xiaohe wrote:
连接的是ctp接口还是ctptest接口呢?
是在做穿透式测试还是连接实盘?
有用no_ui下的run.py跑过吗?
1.
ctp接口。
2.
之前一直是用vnpy2.2.0版本,在windows(本地电脑)和Ubuntu18.04(服务器)上一直有做实盘交易。
目前这次是更新到3.7.0版本,在windows(本地电脑)上测试没有问题,但是在新开的Ubuntu22.04(服务器)上出现了授权回调失败的问题。
3.
windows和Ubuntu上都是用no_ui的run.py版本测试的。
环境
操作系统: Ubuntu 22.04
Python版本: Python3.10
VeighNa版本: 3.7
Issue类型
三选一:Bug
预期程序行为
正常回调
实际程序行为
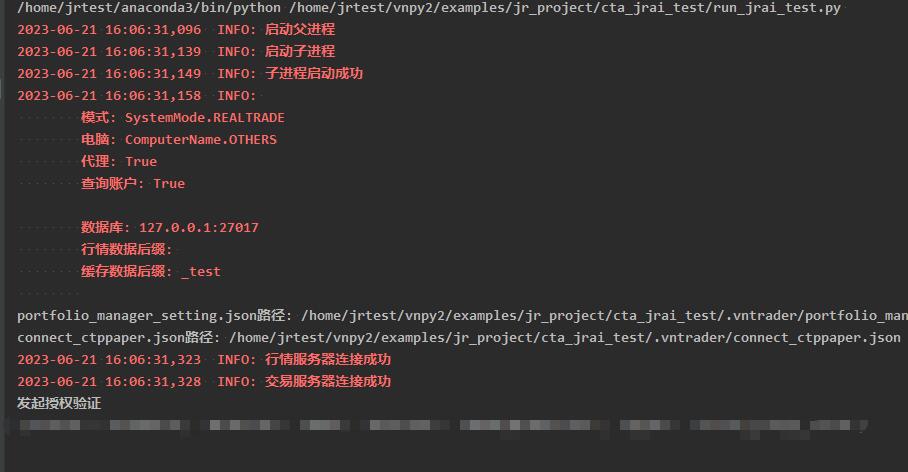
相同的代码,在windows正常运行,但是在Ubuntu下出现如下问题:
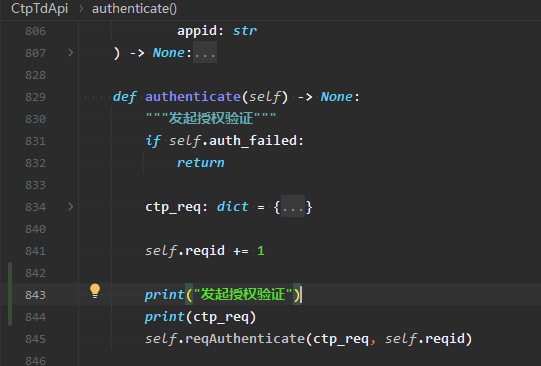
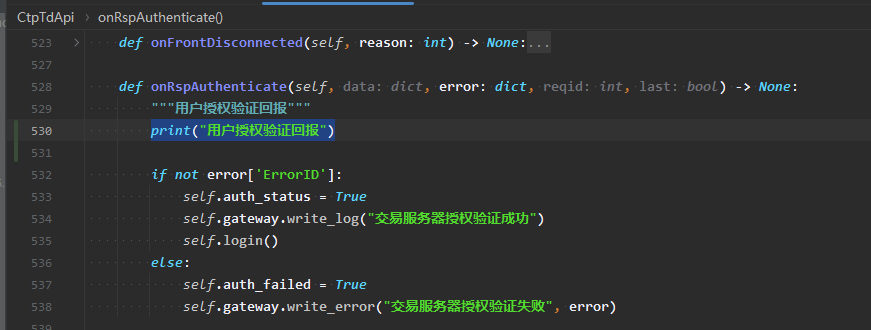
发起授权验证CtpTdApi.authenticate()后,没有回调CtpTdApi.onRspAuthenticate(),导致直接卡死。
同问,需要上github开个需求吗?
问题1:
为什么在strategy与algo中都有send_order,二者在应用场景上有什么区别?
strategy.send_order在strategy.buy/sell处调用,而strategy.buy/sell则是完全没用被调用过。
问题2:
目前套利程序貌似还不能实现在多个spread里使用相同的vt_symbol做leg,或者与其他策略(如CTA)一起使用相同的vt_symbol,会把leg的order, trade, position混在一起处理(无论是update_order/trade/position还是初始化时)
建议做一下区分,以防止出现持仓混淆的情况:
1.在send_order时根据order_id映射到对应的strategy
2.在process_order/trade/position里按strategy保存到数据库,同时推送到对应的strategy/algo里
3.在初始化时读取对应strategy的order, trade, position
用Python的交易员 wrote:
确实这是之前设计中的一个不足之处,请开个issue吧,我们后续来处理
2.1.0里,bar模式回测时有设置了trade.value,但是tick模式好像还是原来的版本?
像时变协整套利等策略,需要动态变化price_multiplier, trading_multiplier等参数,但是这些参数都在StDataEngine里add_strategy时根据json读取的,那应该如何在strategy端调整?以及怎么进行持久化保存参数?
有些时候需要人工干预仓位时,感觉还是需要这个功能的,因为人手填写的话时效性有点低
我记得在原vnpy1.92版是具有这个功能,是vnpy2.09版移除了这个功能,还是我的程序出了BUG?
例如:对vnpy2.06进行了大量的定制化开发(如策略、参数、资金管理、风控等)后,当官方更新到2.09后,如何用git安全地合并最新的官方版本?
有什么方案是比较推荐的?
知乎上也有类似的问题:https://www.zhihu.com/question/23736465
用Python的交易员 wrote:
这个问题我们之前Google搜索过,没有找到解决方案,猜测和zmq底层的某种机制有关
我在RpcClient.stop()里加上sleep(5)就没有出现这个问题了。可能跟结束太快有关?
def stop(self):
"""
Stop RpcClient
"""
if not self.__active:
return
# Stop RpcClient status
self.__active = False
# Close socket
sleep(5)
self.__socket_req.close()
self.__socket_sub.close()在读套利模块源码时,有几个有疑惑的地方
问题一:
在legData.update_trade()里,为什么不需要处理new_pos<0的情况?
如果trade没有完全把旧仓位给平掉,那么不是会产生new_pos < 0的情况吗?
还是说直接默认了算法里会直接把旧仓位给全平?
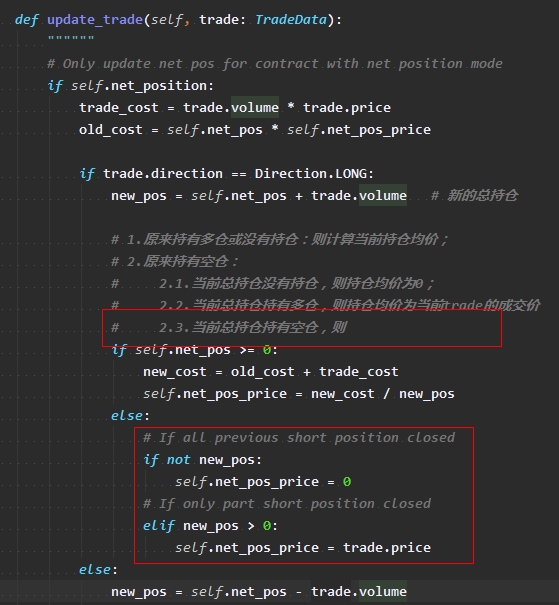
问题二:
1.leg.net_position是根据contract.net_pos来获得的,而contract.net_pos包含了账户其他策略的净持仓,这样是否会跟其他策略的持仓混淆?
2.leg.net_pos_price是根据position.price来获得的,同样的也包含了账户其他策略的持仓的持仓价,这样是否会跟其他策略的持仓混淆?
问题三:关于套利模块的设计
为什么不采用类似CTA的递进层级设计(st_engine - st_strategy - st_algo),而是使用平行式的层级设计?
stengine - dataengine
- strategyEngine - st_strategy
- algoEngine - st_algo
我在使用过程中感觉第一种更容易管理和理解,而第二种虽然稍微灵活一点但是更加复杂且容易出错,所以有点疑惑为什么要采用这种设计?
关于第1个问题的回答,还是想再请教一下。
SQL里全放在一个collection下,这点没有问题。
但在MongoDB里,全放在一个collection下,一是数据量变大后,读取会非常缓慢;二是建了索引或者用update插入,写入的速度也会变慢。
在兼容SQL时,是否需要根据MongoDB和SQL的特性进行区分以提高效率?
3.还有一个问题就是,1.9.2会把CTA策略持久化保存的数据存在数据库,而2.0.7则是把持久化数据放在本地。
万一主服务器发生宕机,则备份服务器无法读取主服务器的策略数据,相比1.9.2,这个改动不利于多个服务器交互或者灾备,这么改动的理由是什么?
1.相比1.9.2,为什么2.0.7的数据记录要把所有品种都放在同一个collection下?就算建了索引,但相比1.9.2的按品种分collection的方法,新版这种做法不是会导致数据插入和读取非常缓慢吗?
2.vnpy 2.0.7的exe安装版和github上的master,为什么有很多代码都不一样?两者不是用同一个版本的吗?