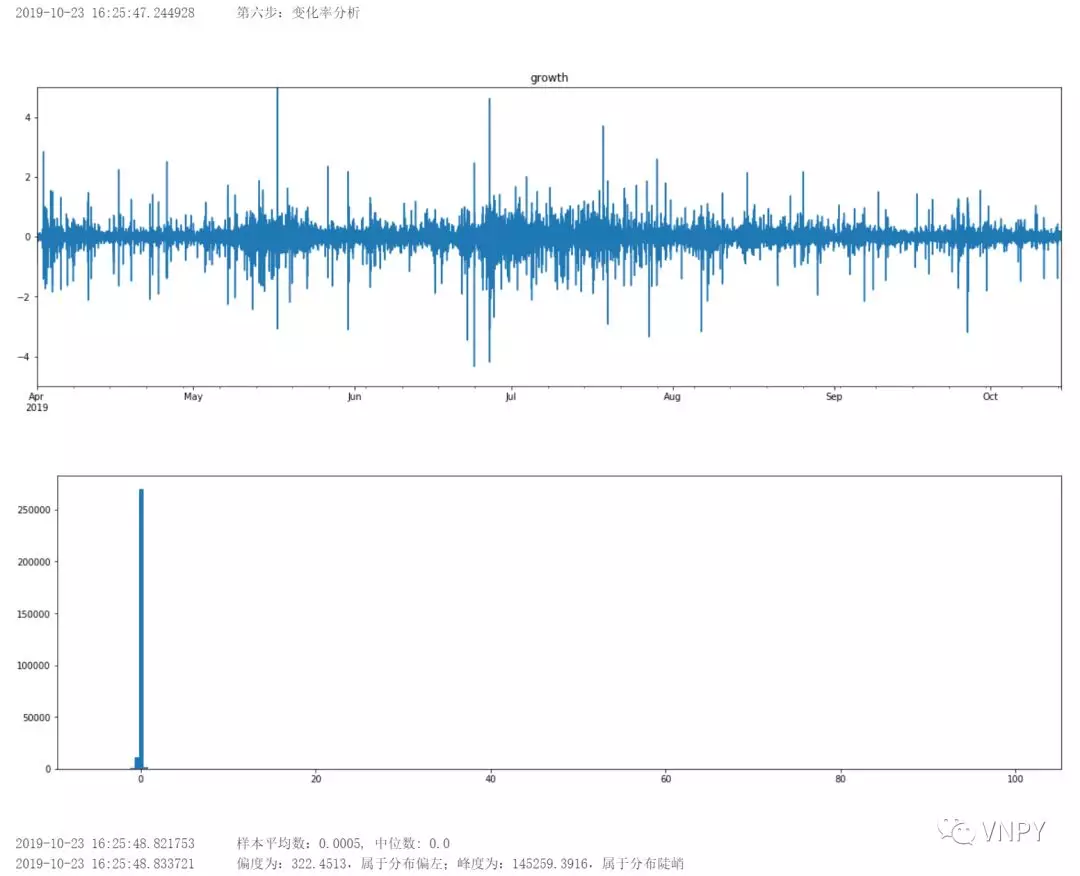
第6步:变化率分析
def growth_analysis(self, df: DataFrame = None):
"""
百分比K线变化率
"""
output("第六步:变化率分析")
df["pre_close"] = df["close"].shift(1).fillna(0)
df["g%"] = 100 * (df["close"] - df["pre_close"]) / df["close"]
df["g%"].plot(figsize=(20, 6), title="growth", ylim=(-5, 5))
plt.show()
df["g%"].hist(bins=200, figsize=(20, 6), grid=False)
plt.show()
statitstic_info(df["g%"])
想了解更多关于CTA策略开发实战的各种细节?请戳课程上线:《vn.py全实战进阶》!目前课程已经更新过半,一共50节内容覆盖从策略设计开发、参数回测优化,到最终实盘自动交易的完整CTA量化业务流程。
了解更多知识,请关注vn.py社区公众号。

R-Breaker是一种中高频的日内交易策略,这个策略也长期被Future Truth杂志评为最赚钱的策略之一。
R-Breaker策略结合了趋势和反转两种交易方式,所以交易机会相对较多,比较适合日内1分钟K线或者5分钟K线级别的数据。
R-Breaker策略的核心逻辑由以下4部分构成:
1)计算6个目标价位
根据昨日的开高低收价位计算出今日的6个目标价位,按照价格高低依次是:
具体计算方法如下:(其中a、b、c、d为策略参数)
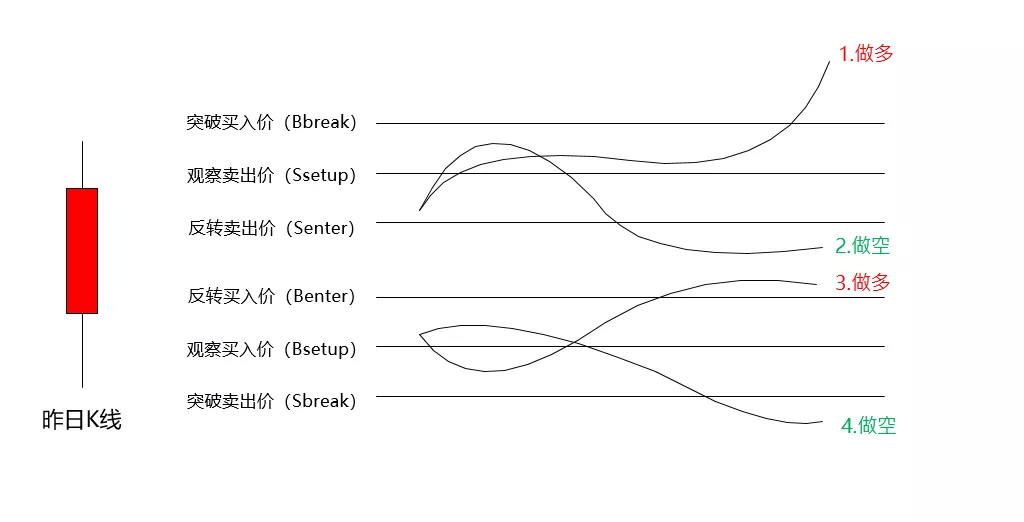
2)设计委托逻辑
趋势策略交易:
反转策略交易:
3)设定相应的止盈止损
4)日内策略要求收盘前平仓
以上是原版R-Breaker策略逻辑,但使用RQData从2010年至今(2019年10月)的1分钟沪深300股指期货主力连续合约(IF88)测试,效果并不理想。
从逻辑上看R-Breaker策略可以拆分成趋势策略和反转策略,那么不妨试试将这两种逻辑分开,并逐个进行优化。
1)趋势策略:
若当前x分钟的最高价>观察卖出价,认为它具有上升趋势,在突破买入价挂上买入开仓的停止单;
其代码实现逻辑如下:
self.tend_high, self.tend_low = am.donchian(self.donchian_window)
if bar.datetime.time() < self.exit_time:
if self.pos == 0:
self.intra_trade_low = bar.low_price
self.intra_trade_high = bar.high_price
if self.tend_high > self.sell_setup:
long_entry = max(self.buy_break, self.day_high)
self.buy(long_entry, self.fixed_size, stop=True)
self.short(self.sell_enter, self.multiplier * self.fixed_size, stop=True)
elif self.tend_low < self.buy_setup:
short_entry = min(self.sell_break, self.day_low)
self.short(short_entry, self.fixed_size, stop=True)
self.buy(self.buy_enter, self.multiplier * self.fixed_size, stop=True)
elif self.pos > 0:
self.intra_trade_high = max(self.intra_trade_high, bar.high_price)
long_stop = self.intra_trade_high * (1 - self.trailing_long / 100)
self.sell(long_stop, abs(self.pos), stop=True)
elif self.pos < 0:
self.intra_trade_low = min(self.intra_trade_low, bar.low_price)
short_stop = self.intra_trade_low * (1 + self.trailing_short / 100)
self.cover(short_stop, abs(self.pos), stop=True)
# Close existing position
else:
if self.pos > 0:
self.sell(bar.close_price * 0.99, abs(self.pos))
elif self.pos < 0:
self.cover(bar.close_price * 1.01, abs(self.pos))
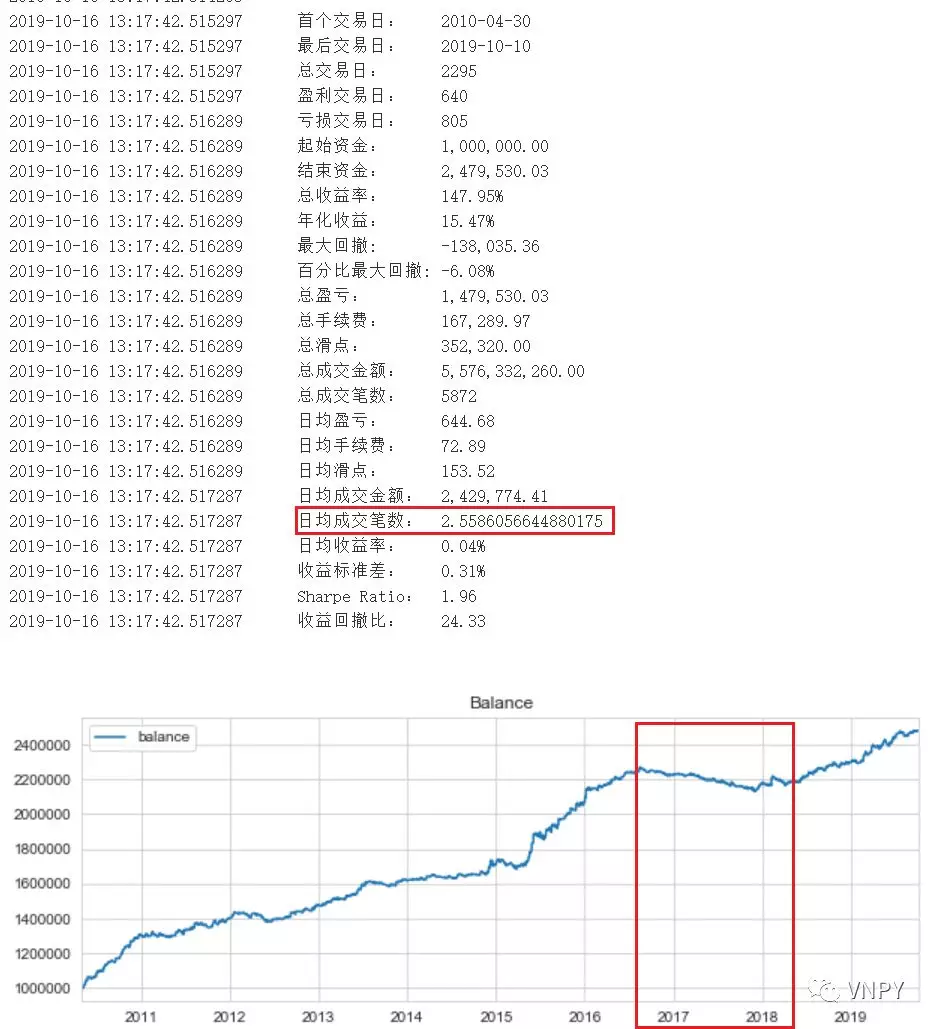
同样使用2010年至今的1分钟IF88数据进行回测。不过在展示强化版R-Breaker策略效果前,先分别展示一下拆分后的趋势策略和反转策略。
1)趋势策略:
2)反转策略
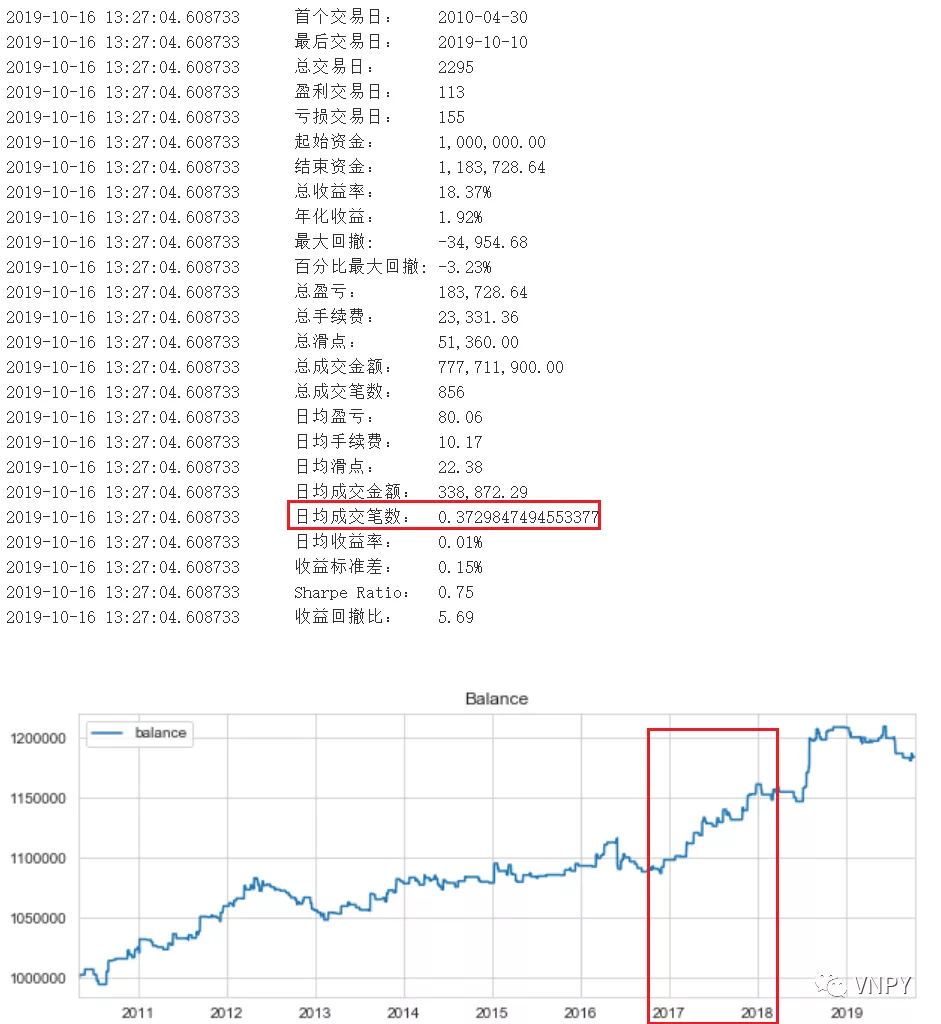
综合对比2种策略的日均成交笔数和资金曲线,我们可以知道:
由于趋势策略和反转策略是互斥的,在某些方面呈现出此消彼长的特点。那么,根据投资组合理论,可以把反转策略看作是看跌期权,买入一定规模的看跌期权来对消非系统性风险,那么组合的收益会更加稳健,即夏普比率更高。
由于趋势策略和反转策略日均成交手数比是2.6:0.4,若它们都只委托1手的话,反转策略的对冲效果微乎其微。
为了方便演示,我们设置趋势策略每次交易1手,反转策略则是3手,然后将两者合成为R-Breaker策略。
经过以上的仓位配置后,回测结果中的夏普比率提高到2,资金曲线整体上扬,而且没有较大且持续时间较长的回撤。
R-Breaker策略的成功之处在于它并不是纯粹的趋势类策略,而是属于复合型策略,其alpha由两部分构成:趋势策略alpha和反转策略alpha。
这类复合型策略可以看作是轻量级的投资组合,因为它的交易标的只有一个:沪深300股指期货的主力合约。
更复杂的话,可以交易多个标的,如在商品期货做虚拟钢厂套利(同时交易螺纹钢、铁矿石、焦炭),在IF股指期货上做日内CTA策略。考虑到市场容量不同,价差套利能分配更多的资金,这样在价差套利提供稳定收益率基础上,CTA策略能在行情好的时候贡献更多alpha(高盈亏比特征导致的)。
从上面的例子可以看出,一个合理的投资组合,往往比单个策略具有更高的夏普比率。因为:夏普比率=超额收益/风险,所以夏普比率高意味着资金曲线非常平滑,也意味着我们可以有效的控制使用杠杆的风险。
当某个投资组合策略夏普足够高,而且策略资金容量允许,交易成本能有效控制等情况下,就可以通过杠杆来提升组合收益了。例如采用结构化产品的形式,经过银行等中介通过发行优先级份额,来为劣后级份额提供杠杆。这时劣后级投资者(有时100%是交易团队自身持有)同时也是债务人的角色,即在承担更大风险的同时,追求更高的最终收益,而优先级投资者则作为债权人享受利息收益。
最后,秉承vn.py社区的一贯精神:
Talk is cheap, show me your pnl (or code) !
自然必须附上策略的源代码:
from datetime import time
from vnpy.app.cta_strategy import (
CtaTemplate,
StopOrder,
TickData,
BarData,
TradeData,
OrderData,
BarGenerator,
ArrayManager
)
class RBreakStrategy(CtaTemplate):
""""""
author = "KeKe"
setup_coef = 0.25
break_coef = 0.2
enter_coef_1 = 1.07
enter_coef_2 = 0.07
fixed_size = 1
donchian_window = 30
trailing_long = 0.4
trailing_short = 0.4
multiplier = 3
buy_break = 0 # 突破买入价
sell_setup = 0 # 观察卖出价
sell_enter = 0 # 反转卖出价
buy_enter = 0 # 反转买入价
buy_setup = 0 # 观察买入价
sell_break = 0 # 突破卖出价
intra_trade_high = 0
intra_trade_low = 0
day_high = 0
day_open = 0
day_close = 0
day_low = 0
tend_high = 0
tend_low = 0
exit_time = time(hour=14, minute=55)
parameters = ["setup_coef", "break_coef", "enter_coef_1", "enter_coef_2", "fixed_size", "donchian_window"]
variables = ["buy_break", "sell_setup", "sell_enter", "buy_enter", "buy_setup", "sell_break"]
def __init__(self, cta_engine, strategy_name, vt_symbol, setting):
""""""
super().__init__(cta_engine, strategy_name, vt_symbol, setting )
self.bg = BarGenerator(self.on_bar)
self.am = ArrayManager()
self.bars = []
def on_init(self):
"""
Callback when strategy is inited.
"""
self.write_log("策略初始化")
self.load_bar(10)
def on_start(self):
"""
Callback when strategy is started.
"""
self.write_log("策略启动")
def on_stop(self):
"""
Callback when strategy is stopped.
"""
self.write_log("策略停止")
def on_tick(self, tick: TickData):
"""
Callback of new tick data update.
"""
self.bg.update_tick(tick)
def on_bar(self, bar: BarData):
"""
Callback of new bar data update.
"""
self.cancel_all()
am = self.am
am.update_bar(bar)
if not am.inited:
return
self.bars.append(bar)
if len(self.bars) <= 2:
return
else:
self.bars.pop(0)
last_bar = self.bars[-2]
# New Day
if last_bar.datetime.date() != bar.datetime.date():
if self.day_open:
self.buy_setup = self.day_low - self.setup_coef * (self.day_high - self.day_close) # 观察买入价
self.sell_setup = self.day_high + self.setup_coef * (self.day_close - self.day_low) # 观察卖出价
self.buy_enter = (self.enter_coef_1 / 2) * (self.day_high + self.day_low) - self.enter_coef_2 * self.day_high # 反转买入价
self.sell_enter = (self.enter_coef_1 / 2) * (self.day_high + self.day_low) - self.enter_coef_2 * self.day_low # 反转卖出价
self.buy_break = self.buy_setup + self.break_coef * (self.sell_setup - self.buy_setup) # 突破买入价
self.sell_break = self.sell_setup - self.break_coef * (self.sell_setup - self.buy_setup) # 突破卖出价
self.day_open = bar.open_price
self.day_high = bar.high_price
self.day_close = bar.close_price
self.day_low = bar.low_price
# Today
else:
self.day_high = max(self.day_high, bar.high_price)
self.day_low = min(self.day_low, bar.low_price)
self.day_close = bar.close_price
if not self.sell_setup:
return
self.tend_high, self.tend_low = am.donchian(self.donchian_window)
if bar.datetime.time() < self.exit_time:
if self.pos == 0:
self.intra_trade_low = bar.low_price
self.intra_trade_high = bar.high_price
if self.tend_high > self.sell_setup:
long_entry = max(self.buy_break, self.day_high)
self.buy(long_entry, self.fixed_size, stop=True)
self.short(self.sell_enter, self.multiplier * self.fixed_size, stop=True)
elif self.tend_low < self.buy_setup:
short_entry = min(self.sell_break, self.day_low)
self.short(short_entry, self.fixed_size, stop=True)
self.buy(self.buy_enter, self.multiplier * self.fixed_size, stop=True)
elif self.pos > 0:
self.intra_trade_high = max(self.intra_trade_high, bar.high_price)
long_stop = self.intra_trade_high * (1 - self.trailing_long / 100)
self.sell(long_stop, abs(self.pos), stop=True)
elif self.pos < 0:
self.intra_trade_low = min(self.intra_trade_low, bar.low_price)
short_stop = self.intra_trade_low * (1 + self.trailing_short / 100)
self.cover(short_stop, abs(self.pos), stop=True)
# Close existing position
else:
if self.pos > 0:
self.sell(bar.close_price * 0.99, abs(self.pos))
elif self.pos < 0:
self.cover(bar.close_price * 1.01, abs(self.pos))
self.put_event()
def on_order(self, order: OrderData):
"""
Callback of new order data update.
"""
pass
def on_trade(self, trade: TradeData):
"""
Callback of new trade data update.
"""
self.put_event()
def on_stop_order(self, stop_order: StopOrder):
"""
Callback of stop order update.
"""
pass
想了解更多关于CTA策略开发实战的各种细节?请戳课程上线:《vn.py全实战进阶》!目前课程已经更新过半,一共50节内容覆盖从策略设计开发、参数回测优化,到最终实盘自动交易的完整CTA量化业务流程。
了解更多知识,请关注vn.py社区公众号。

要获取Tick数据,并插入到vn.py数据库中,整体上有3种方法:
那么本文我们就选择第3种方法,通过读取CSV文件,把数据载入到数据库中。
首先需要保证你已经在系统上安装配置好了数据库,这里演示用的是MongoDB数据库以及图形化客户端Robo 3T。
注意在MongoDB中需要创建新数据库“vnpy”,然后在全局配置对话框中,修改相关配置:
"database.driver": "mongodb",
"database.database": "vnpy",
"database.host": "localhost",
"database.port": 27017,
"database.user": "",
"database.password": "",
"database.authentication_source": ""
注意输入上述内容到配置对话框中时,请忽略引号。修改完毕保存后,请重新启动VN Trader,检查相关配置是否已经修改成功。
然后我们把所有的CSV文件放在同一文件夹下,这样就可以使用一个脚本来读取该文件夹内的所有CSV格式文件,并批量载入到数据库中。

在开始处理数据之前,我们需要知道CSV文件中的表头信息和数据特征。用Excel打开其中任意一个CSV文件,查看其中的内容后,建立一个比较直观的印象,大概知道:
这里我们的CSV文件,表头以及第一行内容如下:
交易日,合约代码,交易所代码,合约在交易所的代码,最新价,上次结算价,昨收盘,昨持仓量,今开盘,最高价,最低价,数量,成交金额,持仓量,今收盘,本次结算价,涨停板价,跌停板价,昨虚实度,今虚实度,最后修改时间,最后修改毫秒,申买价一,申买量一,申卖价一,申卖量一,申买价二,申买量二,申卖价二,申卖量二,申买价三,申买量三,申卖价三,申卖量三,申买价四,申买量四,申卖价四,申卖量四,申买价五,申买量五,申卖价五,申卖量五,当日均价,业务日期
20190102,ru1905,,,11280.0000,11290.0000,11305.0000,322472,11280.0000,11280.0000,11280.0000,246,27748800.0000,322468,0.0000,0.0000,12080.0000,10495.0000,0,0,08:59:00,500,11280.0000,10,11290.0000,10,0.0000,0,0.0000,0,0.0000,0,0.0000,0,0.0000,0,0.0000,0,0.0000,0,0.0000,0,112800.0000,20190102
从以上内容中,我们发现下述特征:
有了这样的需求后,我们在接下来开发脚本的过程中就有了方向:
1)使用for循环遍历同一文件夹内所有CSV格式的文件(即以“.csv"结尾的文件名),使用csv_load函数来载入数据:
import os
import csv
from datetime import datetime, time
from vnpy.trader.constant import Exchange
from vnpy.trader.database import database_manager
from vnpy.trader.object import TickData
def run_load_csv():
"""
遍历同一文件夹内所有csv文件,并且载入到数据库中
"""
for file in os.listdir("."):
if not file.endswith(".csv"):
continue
print("载入文件:", file)
csv_load(file)
2)csv_load函数的具体设计
def csv_load(file):
"""
读取csv文件内容,并写入到数据库中
"""
with open(file, "r") as f:
reader = csv.DictReader(f)
ticks = []
start = None
count = 0
for item in reader:
# generate datetime
date = item["交易日"]
second = item["最后修改时间"]
millisecond = item["最后修改毫秒"]
standard_time = date + " " + second + "." + millisecond
dt = datetime.strptime(standard_time, "%Y%m%d %H:%M:%S.%f")
# filter
if dt.time() > time(15, 1) and dt.time() < time(20, 59):
continue
tick = TickData(
symbol="RU88",
datetime=dt,
exchange=Exchange.SHFE,
last_price=float(item["最新价"]),
volume=float(item["持仓量"]),
bid_price_1=float(item["申买价一"]),
bid_volume_1=float(item["申买量一"]),
ask_price_1=float(item["申卖价一"]),
ask_volume_1=float(item["申卖量一"]),
gateway_name="DB",
)
ticks.append(tick)
# do some statistics
count += 1
if not start:
start = tick.datetime
end = tick.datetime
database_manager.save_tick_data(ticks)
print("插入数据", start, "-", end, "总数量:", count)
if __name__ == "__main__":
run_load_csv()
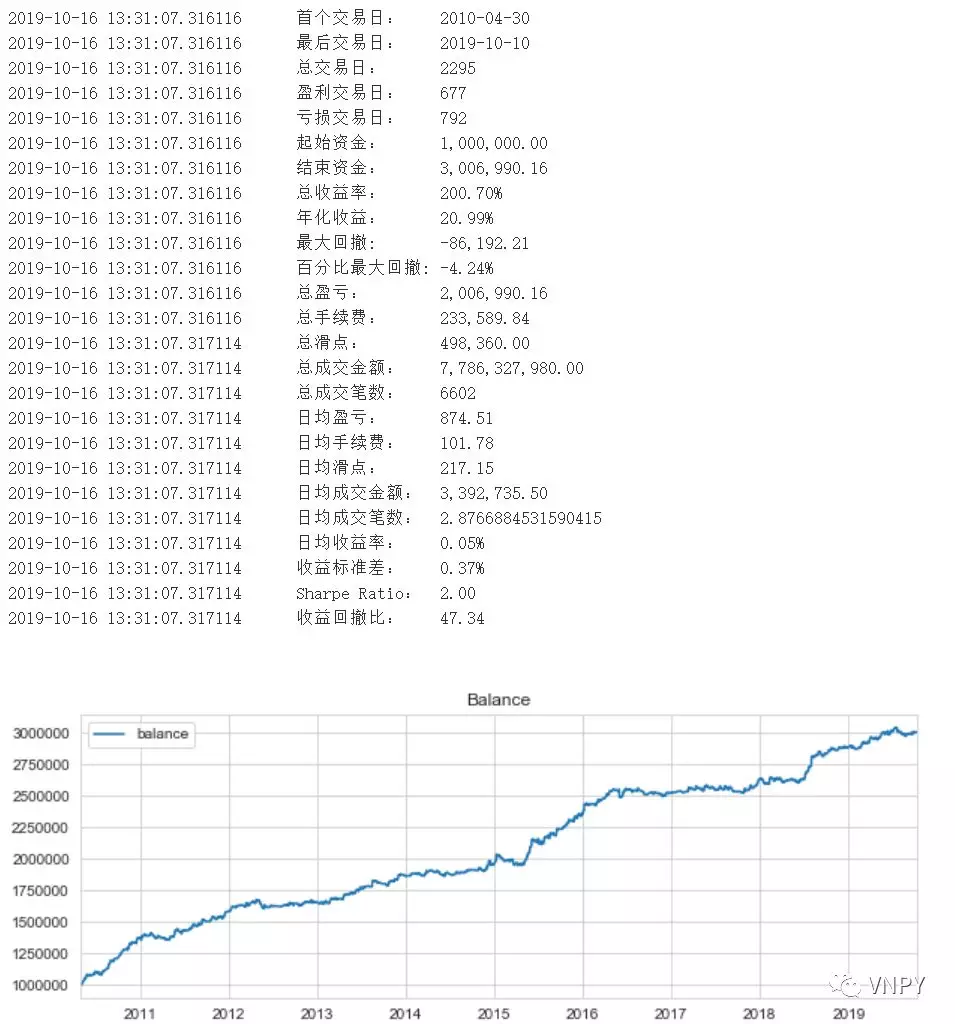
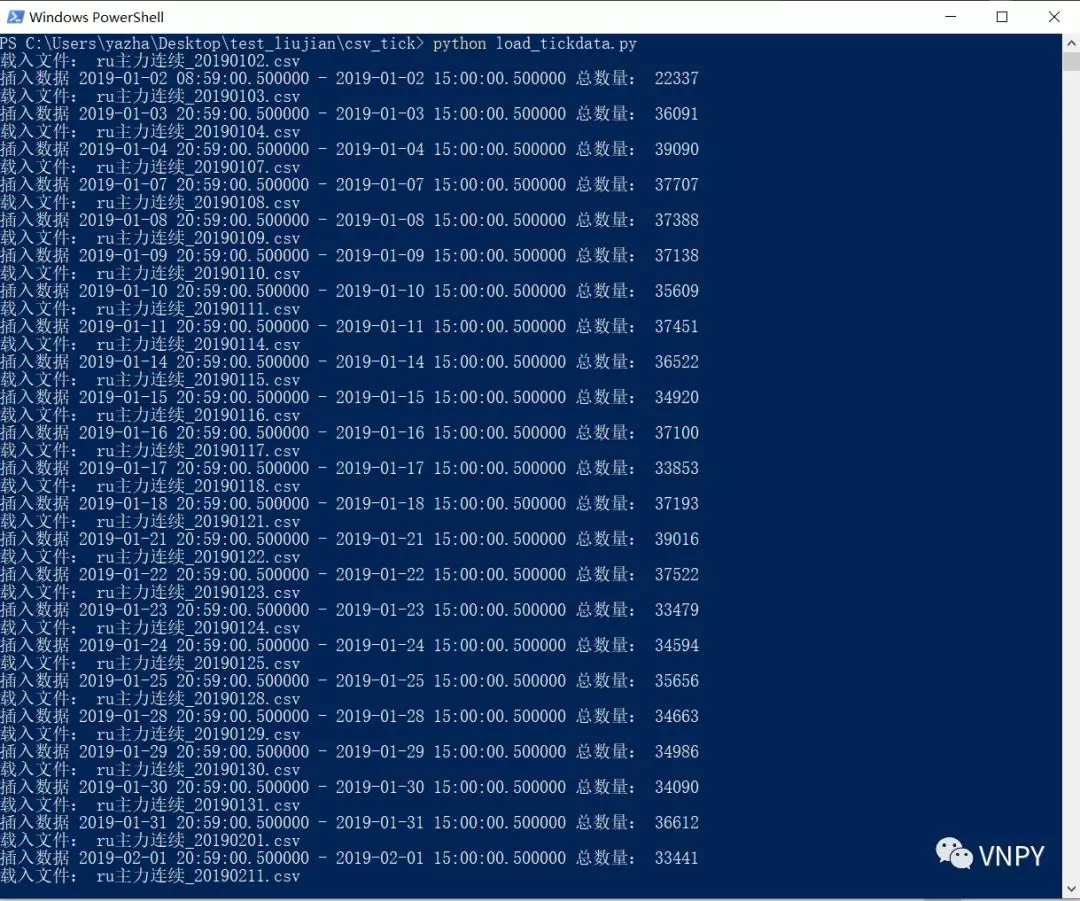
创建好脚本后可以直接运行:进入cmd或者Powershell,运行命令python load_tickdata.py即可,效果如下图所示:
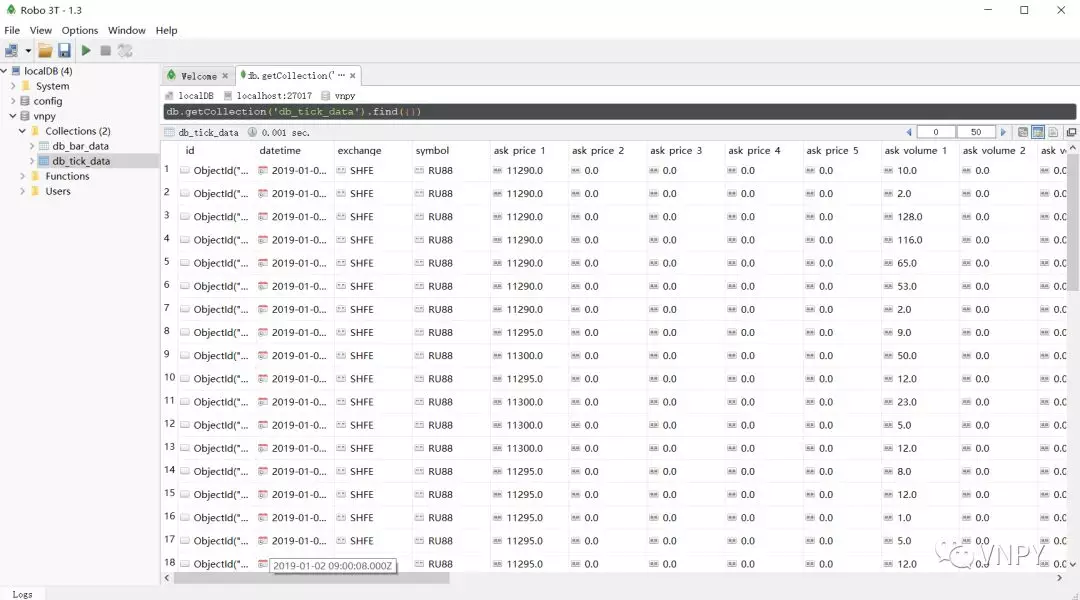
此时我们使用Robo 3T客户端来连接上MongoDB,在数据库【vnpy】->【db_tick_data】可以看到新载入的数据:
CTA策略模块(CtaStrategy)的回测引擎BacktestingEngine支持Tick数据的回测,以下代码推荐在Jupyter Notebook中运行。
第一步我们需要在策略文件中进行一些修改,这里以AtrRsiStrategy策略为例:找到on_init函数,把其中的load_bar(10)改为load_tick(10),即指定加载过去10天的Tick数据来执行策略初始化任务,而不是加载K线Bar数据进行初始化。
然后在加载回测相关的模块时,需要额外加载BacktestingMode枚举类型,其中包含有回测引擎所支持的Bar(K线)和Tick两种模式:
from vnpy.app.cta_strategy.backtesting import BacktestingEngine, OptimizationSetting
from vnpy.app.cta_strategy.base import BacktestingMode
from datetime import datetime
from atr_rsi_strategy import AtrRsiStrategy
创建回测引擎对象的实例后,在调用set_parameters函数时,参数中需要新增“mode=BacktestingMode.TICK ”,来指定回测引擎使用Tick回测模式。
同时需要注意另外2点:
engine = BacktestingEngine()
engine.set_parameters(
vt_symbol="RU88.SHFE",
interval="1m",
start=datetime(2019, 1, 1),
end=datetime(2019, 4, 1),
rate=0.5/10000,
slippage=5,
size=10,
pricetick=5,
capital=1_000_000,
mode=BacktestingMode.TICK
)
engine.add_strategy(AtrRsiStrategy, {})
后续的操作和K线模式回测就几乎完全相同了,加载历史数据并执行数据回放,然后基于逐笔成交计算每日盈亏数据,并生成最终的策略统计结果以及回测图表:
engine.load_data()
engine.run_backtesting()
df = engine.calculate_result()
engine.calculate_statistics()
engine.show_chart()
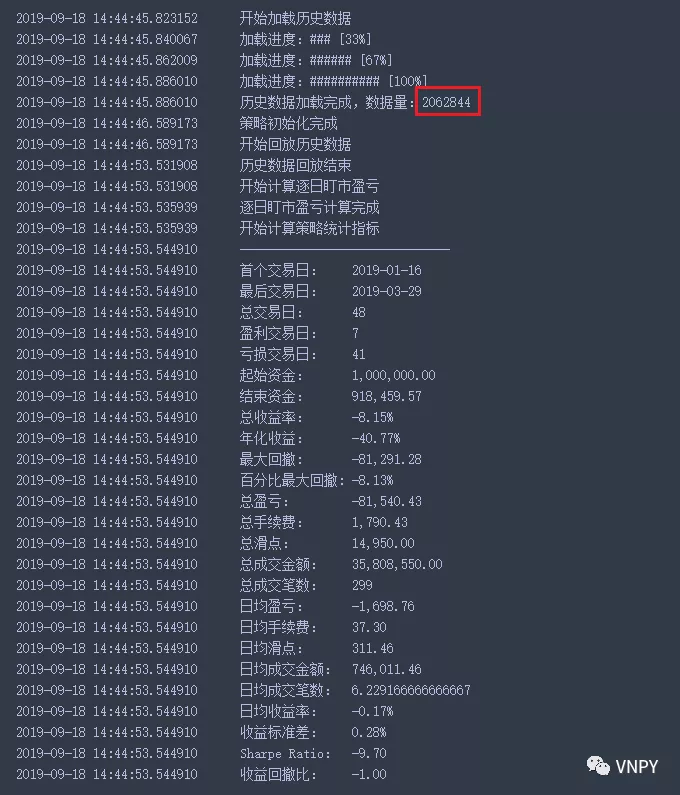
由于这3个月行情多为区间震荡,所以以去趋势跟踪为核心逻辑的AtrRsiStrategy的回测效果不太理想:
下面我们如果想再看看详细的逐笔成交记录,可以遍历回测引擎中保存所有成交数据的trades字典,并打印每笔成交相关的字段信息:
trades = engine.trades
for value in trades.values():
print("时间:",value.datetime,value.direction.value,value.offset.value, "价格:",value.price, "数量:",value.volume)
if value.offset.value == "平":
print("---------------------------------------------------------")
这样就能看到每笔成交具体发生的时间点,并和Tick数据当时的盘口情况进行相应的比对检查了:
《vn.py全实战进阶》课程已经更新过半!一共50节内容覆盖从策略设计开发、参数回测优化,到最终实盘自动交易的完整CTA量化业务流程,详细内容请戳课程上线:《vn.py全实战进阶》!
了解更多知识,请关注vn.py社区公众号。

做量化,不管在研究策略还是实盘交易的过程中,都离不开数据。更准确地说,是都不离开从数据库读取中精确的数据。
高质量的数据,有利于保证模型分析和策略开发时最终产出结果的准确性,并且也能帮助避免在策略实盘初始化过程中由于异常数据导致的无谓损失。
在数据的获取方面,vn.py内部集成了以下常用的数据源:
其中,RQData数据源是vn.py通过对米筐提供的rqdatac库再次封装调用实现的,具体实现逻辑包含在RqdataClient类中。
而后两者,则是通过对应交易接口Gateway类的query_history函数,来实现历史数据下载的功能。
除了使用以上的集成数据功能来在线下载数据外,vn.py的CsvLoader模块还提供了从csv文件读取数据,并自动插入到数据库中的功能,方便用户更加灵活的使用来自其他地方的数据。
多渠道的数据获取和维护,在另一方面也凸显出数据库管理的重要性,所以vn.py选择将所有数据库相关的逻辑代码,全部整合在一个模块中进行实现,这就是数据库模块:
该模块位于vnpy\trader\database目录下,其中database.py中的BaseDatabaseManager类定义了数据插入和读取相关的标准接口。为了更直观的展示,我们使用了框架图来辅助说明:
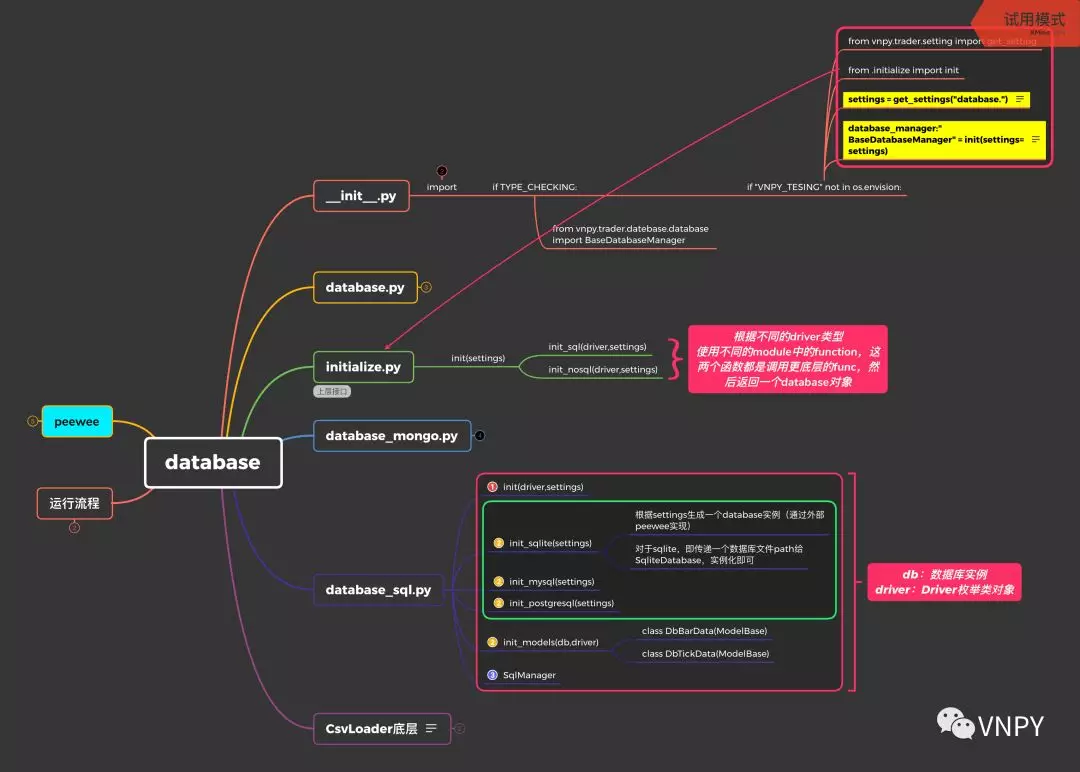
数据库模块内部的调用过程,整体来说可以分成4个步骤:
在介绍database_sql.py逻辑之前,我们需要简单讲一下peewee库:peewee是一个轻量级的对象-关系映射(Object-Relational Mapping,简称ORM)框架,用统一的形式对SQL数据库进行管理,开放上层接口给用户使用。
peewee的用法比较简单:
所以,我们可以用peewee库提供的数据库引擎类实例化,建立与数据文件的连接;然后定义一个model类用于表示表;最后将model类添加到数据库引擎类(即生成数据表)。
此时,db即可表示一个与数据文件连接着的数据引擎实例,上面添加到db的model类即可表示db中的一张张表,并且可以取出来继续单独使用。
那么在database_sql.py中,整个逻辑过程如下:
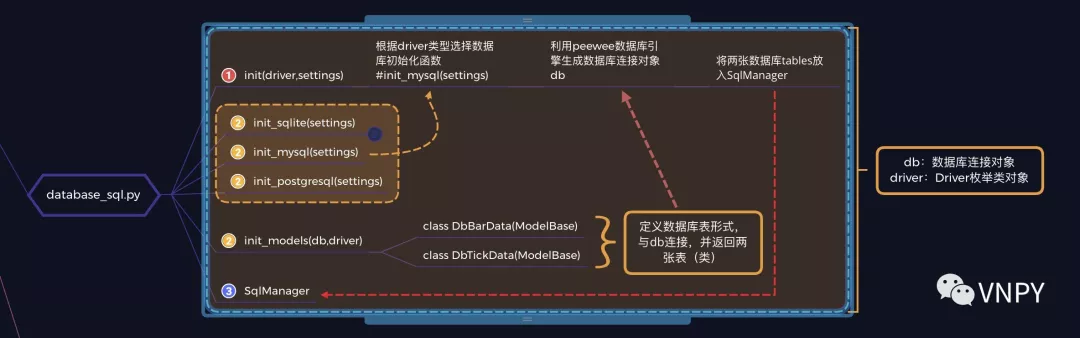
上面大致介绍了DataManager在VN Trader启动时的初始化过程,对于没有太多数据库使用经验的读者来说可能看的云里雾里(其实对于作者来说以上语言也十分的绕口不好读)。
但是不用担心,要把一辆自动挡汽车开起来并不需要知道具体的发动机和变速箱工作原理,只要分得清楚油门刹车,会打方向盘就行。接下来我们进入实操阶段的内容,具体讲解不同数据库该如何配置。
SQLite是vn.py默认的数据库,无需用户做任何配置即可直接使用。作为轻量级的文件数据库,SQLite只有数据库驱动而没有服务器程序,且所有Python标准库都自带,无需用户另外安装。
除了SQLite以外,其他的数据库都需要我们自行安装,并在VN Trader的全局配置对话框中设置相关参数。
首先在MySQL官网下载Windows版本安装包【MySQL Installer for Windows】:
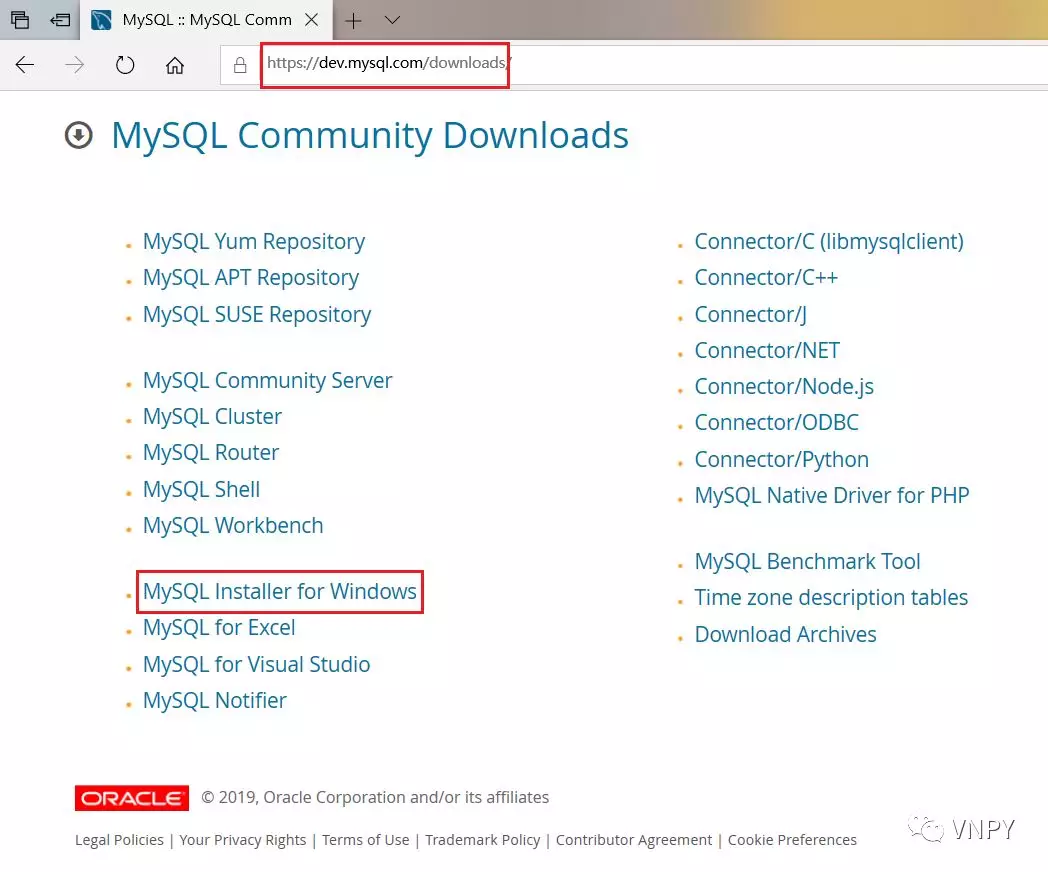
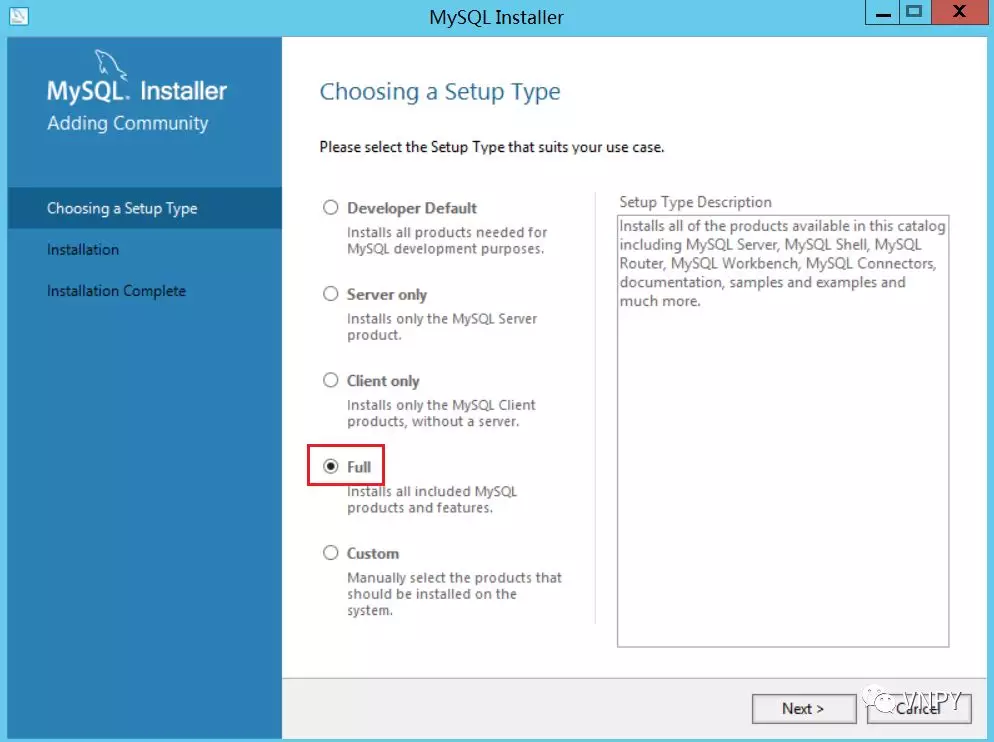
下载完成后得到msi格式的安装包,双击打开后选择【Full】模式,安装MySQL完整版,然后一直点击【Next】按钮即可完成安装。
安装过程中将会自动从网站下载相关组件,先点击【Execute】按钮来补全,再点击【Next】按钮。
安装过程中将会要求我们输入3次密码,这里为了方便演示,我们将密码设置为1001(请在自己安装的过程中使用更加复杂安全的密码)。

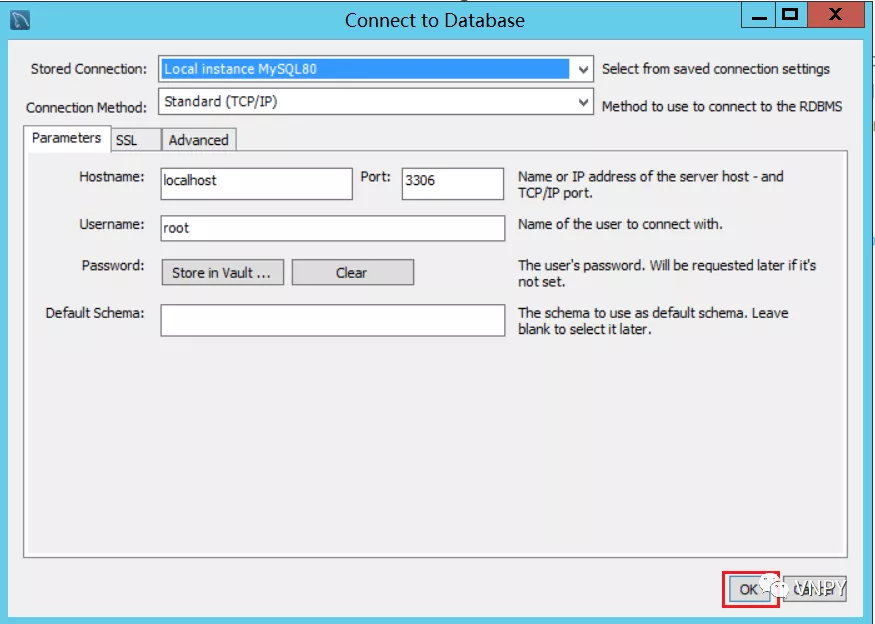
安装完毕后会自动打开MySQL的图形管理工具MySQL WorkBench,点击菜单栏【Database】->【Connect to Database】:

在弹出的对话框中,直接选择默认数据库Local Instance MySQL,然后点击【OK】按钮连接上我们的MySQL数据库服务器。
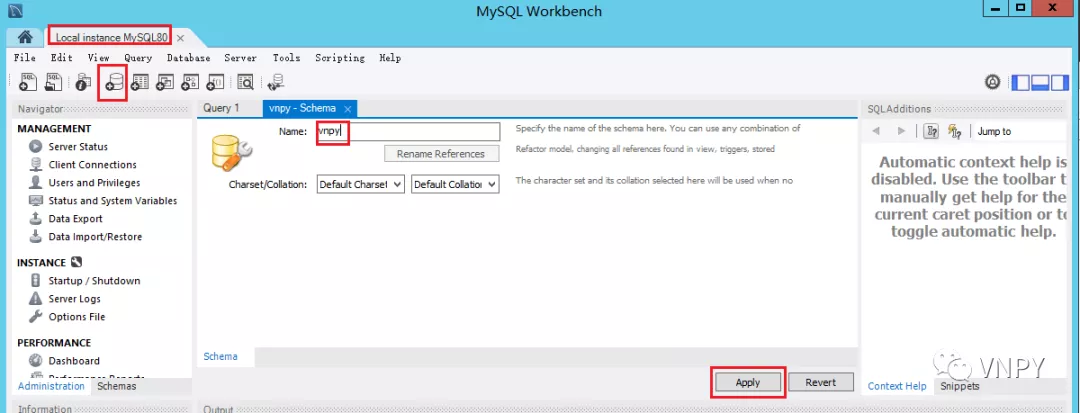
在自动打开的数据库管理界面中,点击下图中菜单栏红色方框的按钮,来创建新的数据库。在【Name】选择我们输入“vnpy”,然后点击下方的【Apply】按钮确认。
在之后弹出的数据库脚本执行确认对话框中,同样点击【Apply】即可,这样我们就完成了在MySQL WorkBench的所有操作。
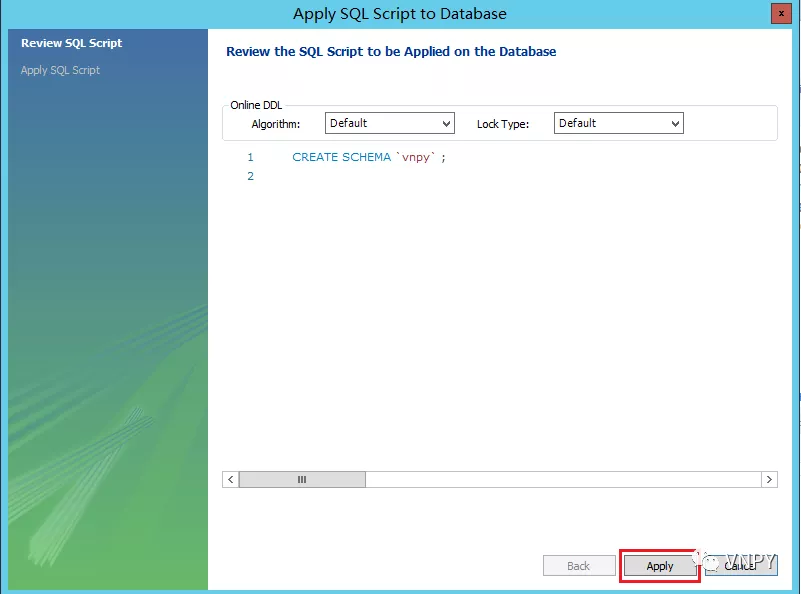
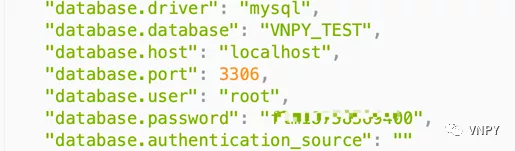
现在我们需要启动VN Trader,点击菜单栏的【配置】后,设置数据库相关字段:
"database.driver": "mysql"
"database.database": "vnpy"
"database.host": "localhost"
"database.port": 3306,
"database.user": "root"
"database.password": "1001"
上表中的双引号都无需输入,保存完成配置修改后,我们需要重启VN Trader来启用新的数据库配置。重启后,在打开VN Trader的过程中若无报错提示,则说明MySQL数据库配置成功。
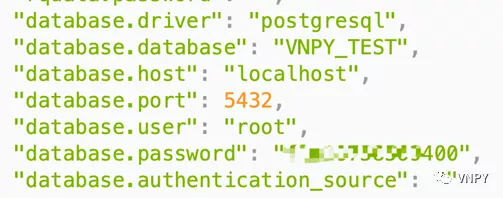
在PostgreSQL官网下载安装包:
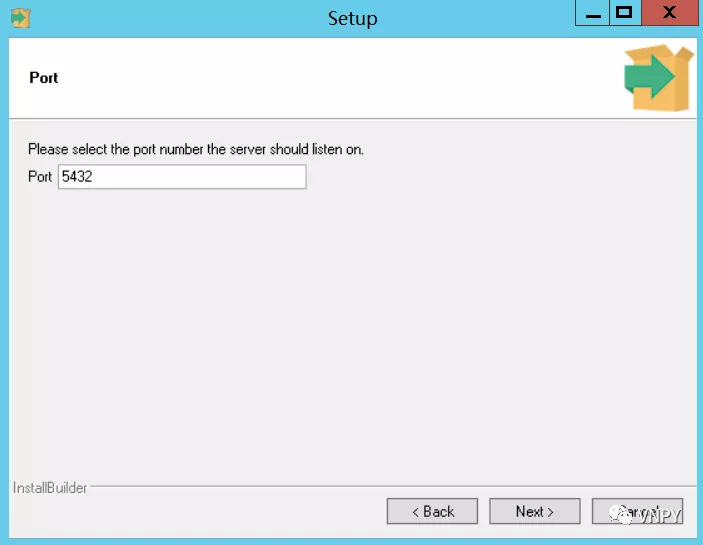
运行安装文件,同样一路点击【Next】按钮即可完成安装,在安装途中需要输入密码(1001):

同时记住PostgreSQL的默认端口为5432:
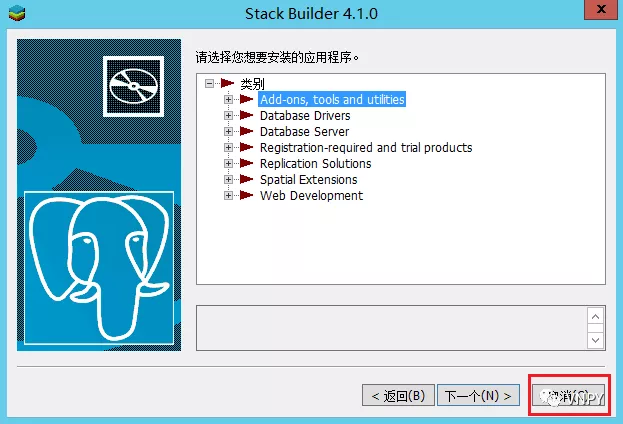
安装完毕后,若弹出Stack Builder界面直接点击【取消】就可以了,它一般用来安装其他补充组件:
与MySQL一键安装完服务器和客户端不同,PostgreSQL需要用户自行安装图形管理工具。
这里我们选择pgAdmin,首先从pgAdmin官网下载最新的exe格式安装包:
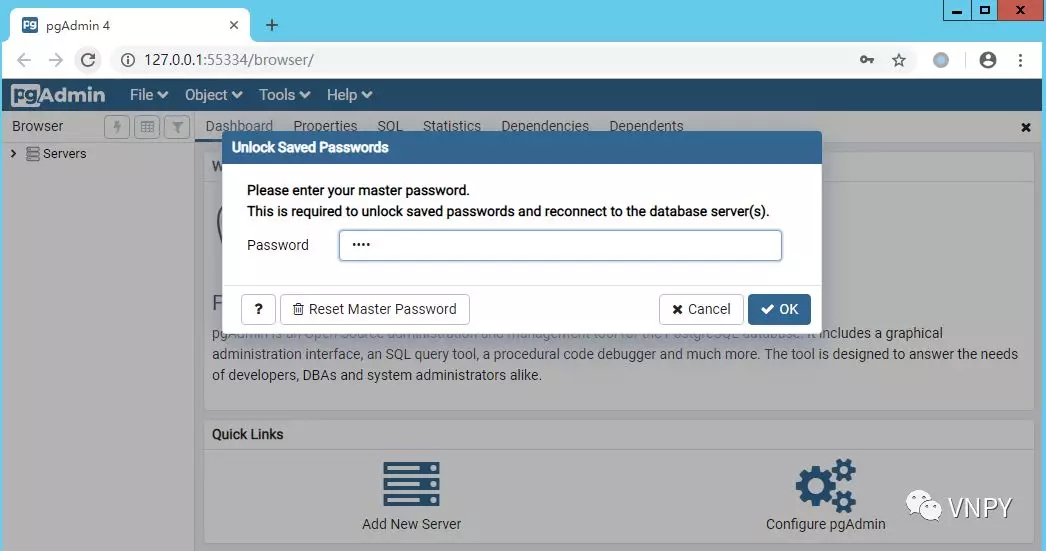
安装过程同样是一路【Next】,完成后在浏览器中会自动打开pgAdmin管理界面,这里我们要输入之前设置的数据库密码(1001)进入管理界面:
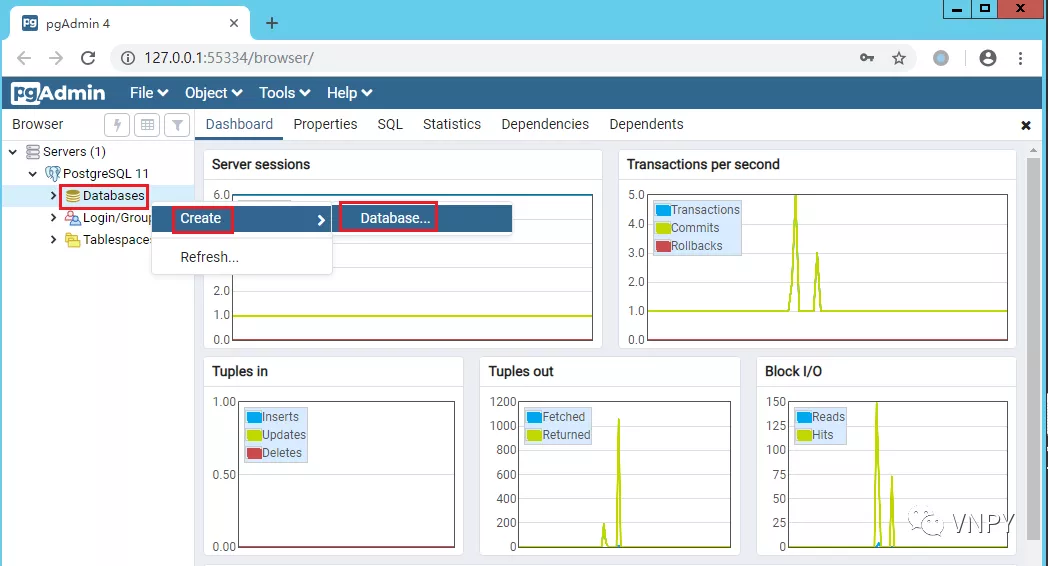
在管理界面中,点击【Database】->【Create】->【Database】会弹出【Create-Datebase】窗口:
这里我们选择创建的数据库名称为database.db,当然你也可以选择其他任意的名称:
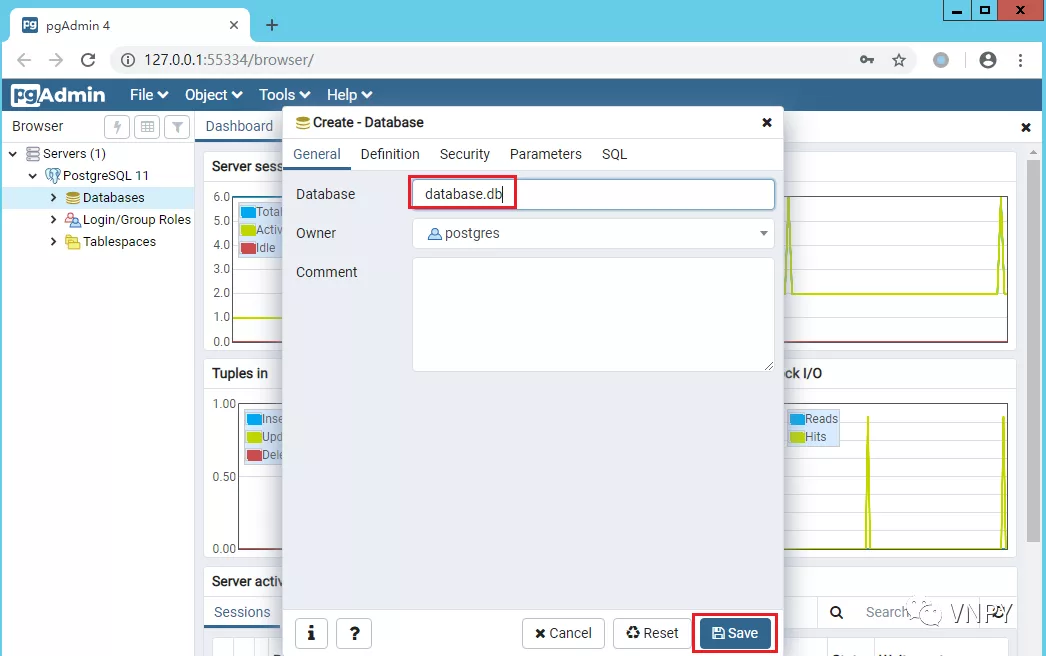
点击【Save】按钮完成新数据库创建后,发现它处于未连接状态:

鼠标点击一下即可自动完成连接:

然后我们需要检查一下PostgreSQL的登录用户名,点击【Login/Group Roles】可以发现下面8个都是Group,只有最后一个是User,User的名称是“postgres”:

到这里我们就已经获取到了所有相关的数据库信息,参考之前的MySQL配置过程在VN Trader中进行设置即可:
driver要改成postgresql;
database改成database.db;
host为本地IP,即localhost或者127.0.0.1;
port为5432;
user用户名为postgres
password密码为1001。
"database.driver": "postgresql"
"database.database": "database.db"
"database.host": "localhost"
"database.port": 5432
"database.user": "postgres"
"database.password": "1001"
同样,修改完后记得重启VN Trader。
在MongoDB官网下载安装包:
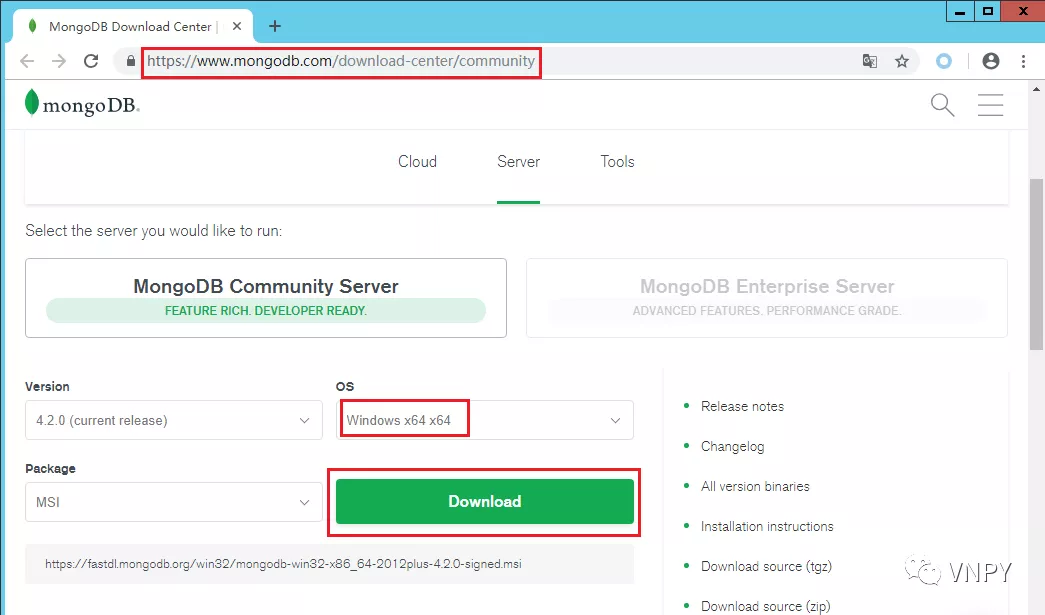
运行安装包,点击【Complete】按钮来安装完整版,一路点击【Next】:

在安装过程中的最后阶段,会自动帮我们装上图形管理工具MongoDB Compass,并且在完成后自动运行。我们只需点击【CONNECT】按钮即可连接上MongoDB数据库服务器:
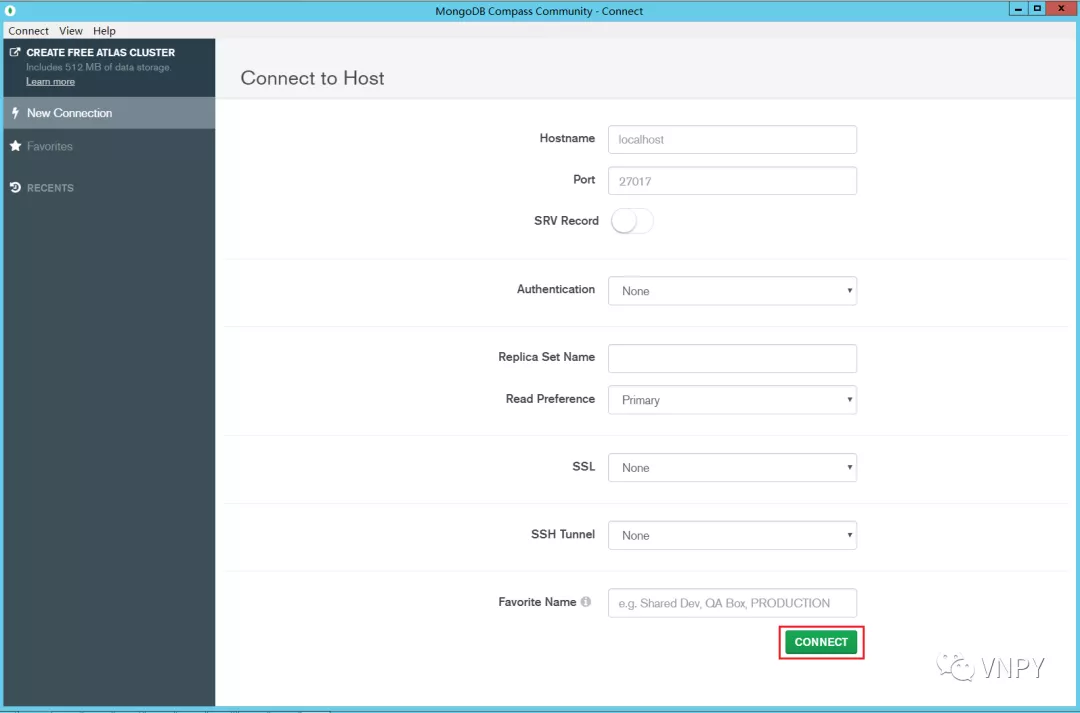
点击【CREATE DATABASE】按钮创建数据库:
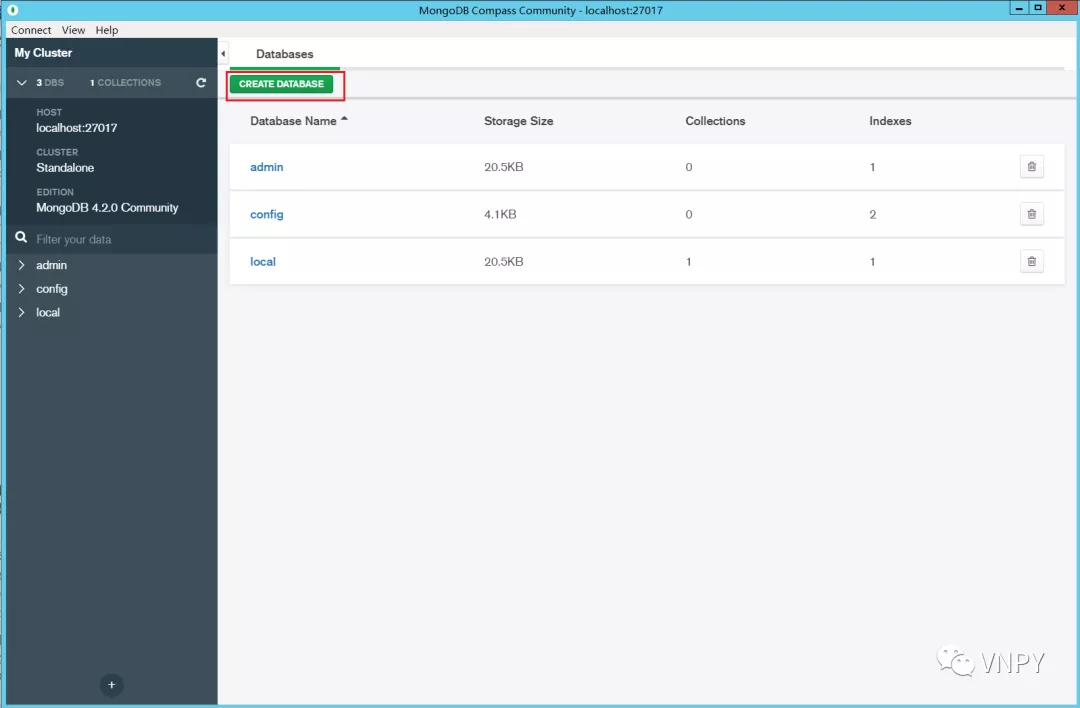
在对话框中Database和Collection Name均填写“vnpy”,然后点击下方的【CREATE DATABASE】完成数据库的创建:
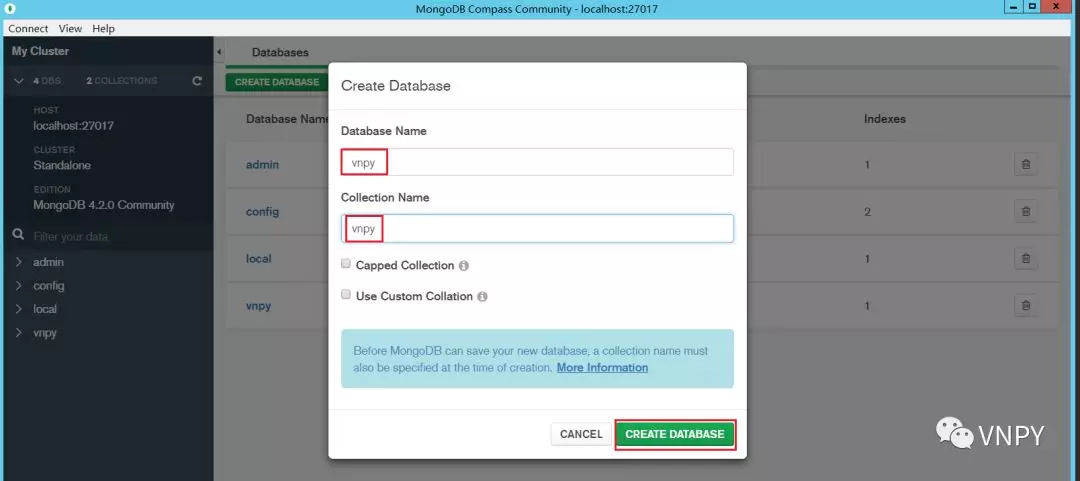
最后在VN Trader中完成配置:
"database.driver": "mongodb"
"database.database": "vnpy"
"database.host": "localhost"
"database.port": 27017
"database.user": ""
"database.password": ""
"database.authentication_source": ""
最后,别忘记重启~~~
《vn.py全实战进阶》课程全新上线,一共50节内容覆盖从策略设计开发、参数回测优化,到最终实盘自动交易的完整CTA量化业务流程,目前已经更新到第十三集,详细内容请戳课程上线:《vn.py全实战进阶》!
了解更多知识,请关注vn.py社区公众号。

我们平时看到的K线图几乎都是采用普通坐标 ,而有一种叫作对数坐标的K线图大部分人可能没了解过。
在介绍对数坐标下的K线图之前,我们先思考一个问题:以下两种情形,情形1的涨幅大还是情形2的涨幅大?
从绝对数值来看,情形1涨了1200点(1200=1300-100),情形2涨了5000点(5000=6000-1000)。情形2涨的绝对幅度大。
但如果换个新的思路呢?以收益率的角度看,结果完全反过来了:情形1涨了12倍(12=(1300-100)/100),情形2涨了5倍(5=(6000-1000)/1000)。情形1的收益率更大。
从实际情况,我们也应该更看重价格收益率而非价格涨幅度。回归现实世界中的例子,情形1对应的是中国股市刚开始时期上证指数行情(91-92年),若投入1000元,那么期末收益为12000元。情形2对应的是06-07年牛市行情,同样投入1000元,期末收益为5000元。
所以,从收益率上就凸显了对数化坐标的优势:
下面2幅图分别对应上证指数的标准坐标和对数坐标。显然,对数坐标能更容易挖掘到盈利点。
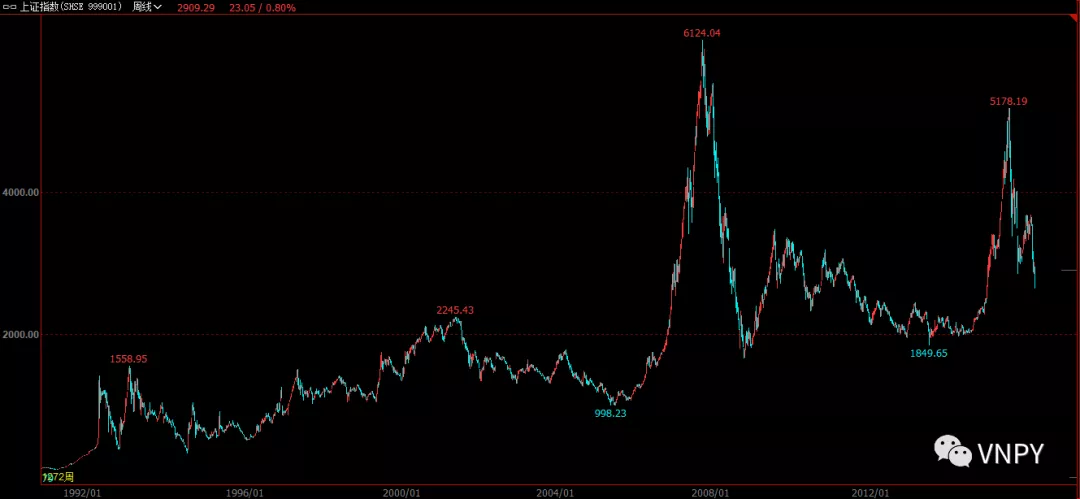
(标准坐标)
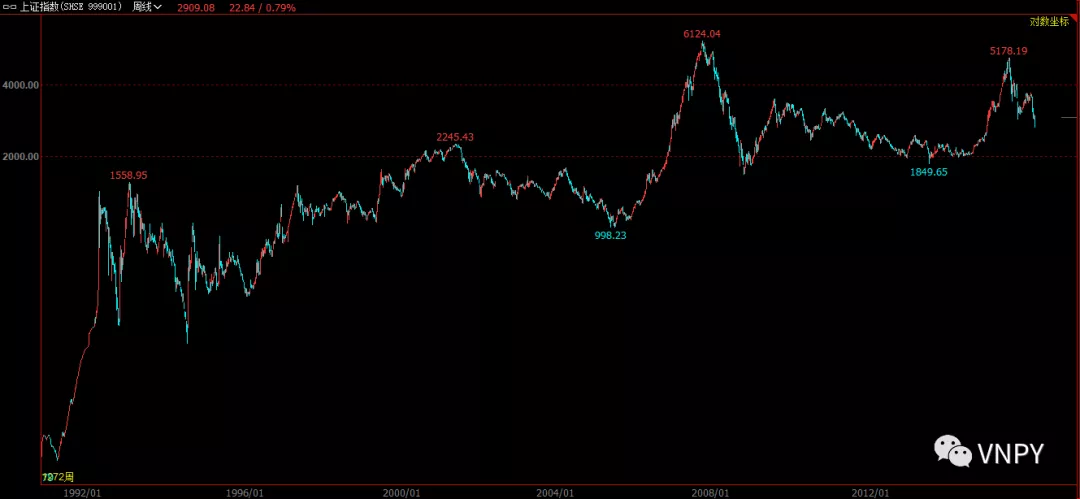
(对数坐标)
CTA策略大致可以分成2类:
1)趋势突破类
行情一旦有突破迹象(即行情还未走远或者正式确立)就下单成交,但是实际上大部分的突破都是假的,只有少部分行情能走到一波比较强的趋势。所以趋势突破类策略具有胜率低的特点(一般预测准确率< 40%)。
策略的盈利主要依赖对止盈止损的控制:如亏损的交易止损设为10%,而少部分盈利的交易止盈设为500%。若交易次数足够多(满足大数定律和中心极限定理),那么少部分能捕捉到大趋势的盈利,足以覆盖大部分假突破导致的风险,从而让策略整体盈利。
若胜率在30%到40%,那么盈亏比需要控制在2以上,从而使整个策略是盈利的。举个例子来简单说明一下:
低胜率与高盈亏比是趋势突破类策略的两大特征,在统计学上表现出尖峰肥尾的特点,尖峰代表亏损的交易比较多,但亏损数额都不大,肥尾则说明少部分成功交易所带来的盈利是巨大的。
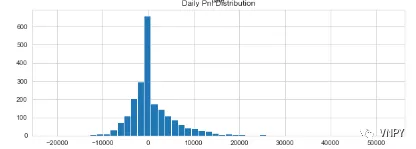
趋势突破类中的突破通常指的是通道突破,如突破布林带通道的上轨做多,突破布林带通道下轨做空。
由于布林带通道的构成因素是基于标准坐标的,属于价位指标。对数化的效果反而不好,所以对数化的技术不适用于趋势突破类策略。
2)趋势跟踪类
行情已经突破并且走了有一段距离(即行情正式确立)才下单成交。因为行情已经确立,所以策略预测的成功率会比较高;但由于行情已经走出一段距离才下单追上去,盈利空间大幅度减少,甚至会遇到行情的反转。
所以,趋势跟踪类策略的特点恰好与趋势突破类相反:胜率高,盈亏比低。它所依赖的不是基于绝对价位的通道类突破,而是一些非价位指标,如RSI指标高于66时候做多,RSI指标低于34时做空等。
对数化处理非价位指标,可以进一步提升趋势跟踪类策略的盈利空间,下面通过vn.py里面的AtrRsi策略来展示对数化的效果。
策略的原理
行情能走出大趋势的充分条件是波动率增大,即当前波动率突破历史平均波动率(ATR>ATR均值)。在波动率变大,市场参与者增多或者多空双方开始发力的时候,我们可以判断在一定时间内:
然后我们看看原始的策略效果如何?
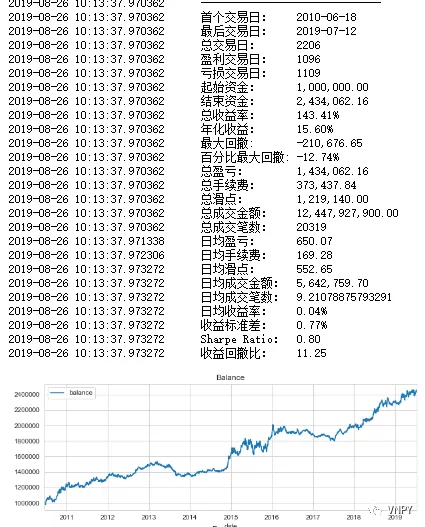
策略的夏普比率是0.8,收益回撤比是11.25。
尝试对数化非价位指标
vnpy\vnpy\trader目录下的utility.py文件是负责定义技术指标的。这些技术指标都是基于talib库来实现的,在log字段填True,就可以对数化我们需要的非价位指标了。
def atr(self, n, log=False, array=False):
"""
Average True Range (ATR).
"""
if log:
result = talib.ATR(np.log(self.high), np.log(self.low), np.log(self.close), n)
else:
result = talib.ATR(self.high, self.low, self.close, n)
if array:
return result
return result[-1]
def rsi(self, n, log=False, array=False):
"""
Relative Strenght Index (RSI).
"""
if log:
result = talib.RSI(self.close, n)
else:
result = talib.RSI(np.log(self.close), n)
if array:
return result
return result[-1]
在新的AtrRsi策略上,通过对数化处理的ATR和RSI指标,我们看看回测效果。
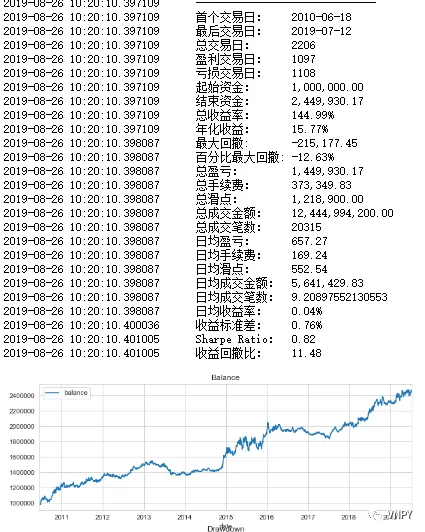
夏普比率是0.82,收益回撤比为11.48。对数化非价位指标对策略有影响,但是效果甚微。
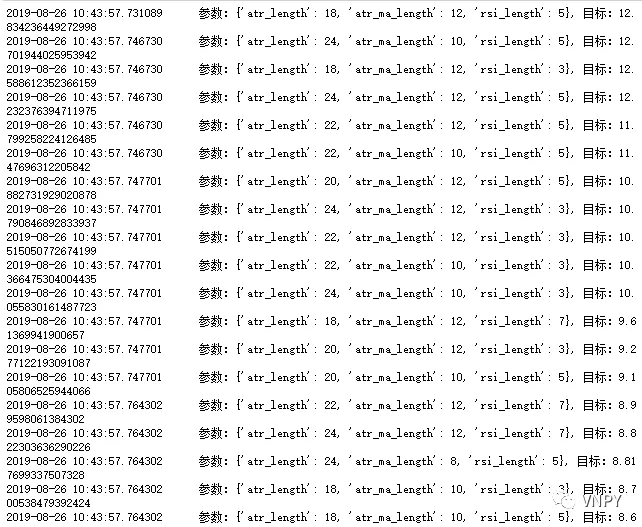
进一步验证:参数优化
为了进一步验证对数化非价位指标对策略有没有效果,我们用到了参数优化:优化目标是最大化收益回撤比,优化的参数分别是atr_length、atr_ma_length、rsi_length。
setting = OptimizationSetting()
setting.set_target("return_drawdown_ratio")
setting.add_parameter("atr_length", 18,24, 2)
setting.add_parameter("atr_ma_length",8, 12,2)
setting.add_parameter("rsi_length",3,7,2)
engine.run_optimization(setting)
我们先把对数化技术指标的策略称之为实验组,原始策略称之为对照组。优化完毕后,实验组和对照组最优参数都相同,均为:
atr_length=18
atr_ma_length=12,
rsi_length=5
但是,实验组的收益回撤比整体要高于对照组的。
(实验组优化结果)

(对照组优化结果)
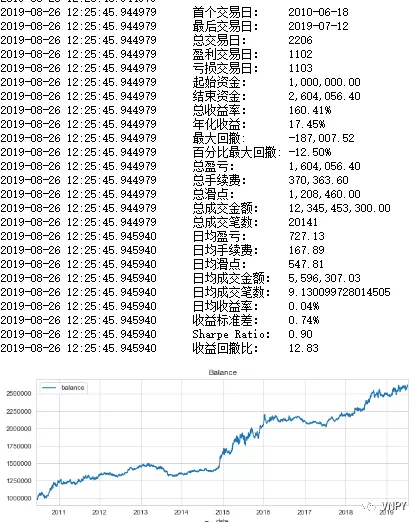
选取最优参数,我们再跑一下策略回测,就可以看到对数化非价位指标的确适用于趋势跟踪类策略的了。
(实验组最优参数回测)
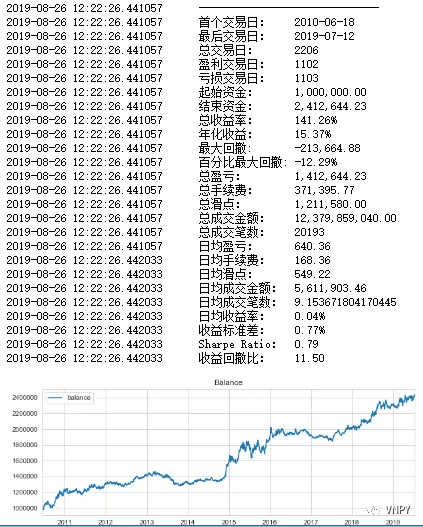
(对照组最优参数回测)
《vn.py全实战进阶》课程全新上线,一共50节内容覆盖从策略设计开发、参数回测优化,到最终实盘自动交易的完整CTA量化业务流程,目前已经更新到第八集,详细内容请戳课程上线:《vn.py全实战进阶》!
了解更多知识,请关注vn.py社区公众号。

双均线策略作为最常见最基础的CTA策略,也就是常说的金叉死叉信号组合得到的策略,常用于捕捉一段大趋势。它的思想很简单,由一个短周期均线和一个长周期均线组成,短周期均线代表近期的走势,长周期均线则是较长时间的走势:
下面就以vn.py项目中的双均线策略的源码为例,进行策略交易逻辑以及内部代码实现的解析。
1、创建策略实例
首先需要记住一点,所有vn.py框架中的CTA策略类(项目自带的或者用户开发的),都是基于CTA策略模板类(CtaTemplate)来实现的子类。策略类与模板类的关系如同抽象之于具体:照着汽车的设计图和技术规格,人类就能造出各种各样的汽车。
同理,CTA策略模板定义了一系列底层的交易函数和策略的逻辑范式,根据这种规则,我们可以快速实现出自己想要的策略。
class DoubleMaStrategy(CtaTemplate):
author = "用Python的交易员"
fast_window = 10
slow_window = 20
fast_ma0 = 0.0
fast_ma1 = 0.0
slow_ma0 = 0.0
slow_ma1 = 0.0
parameters = ["fast_window", "slow_window"]
variables = ["fast_ma0", "fast_ma1", "slow_ma0", "slow_ma1"]
def __init__(self, cta_engine, strategy_name, vt_symbol, setting):
""""""
super(DoubleMaStrategy, self).__init__(
cta_engine, strategy_name, vt_symbol, setting
)
self.bg = BarGenerator(self.on_bar)
self.am = ArrayManager()
首先我们需要设置策略的参数和变量,两者都从属于策略类,不同的是策略参数是固定的(由交易员从外部指定),而策略变量则在交易的过程中随着策略的状态变化,所以策略变量一开始只需要初始化为对应的基础类型,例如:整数设为0,浮点数设为0.0,而字符串则设为""。
策略参数列表parameters中,需要写入策略的参数名称字符串,基于该列表中的内容,策略引擎会自动从缓存的策略配置json文件中读取策略配置,图形界面则会自动提供用户在创建策略实例时配置策略参数的对话框。
策略变量列表variables中,则需要写入策略的变量名称字符串,基于其中的内容,图形界面会自动渲染显示(调用put_event函数时更新),策略引擎会在用户停止策略、收到成交回报时、调用sync_data函数时,将变量数据写入硬盘中的缓存json文件,用于程序重启后策略状态的恢复。
策略类的构造函数init,需要传递cta_engine、strategy_name、vt_symbol、setting四个参数,分别对应CTA引擎对象、策略名称字符串、标的代码字符串、设置信息字典。注意其中的CTA引擎,可以是实盘引擎或者回测引擎,这样就可以很方便的实现一套代码同时跑回测和实盘了。以上参数均由策略引擎在使用策略类创建策略实例时自动传入,用户本质上无需关心。
在构造函数中,我们还创建了一个BarGenerator实例,并传入了on_bar的1分钟K线回调函数,用于实现将tick数据(TickData)自动合成为分钟级别K线数据(BarData)。除此之外,ArrayManager实例则用于缓存BarGenerator合成出来的K线数据,将其转化为便于向量化计算的时间序列数据结构,并在内部支持使用talib来计算指标。
2、状态变量初始化
注意这里的策略状态变量初始化,并不是指上一步中创建策略实例时的初始化函数init中的逻辑。当用户在VN Trader的CTA策略模块界面上,点击【添加策略】按钮,并在弹出的窗口中设置好策略实例名称、合约代码、策略参数,实际上是完成了策略实例的创建。
此时策略实例中的变量状态,依旧是0或者""这样的原始数据。用户需要点击策略管理界面上的【初始化】按钮,来调用策略中的on_init函数,完成加载历史数据回放给策略初始化其中的变量状态的操作。
def on_init(self):
"""
Callback when strategy is inited.
"""
self.write_log("策略初始化")
self.load_bar(10)
从上面的代码中可以看到,用户在调用这个on_init函数后,会在CTA策略管理界面的日志组件中输出信息“策略初始化“,随后调用父类CtaTemplate提供的load_bar函数用于加载历史数据,CTA策略引擎会负责将数据推送给策略完成变量状态的初始化计算。
注意这里我们load_bar时,传入的参数是10,对应也就是加载10天的1分钟K线数据数据。在回测时,10天指的是10个交易日,而在实盘时,10天则是指的是自然日,因此加载的天数宁可多一些也不要太少。load_bar函数的实现如下:
def load_bar(
self,
days: int,
interval: Interval = Interval.MINUTE,
callback: Callable = None,
):
"""
Load historical bar data for initializing strategy.
"""
if not callback:
callback = self.on_bar #设置回调函数
self.cta_engine.load_bar(self.vt_symbol, days, interval, callback)
CtaTemplate在这里调用了CtaEngine的load_bar函数来完成历史数据的加载回放。查看CtaEngine中对于load_bar函数的实现后,我们可以看到历史数据加载的两种模式:首先尝试使用RQData API从远端服务器拉取,前提是需要配置好RQData账号,同时该合约的行情数据在RQData上可以找到(主要是国内期货),若获取失败则会尝试在本地数据库中进行查找(默认为位于.vntrader文件夹下的sqlite数据库)。
def load_bar(
self,
vt_symbol: str,
days: int,
interval: Interval,
callback: Callable[[BarData], None]
):
""""""
symbol, exchange = extract_vt_symbol(vt_symbol)
end = datetime.now()
start = end - timedelta(days)
# Query bars from RQData by default, if not found, load from database.
bars = self.query_bar_from_rq(symbol, exchange, interval, start, end)
if not bars:
bars = database_manager.load_bar_data(
symbol=symbol,
exchange=exchange,
interval=interval,
start=start,
end=end,
)
for bar in bars:
callback(bar)
从上述代码中可以看出,通过datetime模块获取当前时间作为end,然后减去10天的时间作为start进行查询。将得到的所有bar数据通过第一步load_bar中设定的回调函数on_bar进行调用,这样就实现了将加载的K线数据推送给CTA策略。
3、启动自动交易
完成策略变量的初始化之后,就可以启动策略的自动交易功能了。点击图形界面的【启动策略】按钮后,CTA引擎会自动调用策略中的on_start函数,同时将策略的trading控制变量设置为True,界面上的日志组件中就会出现相应的策略启动日志信息。
def on_start(self):
"""
Callback when strategy is started.
"""
self.write_log("策略启动")
self.put_event()
注意这里必须调用put_event函数,来通知图形界面刷新策略状态相关的显示(变量),如果不调用则界面不会更新。
4、接收Tick推送
启动自动交易后,CTP接口会以每0.5秒一次的频率推送Tick数据,再由VN Trader内部的事件引擎分发推送到我们的策略中,策略中的Tick数据处理函数如下:
def on_tick(self, tick: TickData):
"""
Callback of new tick data update.
"""
self.bg.update_tick(tick)
因为是较为简单的双均线策略,交易逻辑都在K线时间周期上执行,所以在接收到Tick数据后,通过调用策略实例所属的bg对象(BarGenerator)的update_tick,来实现Tick自动合成1分钟K线数据:
def update_tick(self, tick: TickData):
"""
Update new tick data into generator.
"""
new_minute = False
# Filter tick data with 0 last price
if not tick.last_price:
return
if not self.bar:
new_minute = True
elif self.bar.datetime.minute != tick.datetime.minute:
self.bar.datetime = self.bar.datetime.replace(
second=0, microsecond=0
)
self.on_bar(self.bar)
new_minute = True
if new_minute:
self.bar = BarData(
symbol=tick.symbol,
exchange=tick.exchange,
interval=Interval.MINUTE,
datetime=tick.datetime,
gateway_name=tick.gateway_name,
open_price=tick.last_price,
high_price=tick.last_price,
low_price=tick.last_price,
close_price=tick.last_price,
open_interest=tick.open_interest
)
else:
self.bar.high_price = max(self.bar.high_price, tick.last_price)
self.bar.low_price = min(self.bar.low_price, tick.last_price)
self.bar.close_price = tick.last_price
self.bar.open_interest = tick.open_interest
self.bar.datetime = tick.datetime
if self.last_tick:
volume_change = tick.volume - self.last_tick.volume
self.bar.volume += max(volume_change, 0)
self.last_tick = tick
update_tick函数内部主要是通过检查当前的Tick数据与上一笔Tick数据是否是属于同一分钟,来判断是否有新的1分钟K线生成,如果没有就会继续进行累加更新当前K线的信息。
这里意味着只有当T+1分钟的第一个Tick接收到了之后,T分钟的Bar数据才会生成。在创建bg对象的时候,我们传入了on_bar作为K线合成完毕的回调函数,所以在当新的1分钟K线生成后,就会通过on_bar函数推送到策略中。
5、核心交易逻辑
每个策略中最至关重要的就是策略的核心交易逻辑:
def on_bar(self, bar: BarData):
"""Callback of new bar data update."""
am = self.am
am.update_bar(bar)
if not am.inited:
return
fast_ma = am.sma(self.fast_window, array=True)
self.fast_ma0 = fast_ma[-1]
self.fast_ma1 = fast_ma[-2]
slow_ma = am.sma(self.slow_window, array=True)
self.slow_ma0 = slow_ma[-1]
self.slow_ma1 = slow_ma[-2]
cross_over = self.fast_ma0 > self.slow_ma0 and self.fast_ma1 < self.slow_ma1
cross_below = self.fast_ma0 < self.slow_ma0 and self.fast_ma1 > self.slow_ma1
if cross_over:
if self.pos == 0:
self.buy(bar.close_price, 1)
elif self.pos < 0:
self.cover(bar.close_price, 1)
self.buy(bar.close_price, 1)
elif cross_below:
if self.pos == 0:
self.short(bar.close_price, 1)
elif self.pos > 0:
self.sell(bar.close_price, 1)
self.short(bar.close_price, 1)
self.put_event()
在接收到K线数据,即bar对象的推送后,我们需要将该bar数据放入am(ArrayManager)时间序列容器中进行更新,当有了至少100个bar数据后am对象才初始化完毕(inited变为True)。
这里需要注意,如果在初始化策略状态变量时,没有足够的历史数据来让am初始化完毕,则在自动交易启动后,需要至少收到100个的bar数据来填充am容器,直到am初始化完毕后,才会执行后面的交易逻辑代码。
之后调用封装在ArrayManager内部的talib库,用于计算最新窗口内的技术指标,对应我们双均线策略中的也就是10窗口的MA和20窗口的MA指标。
注意这里的am.sma实际上是对talib中的SMA函数的进一步封装,本质上是在计算bar数据的收盘价的算术平均:
am = self.am
am.update_bar(bar)
if not am.inited:
return
fast_ma = am.sma(self.fast_window, array=True)
self.fast_ma0 = fast_ma[-1]
self.fast_ma1 = fast_ma[-2]
slow_ma = am.sma(self.slow_window, array=True)
self.slow_ma0 = slow_ma[-1]
self.slow_ma1 = slow_ma[-2]
然后通过判断是否出现金叉死叉来决定是否触发交易逻辑:
cross_over = self.fast_ma0 > self.slow_ma0 and self.fast_ma1 < self.slow_ma1
cross_below = self.fast_ma0 < self.slow_ma0 and self.fast_ma1 > self.slow_ma1
具体的委托指令已由CTA策略模板封装好了,在on_bar函数里面直接调用即可:
此处需要注意,国内期货有开平仓的概念,例如买入操作要区分为买入开仓和买入平仓;但股票和外盘期货都是净持仓模式,没有开仓和平仓概念,所以只需使用买入(buy) 和卖出(sell) 这两个指令就可以了。
if cross_over:
if self.pos == 0:
self.buy(bar.close_price, 1)
elif self.pos < 0:
self.cover(bar.close_price, 1)
self.buy(bar.close_price, 1)
elif cross_below:
if self.pos == 0:
self.short(bar.close_price, 1)
elif self.pos > 0:
self.sell(bar.close_price, 1)
self.short(bar.close_price, 1)
self.put_event()
6、委托回报
on_order是委托回调函数,当我们发出一个交易委托后,这个委托每当有状态变化时,我们都会收到该委托最新的数据推送,这条数据就是委托回报。
其中比较重要信息的是status委托状态(包括:拒单、未成交、部分成交、完全成交、已撤单),我们可以基于委托状态实现更加细粒度的交易委托控制(算法交易)。
这里我们的双均线策略由于逻辑较为简单,所以在on_order中没有任何操作:
def on_order(self, order: OrderData):
"""
Callback of new order data update.
"""
pass
同样对于on_trader(成交回报函数)以及on_stop_order(停止单回报函数)也没有任何操作。
7、停止自动交易
当每日的交易时段结束后(国内期货一般是下午三点收盘后),需要点击CTA策略界面的【停止】按钮来停止策略的自动交易。
此时CTA策略引擎会将策略的交易状态变量trading设为False,撤销该策略之前发出的所有活动状态的委托,以及将策略variables列表中的参数写入到缓存json文件中,最后调用策略的on_stop回调函数执行用户定义的逻辑:
def on_stop(self):
"""
Callback when strategy is stopped.
"""
self.write_log("策略停止")
self.put_event()
最后,用我制作的这个思维导图,以双均线策略为例来梳理一下vn.py对于策略实现以及执行的流程:
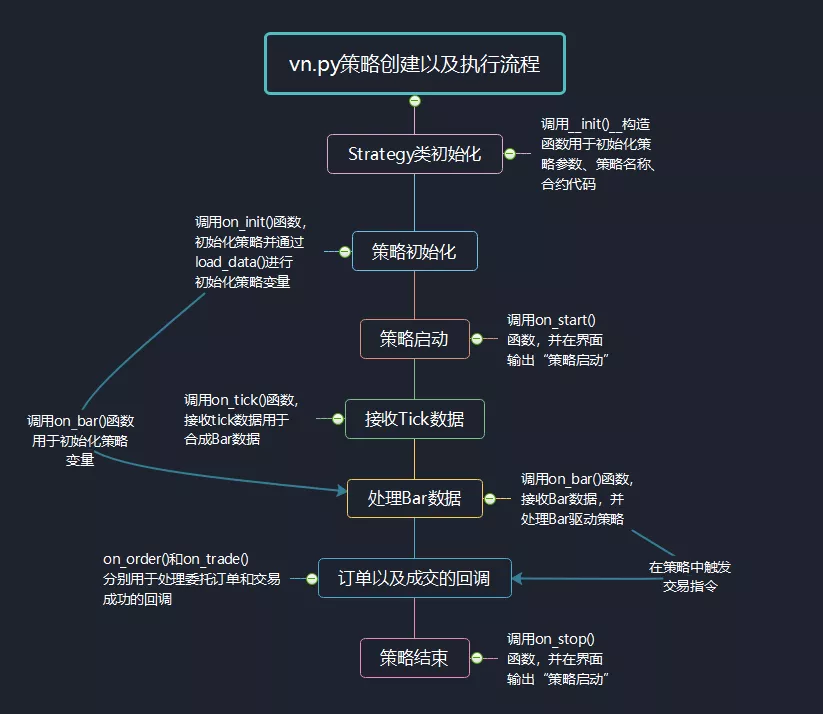
《vn.py全实战进阶》课程全新上线,一共50节内容覆盖从策略设计开发、参数回测优化,到最终实盘自动交易的完整CTA量化业务流程,目前已经更新到第八集,详细内容请戳课程上线:《vn.py全实战进阶》!
了解更多知识,请关注vn.py社区公众号。

上一篇社区精选中,主要解决了如何搭建支持远程桌面的Ubuntu量化交易服务器。有了系统环境,那么本篇的内容就是如何运行和使用vn.py量化平台了。
首先打开vn.py项目的GitHub发布页面
这里包含了vn.py所有发布的正式版本,推荐使用最新版本(左侧会有个Latest release的绿色文字框提示)。点击最新版本下方的的Source Code (zip)链接,来进行下载。
下载完毕后,进入文件目录\root\Downloads,解压zip格式的安装文件。
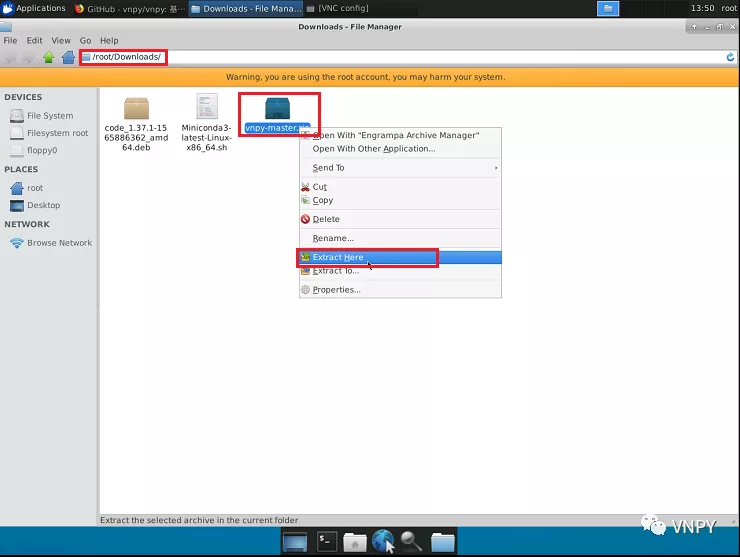
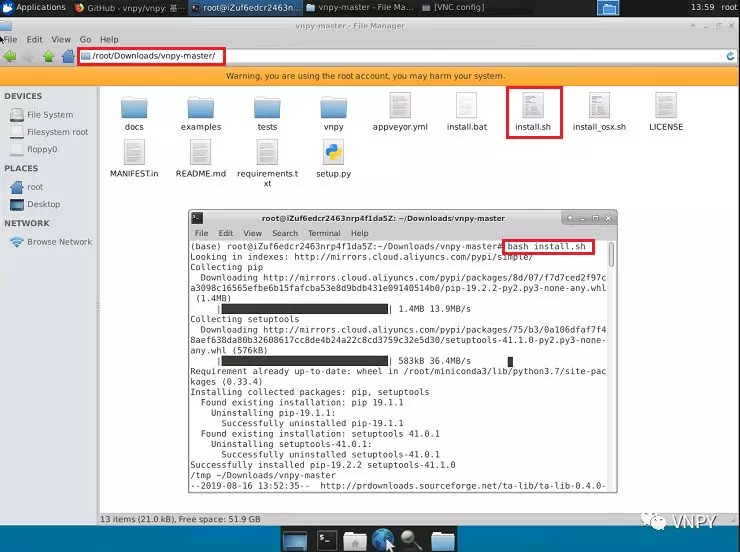
然后进入解压文件目录\root\Downloads\vnpy-xxx(其中xxx是下载的vn.py版本号),在终端中运行安装命令:
bash install.sh
接下来安装脚本会自动进行vn.py以及相关依赖库的安装任务。
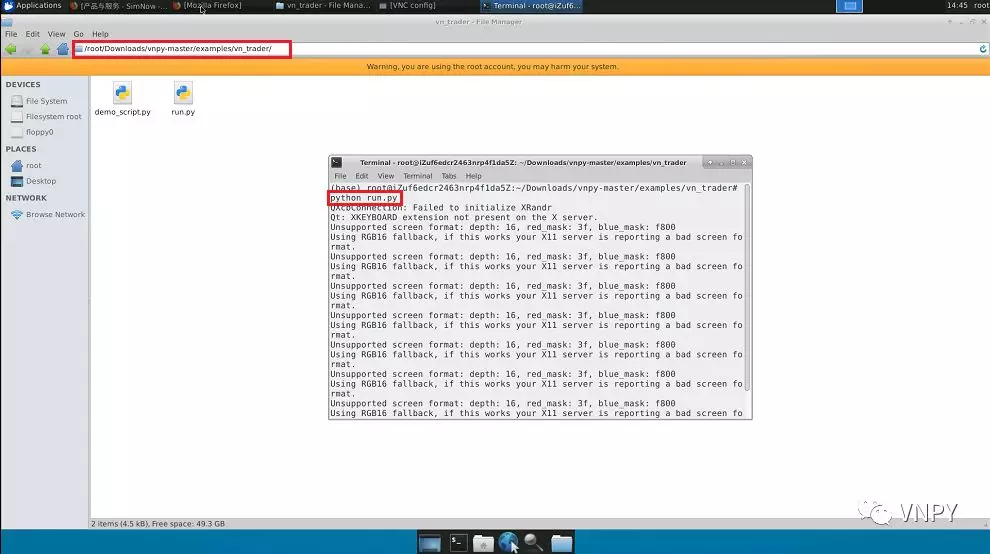
安装完毕后,尝试启动图形化交易界面VN Trader。进入文件目录\root\Downloads\vnpy-xxx\examples\vn_trader,其中的run.py文件就是我们启动VN Trader的程序入口。
通常用户可以根据自己的需求,自行在run.py文件中加载需要使用的底层接口和上层策略应用。这里我们只展示CTP接口的连接,如果需要使用别的接口可以使用VSCode编辑文件自行添加。
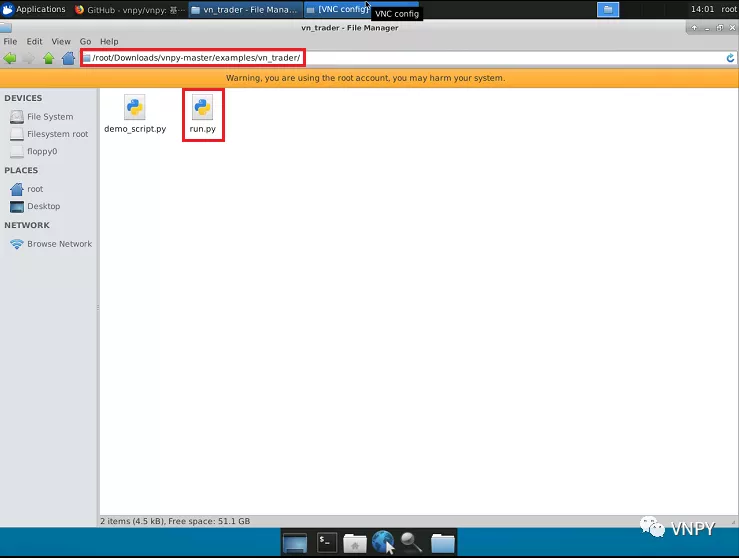
在当前的vn_trader目录下,右键打开终端运行命令,即可启动图形化交易界面VN Trader:
python run.py
注意:如果启动VN Trader时报错说缺少了pyqtgraph和zmq库,直接用pip工具安装即可,在终端中运行命令:
pip install pyqtgraph pyzmq
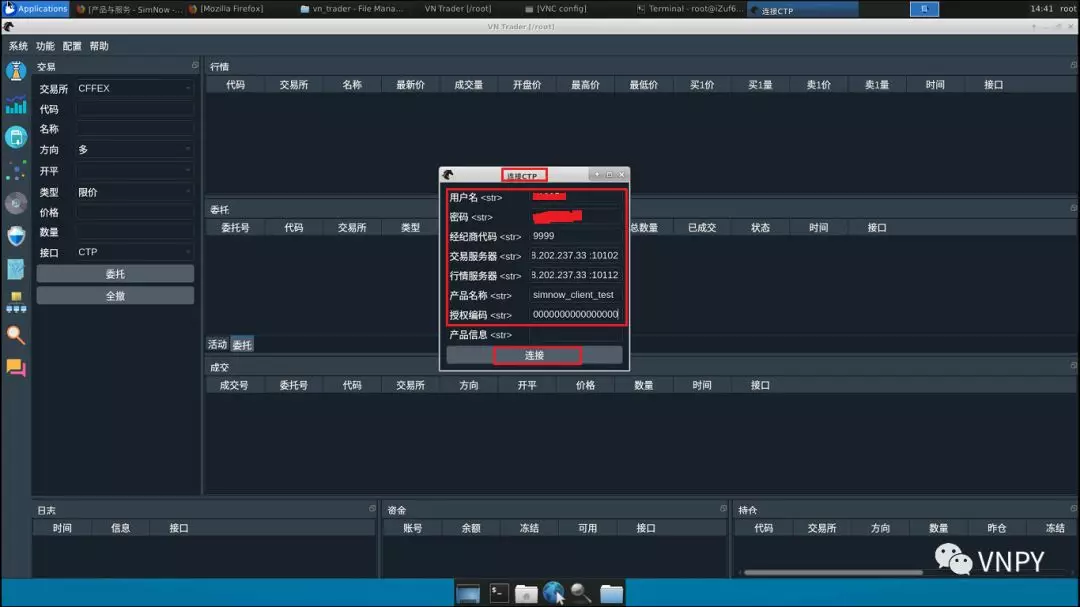
进入VN Trader后,点击菜单栏【系统】->【连接CTP】会弹出CTP账号配置选项。填好账号信息后,点击下方的【连接】按钮即可登陆CTP进行交易。
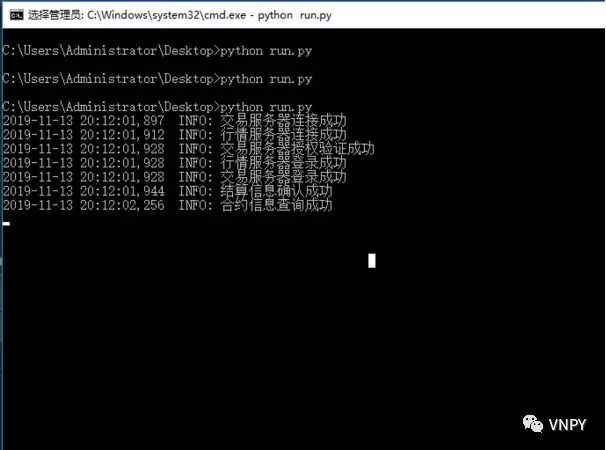
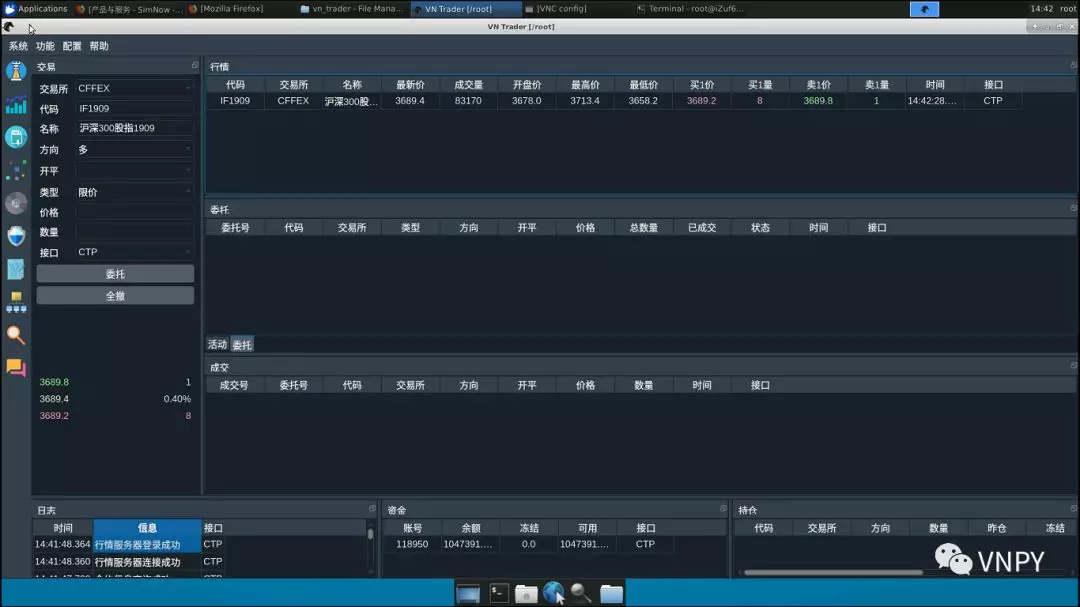
点击“连接”按钮后,左下角的日志信息区域会输出相关的初始化日志信息,看到“合约信息获取成功”的日志后,我们就可以订阅行情推送以及执行委托交易了。
目前2.0版本的vn.py,在Windows系统下可以使用所有的交易接口,而在Ubuntu系统下则只能使用其中的一部分,具体情况如下:
C/C++类接口:CTP、OES
这类原生API接口提供的SDK文件中通常包含:头文件、动态链接库、静态链接库(Windows下)。动态链接库在Windows下为dll文件,而Linux下则为so文件。
理论上,所有提供了so格式动态链接库的C/C++类交易接口,都能支持在Ubuntu上运行,如下图所示的CTP:
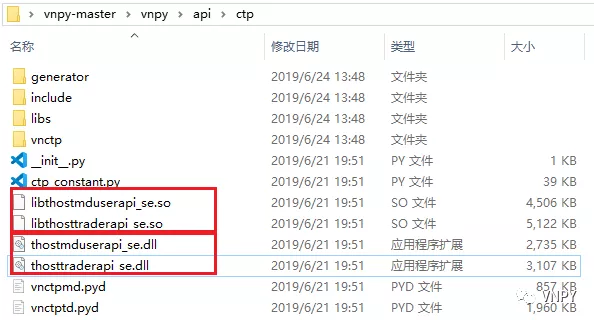
目前由于开发力量上的限制,对于C/C++类接口,vn.py在Ubuntu上只支持CTP和OES两个用户量最大的接口,后续随着2.0版本的功能模块逐步移植完毕,会提供其他接口的支持:TAP、FEMAS、XTP等。
Python类接口:IB、TIGER、FUTU
IB(盈透证券)、TIGER(老虎证券)、FUTU(证券)这三个接口,使用的是其官方提供的纯Python SDK,直接进行接口函数的对接开发。得益于Python本身的跨平台解析性语言特点,这类接口在Ubuntu系统下也能直接使用。
注意:如果只是想要在Ubuntu下使用vn.py做量化,这段内容并不是必须掌握的知识。
对于C++接口的具体编译过程感兴趣的用户(vn.py社区的成员就是这么好学~),可以照着下面的步骤尝试在Ubuntu环境下编译CTP接口。
首先在桌面上创建一个如下结构的目录,其中包含ctpapi文件夹(包含ctp文件夹和init.py)、setup.py、MANIFEST.in。
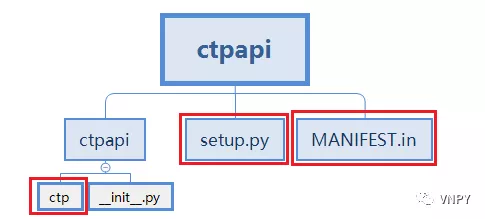
创建好后,需要对红色方框标识的3个文件进行操作:setup.py和MANIFEST.in需要写入新的代码,而ctp文件夹需要放入新的文件。
setup.py是C++ API封装代码的编译的主入口文件,运行后即可生成Linux环境下的动态链接库so文件,或者用于Window环境下的dll文件。具体内容如下:
import platform
from setuptools import Extension, setup
dir_path = "ctpapi"
if platform.uname().system == "Windows":
compiler_flags = [
"/MP", "/std:c++17", # standard
"/O2", "/Ob2", "/Oi", "/Ot", "/Oy", "/GL", # Optimization
"/wd4819" # 936 code page
]
extra_link_args = []
else:
compiler_flags = [
"-std=c++17", # standard
"-O3", # Optimization
"-Wno-delete-incomplete", "-Wno-sign-compare", "-pthread"
]
extra_link_args = ["-lstdc++"]
vnctpmd = Extension(
# 指定 vnctpmd 的位置
"ctpapi.ctp.vnctpmd",
[
f"{dir_path}/ctp/vnctp/vnctpmd/vnctpmd.cpp",
],
# 编译需要的头文件
include_dirs=[
f"{dir_path}/ctp/include",
f"{dir_path}/ctp/vnctp",
],
# 指定为c plus plus
language="cpp",
define_macros=[],
undef_macros=[],
# 依赖目录
library_dirs=[f"{dir_path}/ctp/libs", f"{dir_path}/ctp"],
# 依赖项
libraries=["thostmduserapi_se", "thosttraderapi_se", ],
extra_compile_args=compiler_flags,
extra_link_args=extra_link_args,
depends=[],
runtime_library_dirs=["$ORIGIN"],
)
vnctptd = Extension(
"ctpapi.ctp.vnctptd",
[
f"{dir_path}/ctp/vnctp/vnctptd/vnctptd.cpp",
],
include_dirs=[
f"{dir_path}/ctp/include",
f"{dir_path}/ctp/vnctp",
],
define_macros=[],
undef_macros=[],
library_dirs=[f"{dir_path}/ctp/libs", f"{dir_path}/ctp"],
libraries=["thostmduserapi_se", "thosttraderapi_se"],
extra_compile_args=compiler_flags,
extra_link_args=extra_link_args,
runtime_library_dirs=["$ORIGIN"],
depends=[],
language="cpp",
)
if platform.system() == "Windows":
# use pre-built pyd for windows ( support python 3.7 only )
ext_modules = []
# if you really want to build it . please check your environment (没测试过)
# ext_modules = [vnctptd, vnctpmd]
elif platform.system() == "Darwin":
ext_modules = []
else:
ext_modules = [vnctptd, vnctpmd]
pkgs = ['ctpapi', 'ctpapi.ctp']
install_requires = []
setup(
name='ctpapi',
version='1.0',
description="good luck",
author='somewheve',
author_email='####',
license="MIT",
packages=pkgs,
install_requires=install_requires,
platforms=["Windows", "Linux", "Mac OS-X"],
package_dir={'ctpapi': 'ctpapi/'},
package_data={'ctpapi': ['ctp/*', ]},
ext_modules=ext_modules,
classifiers=[
'Development Status :: 4 - Beta',
'Intended Audience :: Developers',
'License :: OSI Approved :: MIT License',
'Programming Language :: Python :: 3.7',
]
)
MANIFEST.in用于指明所有需要导入的文件,其代码如下:
# include MANIFEST.in
include README.md
recursive-include ctpapi/ctp *
对于原本空空如也的ctp文件夹,我们进行以下复制操作:
对MANIFEST.in、setup.py、ctp目录处理完毕后,就可以开始进行编译了:
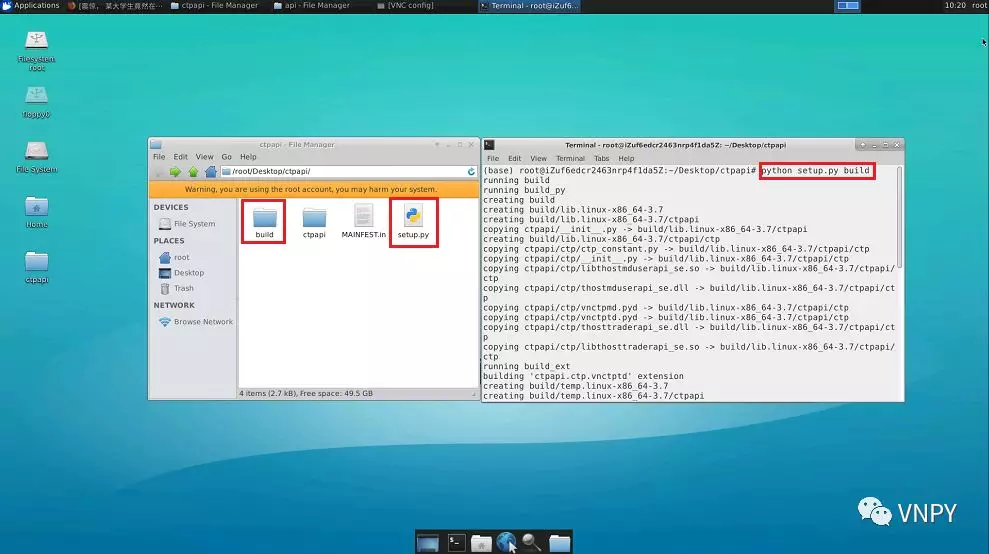
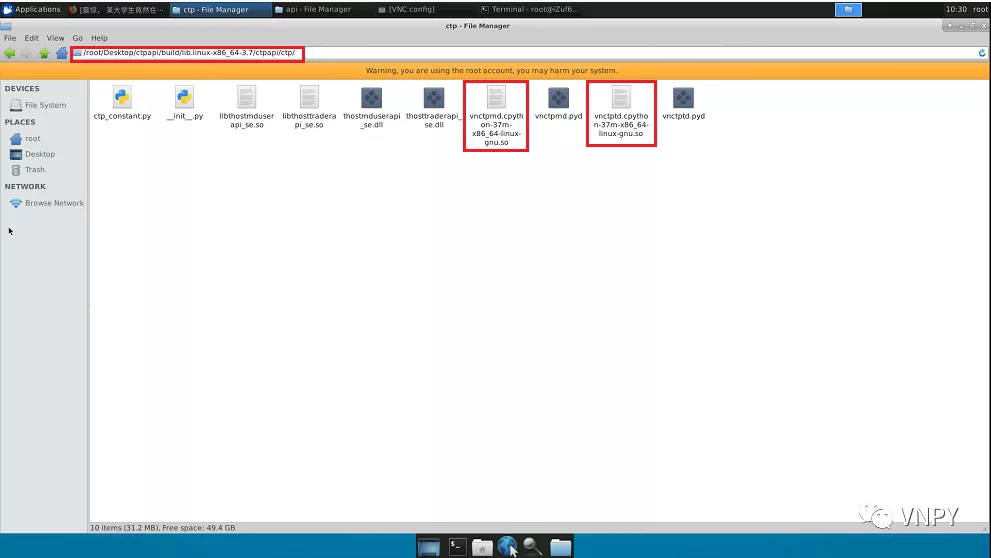
打开build文件夹,在build/ctpapi/build/lib.linux-x86_64-3.7/ctpapi/ctp里面,可以看到两个so文件:vnctpmd.cpython-37m-x86_64-linux-gnu.so和 vnctptd.cpython-37m-x86_64-linux-gnu.so,这两个Linux下的动态链接库就是已经编译完成的CTP API封装,可以直接在Python中加载使用了。
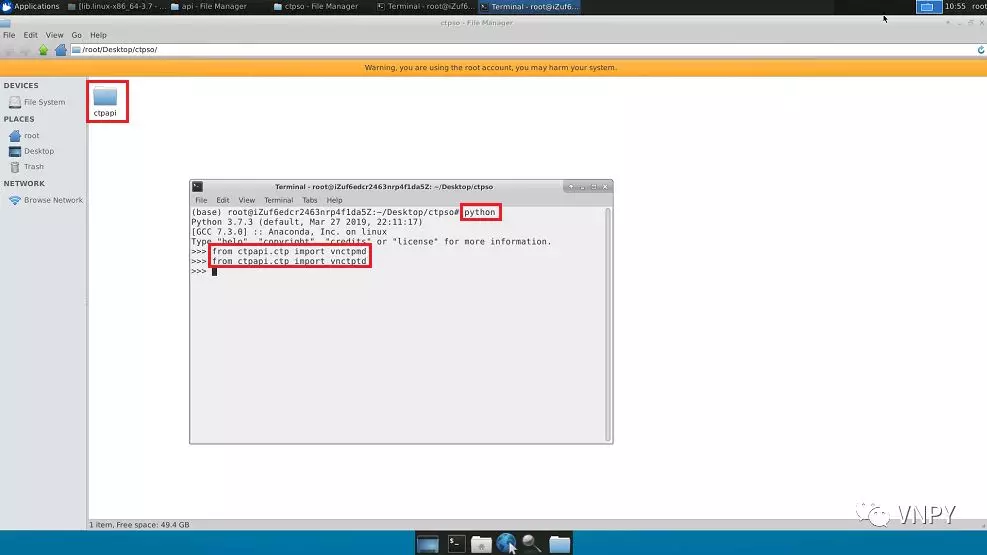
编译好后,为了检验有效性,可以试试看能否在Python解释器中导入vnctpmd和vnctptd两个模块:
from ctpapi.ctp import vnctpmd
from ctpapi.ctp import vnctptd
了解更多知识,请关注vn.py社区公众号。

对于vn.py的初学者以及绝大部分用户来说,Windows操作系统可能是比较好的选择,性能满足需求而且也几乎没有额外的学习成本。但不可否的是,Linux操作系统在系统资源占用、扩展服务开发、跨进程通讯延时等方面,有着明显的优势。
社区内也一直不乏用户希望尝试学习使用Linux,常见的两种形式包括:
本篇教程就主要针对如何在阿里云服务器上搭建一套完整的Linux量化交易系统环境来讲解。Linux版本上选择了vn.py官方支持的Ubuntu 18.04 LTS 64位版本,如果要使用Debian、CentOS等可以自行尝试,整体大同小异。
主要用到的工具包括MobaXterm(远程连接客户端)、Xubuntu-destop(服务器图形界面)、vnc4server(远程桌面服务)等,尽管安装配置的过程有些繁琐,但只要跟着图文说明一步步去做,100%能成功。
在开始安装工作前,请先准备好1台阿里云的服务器(也可以选择AWS、腾讯云等):
购买好后请记录下该服务器的公网IP,下面连接要用。
MobaXterm是一款增强型远程连接工具,可以轻松地调用远端Linux服务器上的各项功能命令。接下来将会用到MobaXterm的SSH和VNC功能:
首先,需要从官网下载MobaXterm:
https://mobaxterm.mobatek.net/download-home-edition.html
下载完成后解压安装包,直接双击exe文件进行安装。
安装完成后,双击桌面图标启动MobaXterm。在主界面中单击导航栏左边第一个【Session】进入连接页面。
或者也可以点击顶部菜单栏【Sessions】->【New Session】按钮。
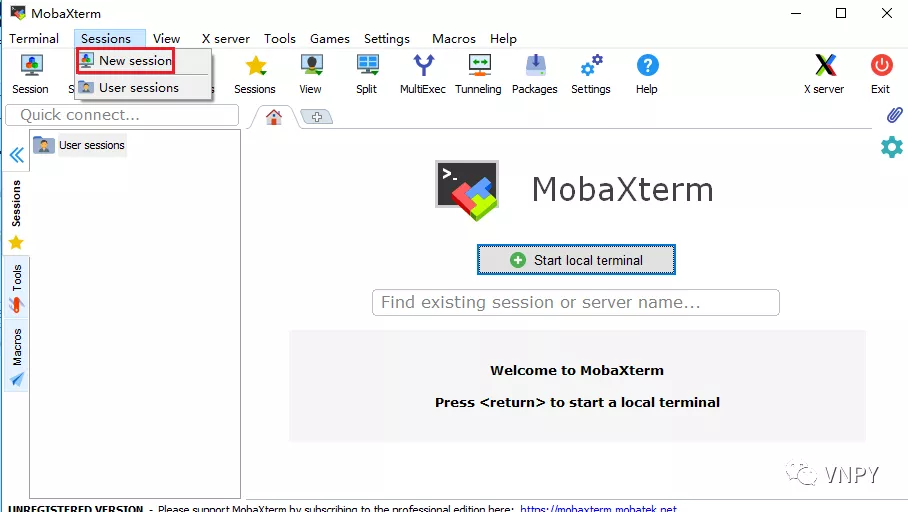
在弹出的新页面Session Settings中,单击导航栏最左边的【SSH】按钮。然后在Basic SSH settings中输入云服务器的公网IP和账号。
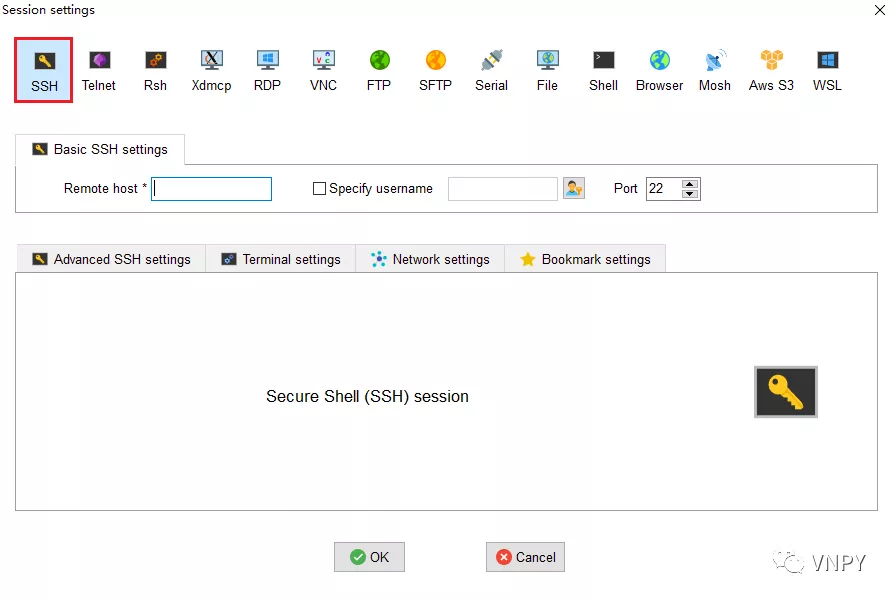
其中默认账号为root,输入root账号之前记得把左边小方框勾选上,端口号保留默认的22即可,然后点击最下方的【OK】按钮。
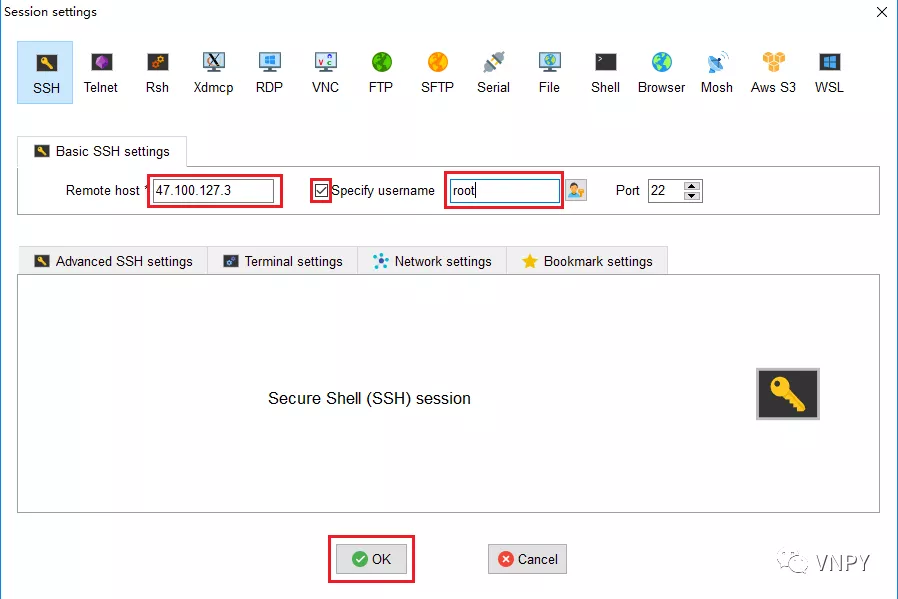
之后会自动弹出一个新的连接页面,第一次连接时右侧终端会提示输入云服务器的密码,注意在输入时,界面上并不会有任何反应(不会显示密码)。
输入完按回车键后,若密码正确则会弹出一个小窗口提示是否保存密码,可以点击【Yes】按钮。
看到下图中显示的内容,就说明阿里云的Ubuntu服务器已经连接成功了。左边显示的是云服务器上的文件夹目录,右边的黑框是命令操作界面。
到这里,我们就完成了使用MobaXterm远程连接云服务器的步骤。当然,这种连接是基于SSH,只能通过命令行终端的方式来调用服务器上的各项功能。
为了更方便的管理连接,需要进行一下重命名:点击最左侧的【Session】选项,找到刚刚创建的SSH连接,鼠标右键选定该连接,选择【Rename session】。
弹出Session settings界面,其中的Session name可以修改为任意名称,这里我们将其重命名为DEV_1,完成后点击左下方的【OK】保存。
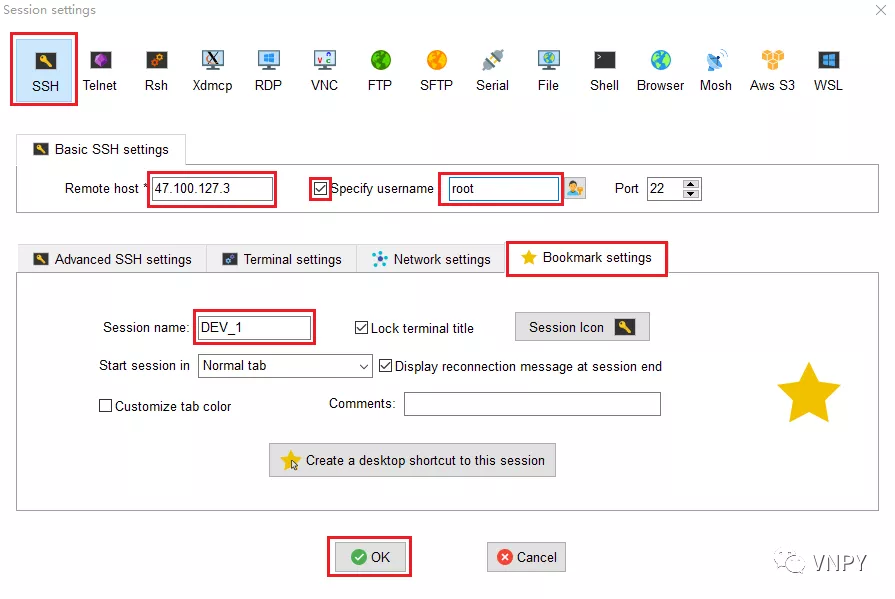
此时在左侧的Sessions标签中,我们可以看到该连接的名称已经改为了DEV_1。
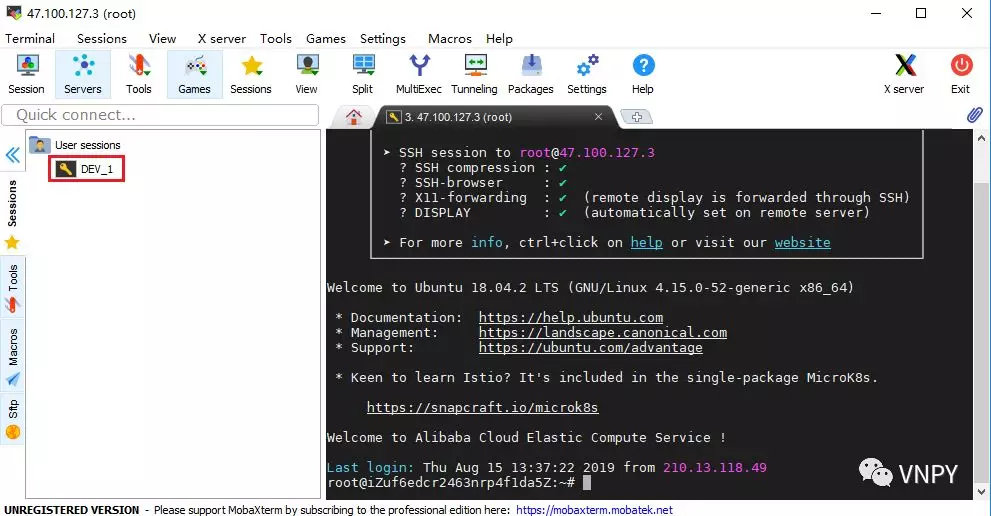
同理重复上面的操作,输入相同的云服务器的公网IP和账号,创建第二个SSH连接(命名为DEV_2),这样我们就能同时使用2个终端了,同理你也可以创建更多的终端连接。
在Windows下安装软件,通常只需要准备好安装包的exe文件,然后一路点击【下一步】即可完成。但Linux并非如此,Linux系统的发行版大多自带了软件包管理器,如Ubuntu和Debian的APT。
对于大部分常用的软件,用户都可以直接从官方提供的仓库中下载安装需要的软件,而不必自己去每个网站下载,这也是Linux与Windows在使用上的一大区别。
所以在Ubuntu系统中,本地保存了一个软件包安装源列表,列表里面都是一些网址信息,标识着某个源服务器上有哪些软件可以安装使用。所以为了能够正常安装最新版本的软件,首先需要更新软件包管理器里的这些列表。
只需要在Ubuntu终端中,运行输入命令
sudo apt-get update就会如上图所示,自动遍历访问源列表中的每个网址,并读取最新的软件信息,保存在本地系统中。
Xfce是一款针对Linux/UNIX系统的现代化轻量级开源桌面环境,优点是内存消耗小,且系统资源占用率很低,Linux之父Linus Torvalds日常使用的桌面环境就是Xfce。
Xfce只是纯粹的桌面环境,但我们在日常使用操作系统时,还需要许多其他常用的工具,如多国语言支持、浏览器、输入法工具等。Xubuntu-desktop就是一套整合了Xfce桌面环境和其他常用图形界面软件的安装包。
安装方法也相对简单,在终端中运行命令:
sudo apt-get install xubuntu-desktop
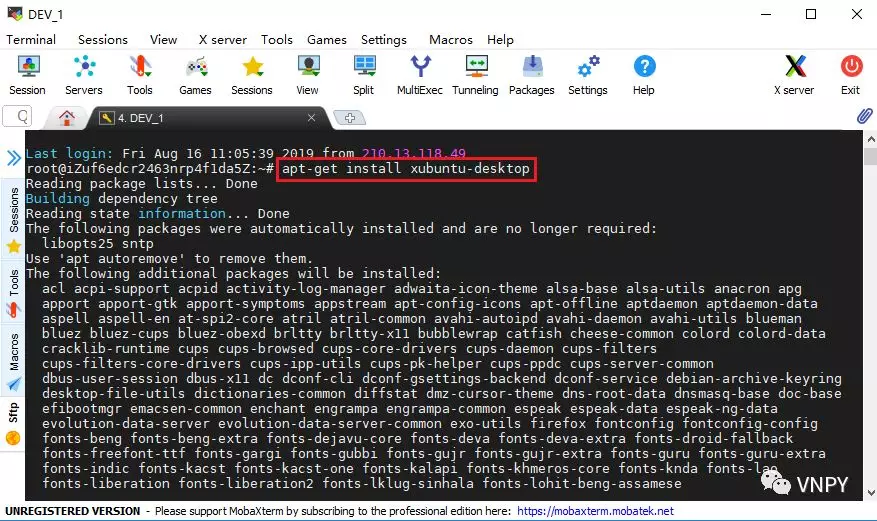
在国内当前的网络环境下,Xubuntu-desktop的下载和安装可能耗时在20-60分钟的样子,期间可以在终端中看到类似上图所示的安装信息。
VNC是一款基于RFB协议的屏幕画面分享及远程操作软件,主要特色在于跨平台性:我们可以用Windows电脑来控制Linux系统,反之亦然。
首先需要安装VNC服务器,在终端下运行命令:
sudo apt-get install vnc4server
安装完毕后,在终端运行命令
vncserver
用来启动VNC服务器。首次运行时需要设置VNC远程连接的密码,长度至少是6位,并且二次输入来确认(注意该密码不是Ubuntu账户的密码)。
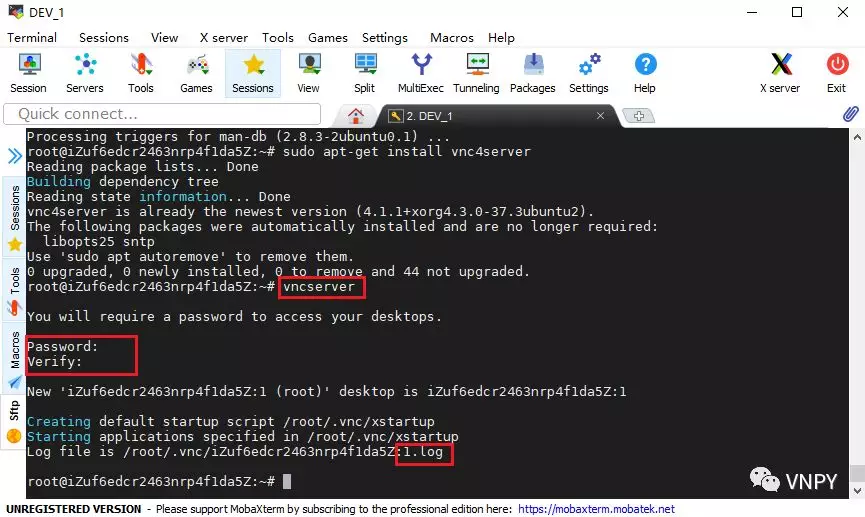
VNC服务器启动好后,可以在日志输出文件名中看到其默认端口是1,上图所示红色方框标识“:1”。
启动了远程桌面服务器后,下一步是配置xstartup文件,来设置远程桌面使用Xfce的桌面环境。用文本编辑器nano打开xstarup文件,在终端运行命令:
nano ~/.vnc/xstartup
可以看到如下内容:
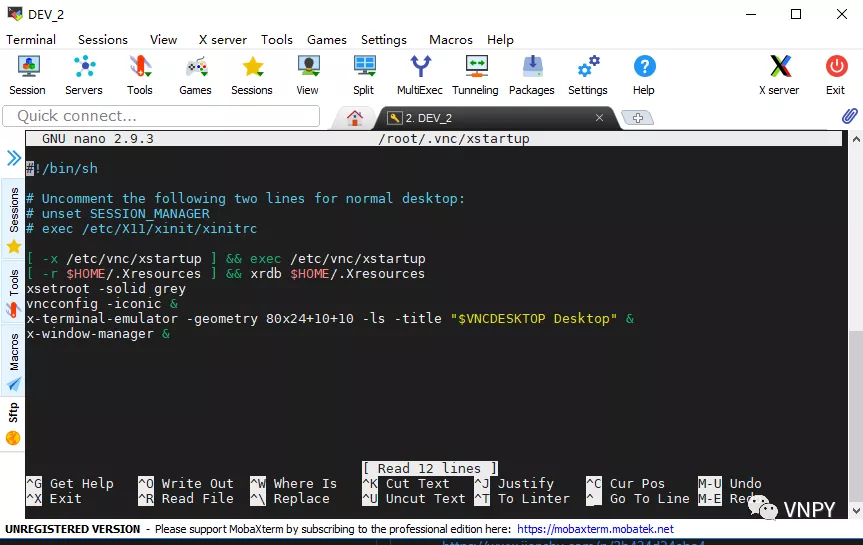
需要在最后一行 "x-window-manager &" 前面添加一个"#"注释掉这行,同时在文件最后加入一段新的配置信息:
session-manager & xfdesktop & xfce4-panel &
xfce4-menu-plugin &
xfsettingsd &
xfconfd &
xfwm4 &
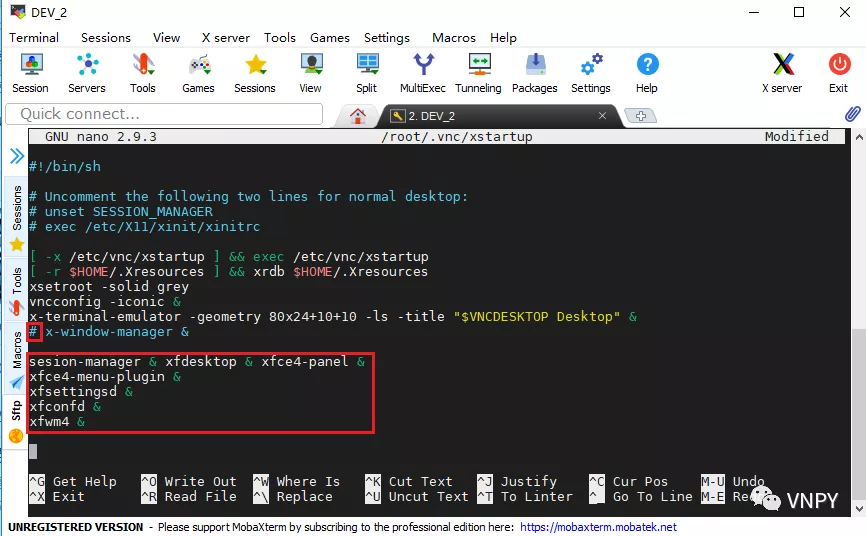
修改完毕后,按住“Ctrl”和“Y”键来退出nano编辑器,注意会询问是否要保存当前修改,请按“Y”进行保存。
配置完xstartup后,我们需要重启VNC服务器:先把默认的1号端口服务杀掉,然后新的服务我们改为使用9号端口(因为1号端口容易被扫描攻击),同时设置远程桌面的分辨率为1920x1080(根据你的本地显示器分辨率来设),运行下列命令:
vncserver -kill :1
vncserver -geometry 1920x1080 :9
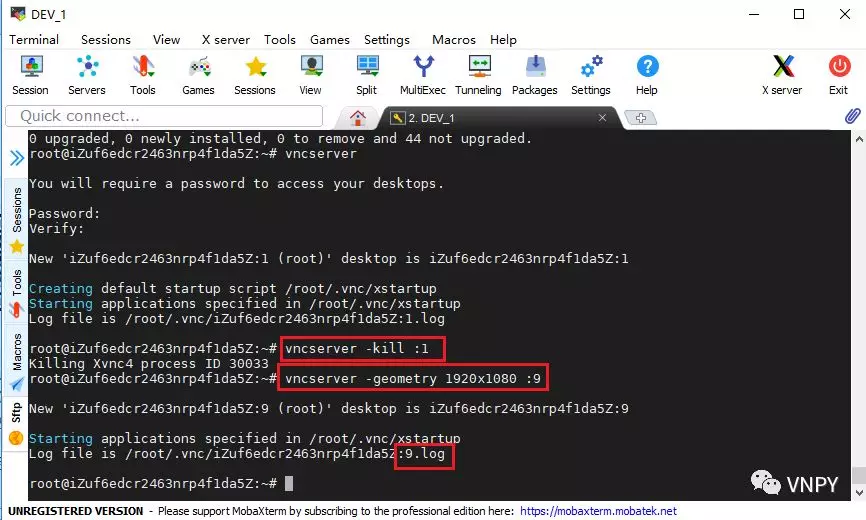
回到MobaXterm主界面,单击主页最上边的【Sessions】->【new Session】弹出【Sessions settings】界面,这一次选择【VNC】连接。
其中【IP address】为阿里云公网IP,【Port】为VNC连接端口,在上一段中我们选择了在9号端口启动,故从需要把Port端口由默认的5900调整为5909。
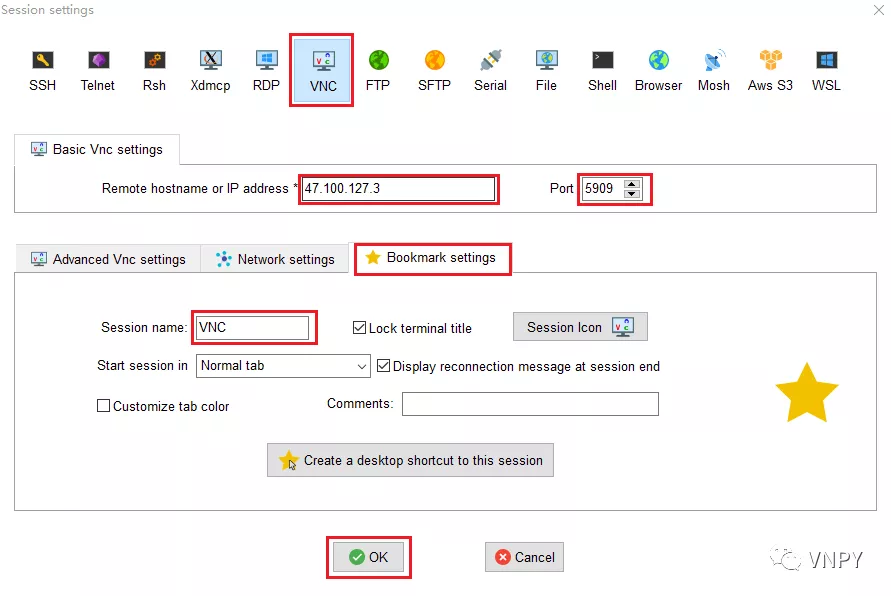
同时在下面的【Bookmark settings】界面对该VNC连接进行重命名为“VNC”,点击左下方的【OK】按钮,开始连接VNC远程桌面,成功后即可看到如下图所示的Xfce图形界面:
作为中国人总归免不了要输入中文,这里我们选择安装IBus中文拼音输入法,在终端中运行命令:
sudo apt install ibus-pinyin
安装完成后,还需要先配置下Ubuntu系统的中文语言包:

设置完中文语言包后,进入IBus输入法设置:

既然要写程序那就还需要一套IDE工具,同样这里我们使用vn.py官方推荐的Visual Studio Code(VSCode),作为微软出品的轻量级代码编辑器,在Linux下的安装和使用也同样非常方便。
打开Visual Studio Code的官网:https://code.visualstudio.com/

在官网首页点击下载.deb版本:
Ubuntu下的deb格式安装包,需要用使用dpkg命令来安装。进入下载文件所在的目录/root/Downloads,鼠标在空白处右键点击【Open Terminal Here】进入终端:

输入下面命令安装:
sudo dpkg -i code_1.37.0-1565227985_amd64.deb
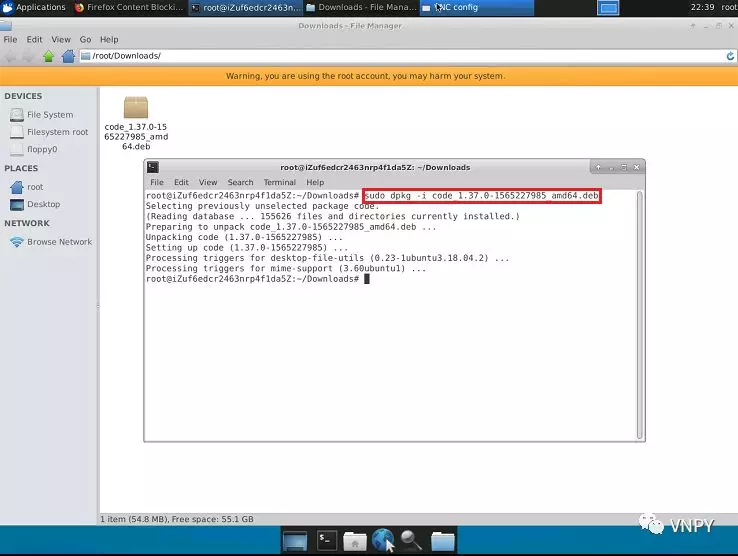
安装完成后会发现VSCode不能正常启动,因为Xfce和VSCode的默认设置存在兼容性问题,需要手动配置,在终端中运行下面命令:
sudo sed -i 's/BIG-REQUESTS/_IG-REQUESTS/' /usr/lib/x86_64-linux-gnu/libxcb.so.1
再次尝试启动VSCode,已经可以正常打开运行,注意上述命令输入运行后界面没有任何输出。
Ubuntu 18.04系统中内置了Python 2.7和3.6,并且输入python命令时默认启动的是Python2.7。
但v2.0版本的vn.py则是基于Python 3.7,如果安装新的Python 3.7版本,则需要把新安装的Python 3.7设置为系统默认的Python环境,同时将pip命令也指向Python 3.7的版本。
手动进行上述命令的重新定向容易导致各种问题,所以这里我们选择使用Minconda(Python 3.7 64位)。作为有名的Python科学计算发行版本Anaconda的轻量小弟,安装完成后会自动设置其内部的Python 3.7为系统默认环境。
打开Minconda官网,选择【Linux】系统的Python 3.7【64-bit】版本下载:
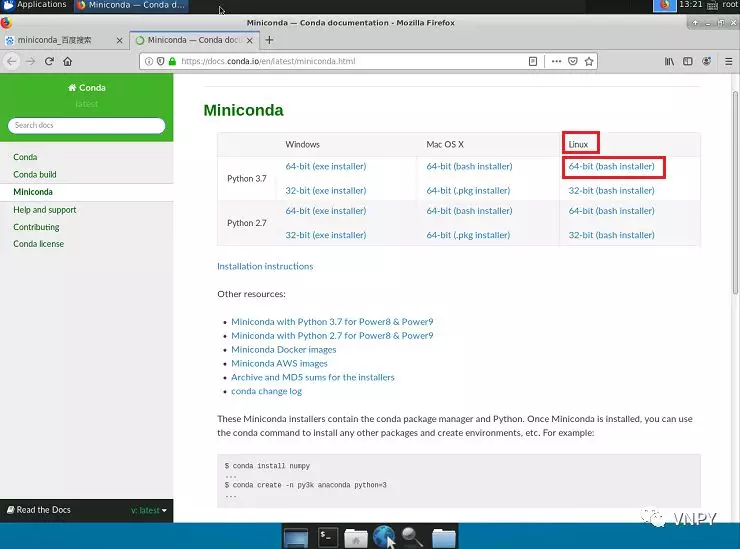
下载完成后,进入文件所在目录/root/Downloads可以看到.sh格式的Miniconda安装包,鼠标在空白处右键,点击【Open Teminal Here】进入终端,然后输入命令进行安装:
bash Miniconda3-latest-Linux-x86_64.sh
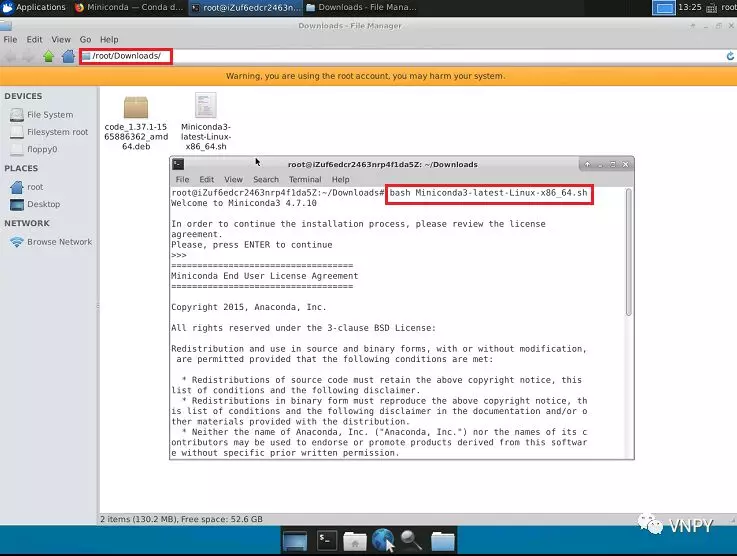
安装完毕后,在终端运行Python,可以看到当前的版本已经变成Python 3.7:
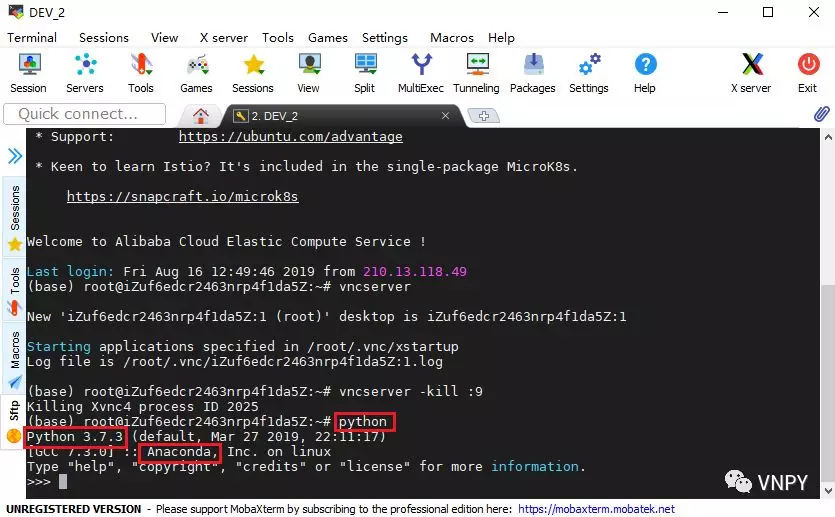
折腾至此,终于完成我们的目标:支持远程图形桌面的阿里云Ubuntu量化交易服务器~~未来Linux使用熟练后,也同样可以选择关闭图形界面,以纯命令行的形式来运行vn.py的自动交易功能。
了解更多知识,请关注vn.py社区公众号。

新的vn.py社区论坛已经上线差不多大半年的时间,许多社区用户都贡献了非常高质量的量化交易相关内容。接下来我们计划每周整理一篇论坛中的精华文章,制作为一个《vn.py社区精选》系列。
每篇文章我们会先争得作者的转载同意,同时支付200元的稿费。稿费金额数字不大,更多是对每位作者为vn.py社区做出贡献的一份感谢,也欢迎大家在论坛上更多分享自己的使用经验!
从执行方式上,编程语言可分为2类,编译型语言和解释型语言:
尽管在分类上属于解释型语言,Python在实际运行时为了提高效率,同样会先从源代码(py文件)编译为字节码文件(pyc文件),而后在运行时通过解释器再来解释为机器指令执行。第二次运行该Python文件时,解释器会在硬盘中寻找到事先编译过的pyc文件,若找到则直接载入,否则就重新生成pyc文件。
但无论是py文件还是pyc文件,都有极高的风险泄露源代码:
无论是谁,都不会希望自己辛辛苦苦开发的量化策略被任何第三方窃取,因此自然而然就产生了对策略文件进行加密的需求:对py文件加密,生成可以正常加载运行,但无法被反编译的pyd文件(在Linux上为.so文件)。
作为Python语言的子集,Cython主要被用来解决Python代码中的运行效率瓶颈问题,如numpy底层的矩阵运算加速,期权的实时定价模型等等。
除了加速功能外,Cython也提供了一整套Python语言的静态编译器,可以将Python源代码转换成C源代码,再编译成pyd二进制文件(本质上是dll文件)。
尝试用VSCode打开一个编译生成的pyd文件:
可以看到内容全都是不可读的二进制乱码,从而实现了我们需要的代码加密功能。
尽管听起来有点复杂,Cython的实际操作却非常非常简单,装好工具后只需要一条命令就能完成所有编译工作,所以完全不用紧张,照着下面的傻瓜教程一步步操作就好。
安装Visual StudioComunity 2017,下载地址:
https://visualstudio.microsoft.com/zh-hans/vs/older-downloads/
安装时请勾选“使用C++的桌面开发”,如下图所示:
在Python环境中安装Cython,打开cmd后输入运行pip install cython即可:

创建一个新的文件夹Demo,把需要加密的策略(如demo_strategy)复制到该文件夹下:

在Demo文件夹下,按住“Shift”+ 鼠标右键,点击“在此处打开命令窗口(或者Powershell)”进入cmd,输入以下命令来进行编译:
cythonize -i demo_strategy.py
随后Cython工具会自动执行C代码的生成和编译工作,输出类似下图中的一系列日志信息:
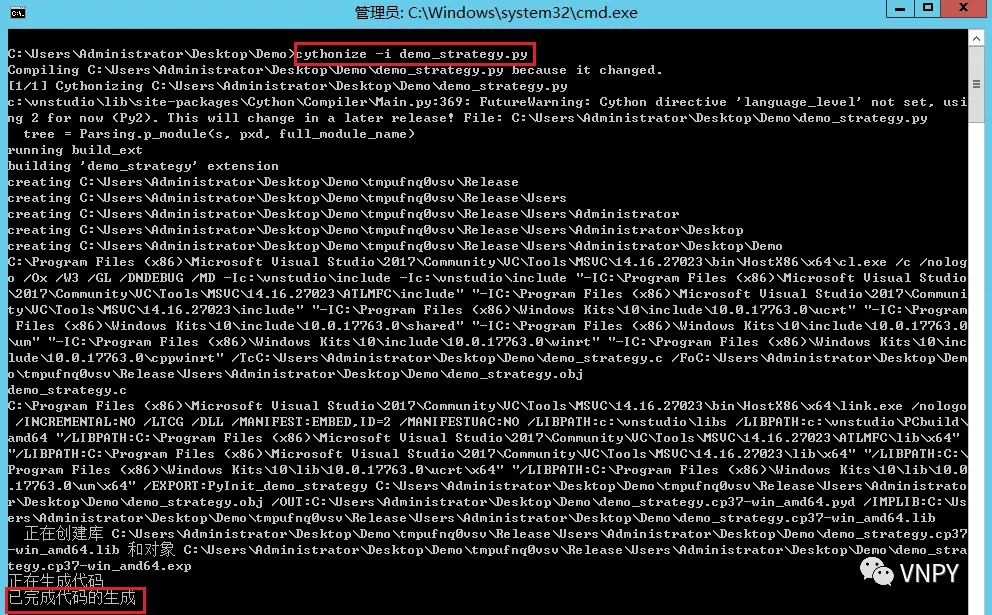
编译完成后,Demo文件夹下会多出2个新的文件,其中就有已加密的策略文件demo_strategy.cp37-win_amd64.pyd:

在操作系统的用户目录下(如C:\Users\Administrator\),创建strategies文件夹,用于存放用户自己开发的的策略文件。将上一步生成的demo_strategy.cp37-win_amd64.pyd,放到此处即可运行:
启动VN Trader后,进入CTA策略模块即可看到加密后的DemoStrategy策略已经正常识别并加载到了系统中:
了解更多知识,请关注vn.py社区公众号。

跑完了历史数据回测和优化,得到了一个不错的回测资金曲线,最后就可以准备开始实盘交易了。在教程2-5中我们已经接触了真实账户和仿真账户的概念,这里强调一个原则:
所有量化策略在开始真金白银交易之前,都应该经过仿真账户的充分测试,毕竟每个人交易的本金都来之不易,一定要有十分负责的态度。
本篇教程我们继续以股指期货为例,其他产品的量化策略实盘也基本都一样。首先启动VN Trader Pro,加载CTP接口以及CTA策略模块(CtaStrategy),或者也可以直接运行VN Trader Lite。
进入VN Trader主界面后,连接登录CTP接口,等待日志组件中看到“合约信息查询成功”的信息输出。
随后,点击菜单栏的“功能”->“CTA策略”,或者左侧导航栏里的国际象棋棋子的图标,看到CTA策略实盘交易的窗口:
此时在右下方的日志监控组件中,可以看到“RQData数据接口初始化成功”的信息,如果没有的话请照着上一篇教程里的方法,配置RQData数据服务。
接下来要基于之前开发好的策略模板(类),来添加策略的实例(对象),点击右上角的策略下拉框,找到DemoStrategy:

点击添加策略按钮,出现策略实盘参数配置的对话框:
每个参数字段,后面的<>括号中说明了该字段对应的数据类型,注意必须根据要求填写,否则实例创建会出错。
首先我们要给策略实例一个名字,也就是strategy_name字段,注意每个实例的名称必须唯一,不能重复。
然后需要指定策略具体要交易的合约,通过本地代码vt_symbol来指定(合约代码 + 交易所名称)。注意在上一篇教程中我们回测使用的是RQData提供的股指连续合约数据IF88.CFFEX,该合约只是为了方便回测而人工合成的数据,在实盘交易系统中并不存在。在实盘中,需要指定具体的交易合约,一般选择该期货品种当前流动性最好的月份,比如写本文时是2019年8月3日,此时的股指主力合约为IF1908.CFFEX。
fast_window和slow_window是策略里写在parameters列表中的参数名,这里我们填入上一篇教程中优化后的结果18和90。
点击“添加”按钮后,在左侧的策略监控组件中,就能看到该策略实例了:
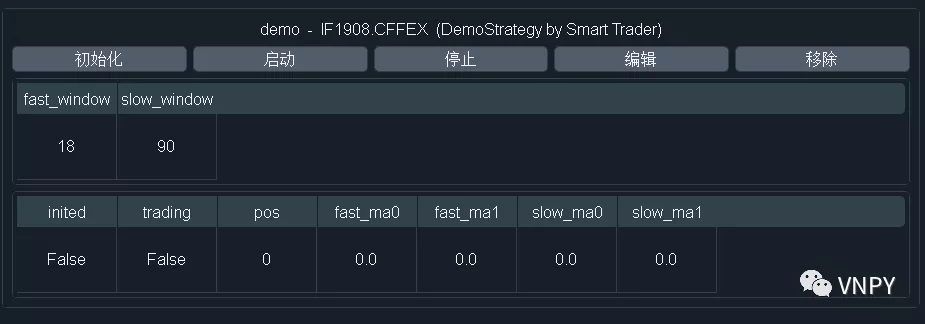
顶部按钮用于控制和管理策略实例,第一行表格显示了策略内部的参数信息,第二行表格则显示了策略运行过程中的变量信息(变量名需要写在策略的variables列表中)。inited字段表示当前策略的初始化状态(是否已经完成了历史数据回放),trading字段表示策略当前是否开始交易。
注意上方显示的所有变量信息,需要在策略中调用put_event函数,界面上才会进行数据刷新。有时用户会发现自己写的策略,无论跑多久这些变量信息都不动,这种情况请检查策略中是否漏掉了对put_event函数的调用。
点击监控组件顶部的“初始化”按钮,此时内部的CTA策略引擎会先调用策略的on_init函数,运行用户定义的逻辑,随后按照顺序完成以下三步任务。
首先是载入该合约最新的历史数据,具体载入数据的长度,通过策略内部的load_bar函数的参数控制。数据载入后会以逐根K线(或者Tick)的方式推送给策略,实现内部变量的初始化计算,比如缓存K线序列、计算技术指标等。
在载入时,CTA策略引擎会优先通过RQData来获取历史数据,RQData的数据服务提供盘中K线更新,因此即使在9点45分才启动策略,也能获取到之前从9点30开盘到9点45分之间的K线数据提供给策略进行初始化计算,而不用担心数据缺失的问题。
如果RQData不支持该合约(比如外盘期货),CTA策略引擎则会尝试使用交易接口进行获取。对于IB接口来说,交易的服务端系统提供了相应的历史数据下载功能。
最后,如果交易接口也获取不到,那么CTA策略引擎会访问本地数据库来加载历史数据。这种情况下,用户需要自己来保证数据库中的数据完整性(满足需求),比如通过DataRecorder录制,使用CsvLoader从CSV文件载入,或者使用其他数据服务(比如万得宏汇等)来更新。
量化策略在每天实盘运行的过程中,有些变量纯粹只和行情数据相关的,这类变量通过上一步的加载历史数据回放就能得到正确的数值。另一类变量则可能是和交易状态相关的,如策略的持仓、移动止损的最高价跟踪等,这类变量需要缓存在硬盘上(退出程序时),第二天回放完历史数据后再读取还原,才能保证和之前交易状态的一致性。
在CtaStrategy中这一步骤对于用户来说是几乎无感的,每次关闭程序时会自动将每个策略的variables列表对应的变量写入json文件(缓存在.vntrader目录下的cta_strategy_data.json中),并在下一次策略初始化时自动载入。
注意在某些情况下,可能缓存的数据出现了偏差(比如手动平仓了),此时可以通过手动修改json文件来调整。
最后是获取该策略所交易合约的信息(基于vt_symbol),并订阅该合约的实时行情推送,如果找不到该合约的信息,比如没有登录接口或者vt_symbol写错了,则会在日志模块中输出相应的报错信息。
注意对于IB接口来说,因为登录时无法自动获取所有的合约信息,只有在用户手动订阅行情时才能获取,因此需要在主界面上先行手动订阅该合约行情,然后再点击“初始化”按钮。
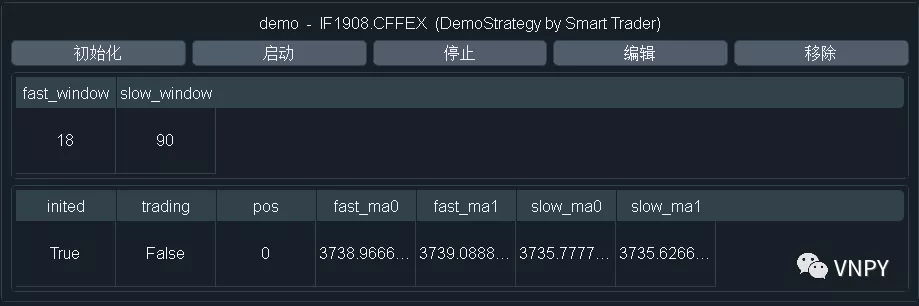
以上三个步骤全部完成后,策略的inited状态变为True,且变量也都有了对应的数值(不再为0),则说明初始化已经完成。
完成策略初始化后(inited状态为True时),才可以点击“启动”按钮启动策略的自动交易功能:
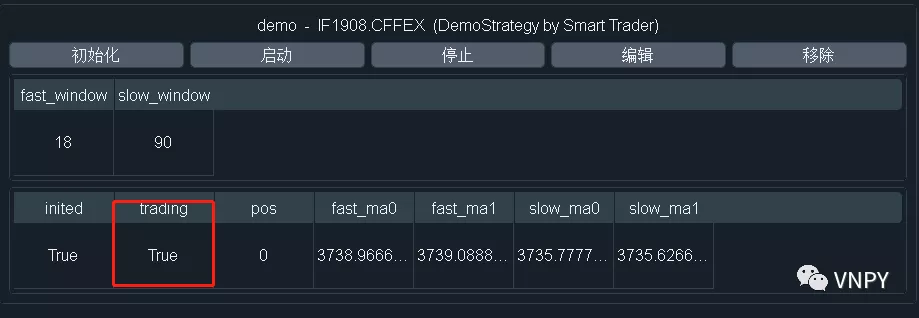
当trading状态为True时,策略内部的交易请求类函数(buy/sell/short/cover/cancel_order等),以及信息输出类函数(write_log/send_email等),才会真正执行并发出对应的请求指令到底层接口中(真正执行交易)。
在上一步策略初始化的过程中,尽管策略同样在接收(历史)数据,并调用对应的功能行数,但因为trading状态为False,所以并不会有任何真正的委托下单操作或者日志信息输出。
到了市场收盘时间,或者盘中遇到紧急情况时,点击“停止”按钮即可停止策略的自动交易。
CTA策略引擎会自动将该策略之前发出的所有活动委托全部撤销(保证在策略停止后不会有失去控制的委托存在),同时执行上面提到过的变量缓存操作。
这两步都完成后,策略的trading状态会变为False,此时可以放心的关闭程序了。
在CTA策略的实盘交易过程中,正常情况应该让策略在整个交易时段中都自动运行,尽量不要有额外的暂停重启类操作。对于国内期货市场来说,应该在夜盘时段开始前,启动策略的自动交易,然后直到第二天下午收盘后,再关闭自动交易,中间的夜盘收盘属于同一交易日内,无需停止策略。
跑量化策略的过程中,有时可能需要调整策略的参数,点击策略监控组件上的“编辑”按钮,即可在弹出的参数编辑对话框中任意修改参数:
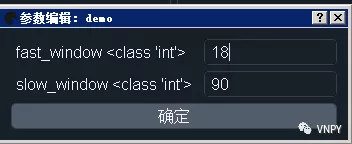
点击确定按钮后相应的修改会立即更新在参数表格中,注意策略实例的交易合约代码无法修改,同时修改完后也不会重新执行初始化操作。
为了安全起见,请一定要在trading状态为False时(自动交易停止),才进行参数的编辑操作。
想要删除某个策略实例时,点击“移除”按钮,CTA策略引擎会自动完成该策略实例的对象销毁和内存释放,并在GUI图形界面上移除其监控组件,此时该策略的名称(strategy_name)也可以再次使用。注意只能移除trading状态为False的策略实例,如果策略已经启动了自动交易功能需要先停止。
在每天的实盘交易中,如果存在比较多的策略实例,可以通过右上角的“全部初始化”、“全部启动”和“全部停止”三个按钮,来一次性对所有的策略实例进行相应的操作管理,避免开盘前点几十下“启动”,收盘后点几十下“停止”的重复劳动。
当日志监控组件中的信息条数过多时,可以点击右上角的“清空日志”按钮来清空其中已有的信息。
最后还剩没提到的就是右上方区域的停止单(Stop Order)监控组件,该组件用来跟踪所有CTA引擎内的本地停止单状态变化,具体用法请参考官网文档。
实盘交易中除了每天机械的启动和关闭策略外,更重要的是对每天策略运行交易结果的跟踪和总结:逻辑运行和回测是否一致、实盘成交和回测假设的滑点偏差有多少等等,并用这些观察到的结果数据,去修正回测研究中用到的参数假设,从而才能实现自己策略研究水平的迭代进步。
了解更多知识,请关注vn.py社区公众号。


