
发布于veighna社区公众号【vnpy-community】
原文作者:用Python的交易员 | 发布时间:2023-11-10
2023年第7场VeighNa社区活动开始报名,本场活动将在成都举办,分享主题是【基于Scikit-Learn的机器学习CTA策略信号挖掘实践】。
之前北京场的活动现场座无虚席,大家的热情程度远超我们预期,附上一张北京场的活动照片:

机器学习(Machine Learning)各种算法在量化交易领域中的应用越发广泛,但由于目前互联网上的资料质量参差不齐,许多VeighNa社区的同学想要学习尝试但却不知道从何入手。
本次活动中,我们将会由浅入深介绍机器学习技术在CTA量化策略开发中的应用场景,并基于Scikit-Learn这款广受好评的机器学习算法库,给出一套具体的CTA策略信号挖掘实践案例:
KBins聚类特征分析
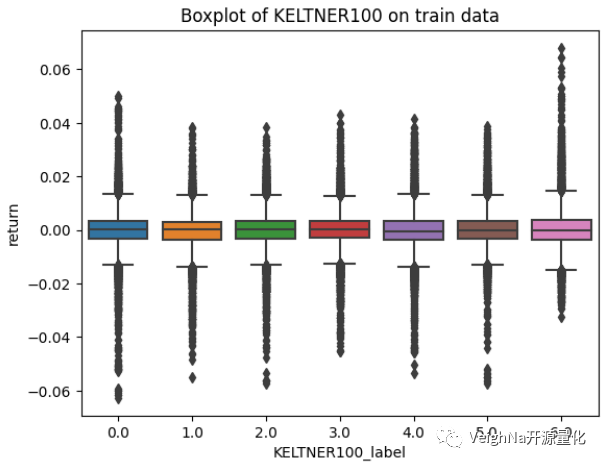
特征相关性热力图
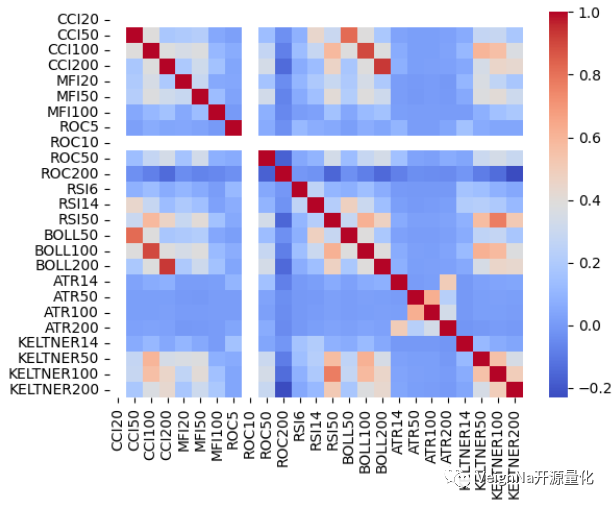
向量化回测绩效图

本场活动仅提供线下参会名额(预估40人位置),还是优先对金融机构量化从业人员开放,请在填写报名表单时提供公司和职位信息,后续报名成功的同学小助手会添加微信联系确认。
内容:
机器学习在量化中的应用场景
基于Scikit-Learn的实践案例
其他近期社区感兴趣的主题
QA问答和交流环节
时间:12月2日 14:00-17:00
地点:成都(具体地址后续在微信群中通知)
报名费:99元(Elite会员免费参加)
报名方式:扫描下方二维码报名(请在付款前填写报名信息表)

发布于veighna社区公众号【vnpy-community】
原文作者:用Python的交易员 | 发布时间:2023-10-30
2023年第6场VeighNa社区活动开始报名,本场活动将在上海举办,分享主题是【基于Scikit-Learn的机器学习CTA策略信号挖掘实践】。
上周北京场的活动现场座无虚席,大家的热情程度远超我们预期,所以上海场就早点开始报名了!附上一张北京场的活动照片:
机器学习(Machine Learning)各种算法在量化交易领域中的应用越发广泛,但由于目前互联网上的资料质量参差不齐,许多VeighNa社区的同学想要学习尝试但却不知道从何入手。
本次活动中,我们将会由浅入深介绍机器学习技术在CTA量化策略开发中的应用场景,并基于Scikit-Learn这款广受好评的机器学习算法库,给出一套具体的CTA策略信号挖掘实践案例:
KBins聚类特征分析
特征相关性热力图
向量化回测绩效图
本场活动仅提供线下参会名额(预估40人位置),还是优先对金融机构量化从业人员开放,请在填写报名表单时提供公司和职位信息,后续报名成功的同学小助手会添加微信联系确认。
内容:
机器学习在量化中的应用场景
基于Scikit-Learn的实践案例
其他近期社区感兴趣的主题
QA问答和交流环节
时间:11月25日 14:00-17:00
地点:上海(具体地址微信确认后通知)
报名费:99元(Elite会员免费参加)
报名方式:扫描下方二维码填写表单报名(报名成功小助手会添加微信联系确认)

发布于veighna社区公众号【vnpy-community】
原文作者:用Python的交易员 | 发布时间:2023-10-17
2023年第5场VeighNa社区活动开始报名,本场活动将在北京举办,分享主题是【基于Scikit-Learn的机器学习CTA策略信号挖掘实践】。
机器学习(Machine Learning)各种算法在量化交易领域中的应用越发广泛,但由于目前互联网上的资料质量参差不齐,许多VeighNa社区的同学想要学习尝试但却不知道从何入手。
本次活动中,我们将会由浅入深介绍机器学习技术在CTA量化策略开发中的应用场景,并基于Scikit-Learn这款广受好评的机器学习算法库,给出一套具体的CTA策略信号挖掘实践案例:
KBins聚类特征分析
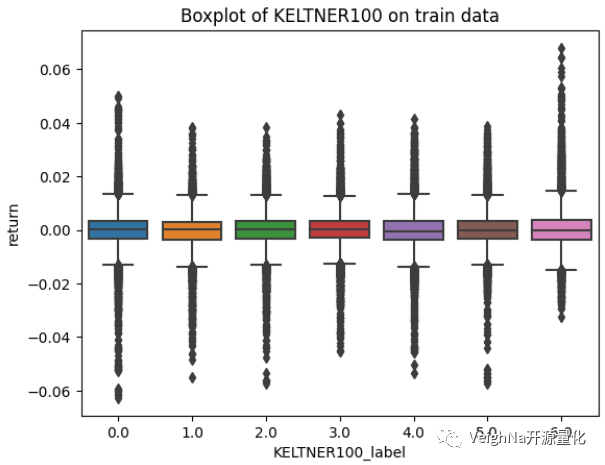
特征相关性热力图
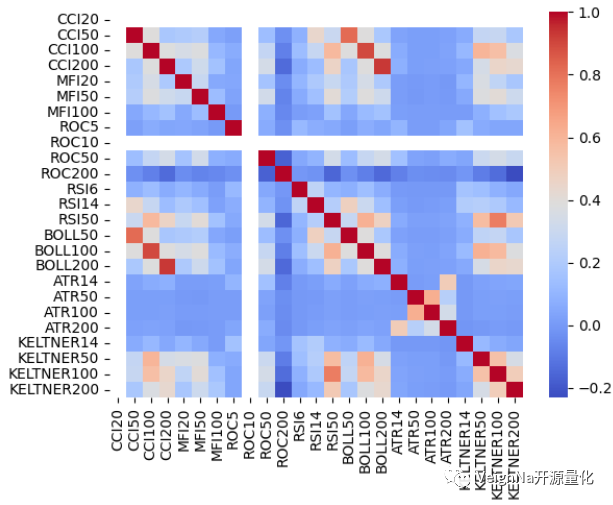
向量化回测绩效图
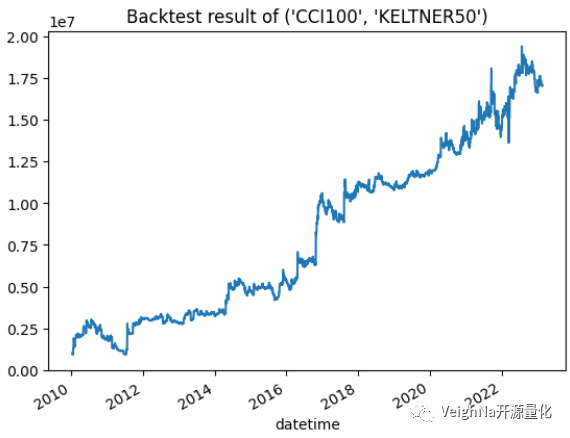
本场活动仅提供线下参会名额,同时因为北京场地有限(目前预估30人位置),还是优先对金融机构量化从业人员开放,请在填写报名表单时提供公司和职位信息,后续报名成功的同学小助手会添加微信联系确认。
内容:
机器学习在量化中的应用场景
基于Scikit-Learn的实践案例
其他近期社区感兴趣的主题
QA问答和交流环节
时间:10月28日 14:00-17:00
地点:北京(具体地址微信确认后通知)
报名费:99元(Elite会员免费参加)
报名方式:扫描下方二维码填写表单报名(报名成功小助手会添加微信联系确认)

发布于vn.py社区公众号【vnpy-community】
原文作者: 丛子龙 | 发布时间:2023-10-13
RSI相对强度指数是技术分析中常用的指标之一,由J. Welles Wilder Jr.在其1978年的著作《技术交易系统的新概念》中开发并引入技术分析中使用。RSI衡量价格变动的速度和幅度,该指标绘制在0到100的范围内。
许多技术分析类的书籍中常常见到将RSI用于均值回归交易,为人熟知的用法之一是在RSI超过70时卖出资产,当RSI跌破30时买入资产。然而,RSI也可以用作动量趋势指标,比如在上升趋势中,RSI通常在40到80之间波动,在下降趋势中在20到60之间波动。
本篇文章将会介绍三套围绕RSI构建的多头短线择时策略(策略思路来源于【QuantifiedStrategies】网站),分别是:
1. RSI经典策略
2. RSI区域动量策略
3. RSI-IBS策略
在文章的结尾,我们将会组合上述三个策略中的核心信号,构建一个新的RSI多信号集成策略,并在SPY(标普500ETF基金)和IF(沪深300股指期货)上进行回测。
由于【QuantifiedStrategies】网站文章中主要使用了SPY的日线数据进行回测,以下回测结果也基于同样数据:
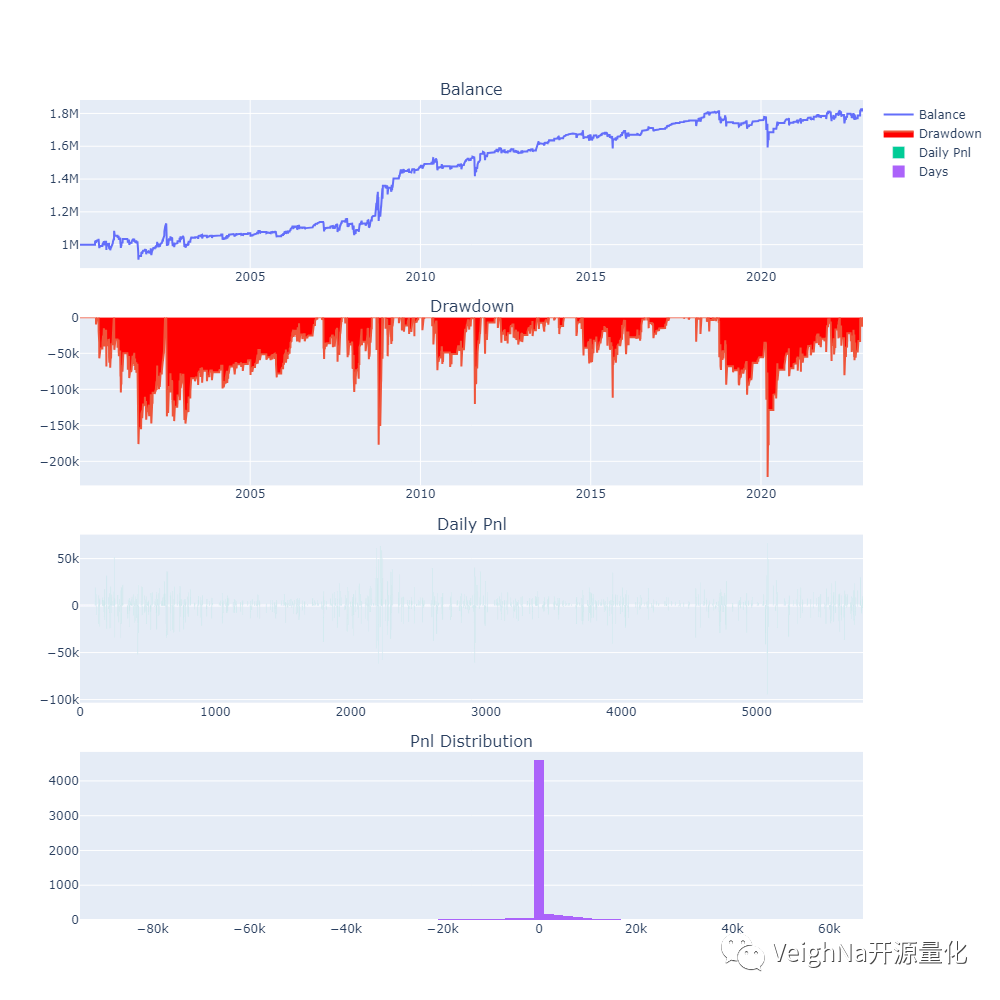

策略的核心思想是在市场情绪低迷时,买入以寻求市场反弹,然后在价格触及昨日高点时卖出:
class RsiStrategy(CtaTemplate):
"""经典RSI策略"""
# 计算RSI指标的窗口
rsi_window: int = 2
# RSI低阈值
rsi_lower: int = 15
# 持仓周期限制
max_holding: int = 9
# 风险资金
risk_capital: int = 1_000_000
parameters = [
"rsi_window",
"rsi_lower",
"max_holding",
"risk_capital",
]
variables = []
def on_init(self):
"""
Callback when strategy is inited.
"""
self.write_log("策略初始化")
self.bg = BarGenerator(self.on_bar)
self.am = ArrayManager()
# 加载足够的历史数据来计算指标
self.load_bar(60)
def on_bar(self, bar: BarData):
"""
K线数据推送
"""
# 撤销之前发出的委托
self.cancel_all()
am = self.am
am.update_bar(bar)
if not am.inited:
return
# 计算RSI指标
rsi_value = am.rsi(self.rsi_window)
# 保存昨日高点
prev_high = am.high[-1]
# 判断是否要进行交易
long_signal = rsi_value <= self.rsi_lower
# 计算每次交易的头寸
self.trading_size = int(self.risk_capital / am.close[-1] / 100) * 100
# 如果无持仓,且满足条件,则直接开仓
if self.pos == 0 and long_signal:
self.buy(bar.close_price * 1.05, self.trading_size)
# 如果持仓,且满足条件,则直接平仓
if self.pos > 0:
self.sell(prev_high, self.pos)
# 推送UI更新
self.put_event()
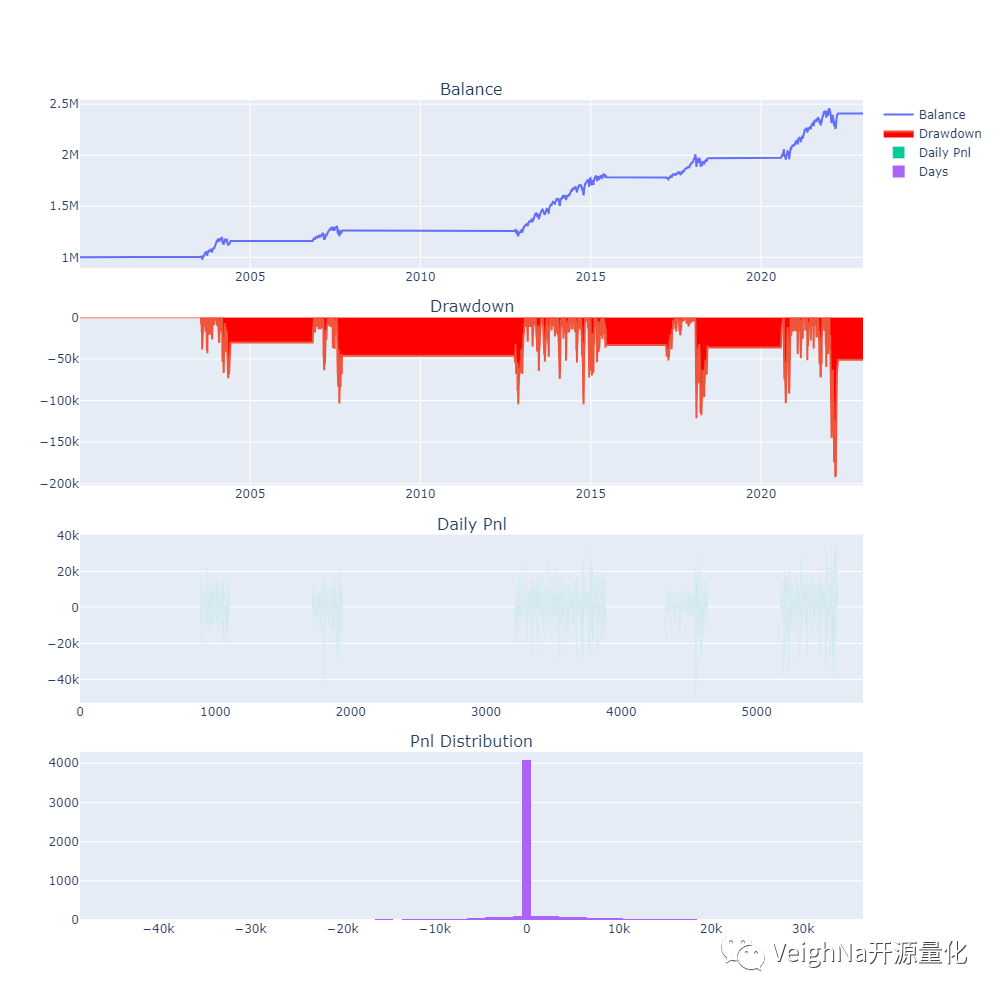
本策略的独特之处在于其较低的回撤率(-7.99%),如此低的回撤率也造就了漂亮的收益回撤比:17.62。
本策略一旦开仓就通常保持在上升轨道上,这意味着它在大部分时间内不会暴露于市场风险之下。这种特性使得这个策略在不稳定市场中具有较强的抗跌能力,有助于保护利润。
由于在大部分时间内没有仓位,该策略可以与其他策略相互配合提供额外收益。低回撤和稳定的增长趋势为其提供了与其他更高风险策略相互协同的机会,以实现更好的综合投资表现。

该策略包括两个指标:
RSI多头范围:RSI过去N天内在40到100之间波动。
RSI多头动量:RSI的极值高点在N天内大于70。
本次回测将使用100天的回望窗口和14天的RSI,这意味着为了触发RSI多头范围的信号,RSI必须在过去的100天内在40到100之间波动。
有了这个理念,交易逻辑非常简单:
当RSI多头范围和多头动量条件都成立时,开仓。
当RSI多头范围和多头动量条件都不再成立时,平仓。
class RsiRangeMomStrategy(CtaTemplate):
"""RSI区域动量策略"""
# 计算RSI指标的窗口
rsi_window: int = 14
# RSI低阈值
rsi_lower: int = 40
# RSI高阈值
rsi_upper: int = 100
# RSI极值阈值
rsi_highest: int = 70
# 风险资金
risk_capital: int = 1_000_000
parameters = [
"rsi_window",
"rsi_lower",
"rsi_upper",
"rsi_highest",
"risk_capital",
]
variables = []
def on_init(self):
"""
Callback when strategy is inited.
"""
self.write_log("策略初始化")
self.bg = BarGenerator(self.on_bar)
self.am = ArrayManager()
# 加载足够的历史数据来计算指标
self.load_bar(150)
def on_bar(self, bar: BarData):
# 撤销所有挂单
self.cancel_all()
am = self.am
am.update_bar(bar)
if not am.inited:
return
# 计算rsi的值,并返回一个【rsi_window】长度的数组
rsi_array: np.ndarray = am.rsi(self.rsi_window, array=True)
# 计算该rsi数组的平均值,使用【np.nanmean】的原因是因为返回的数组中包含NaN值
mean_value: float = np.nanmean(rsi_array)
# 将NaN值使用【mean_value】填充
rsi_array: np.ndarray = np.nan_to_num(rsi_array, nan=mean_value)
# 使用历史rsi值计算趋势是否处于牛市区间
# 判断标准为本段历史中所有rsi的值是否都在【rsi_lower】与【rsi_upper】之间
bull_range_signal: bool = (np.all(rsi_array > self.rsi_lower) and
np.all(rsi_array < self.rsi_upper))
# 判断本段历史中是否存在较强的rsi值,只要有一个超过设定的【rsi_highest】即成立
bull_mom_signal: bool = np.any(rsi_array > self.rsi_highest)
# 计算开仓数量
trading_size: int = (int(self.risk_capital / bar.close_price / 100)
* 100)
# 判断开仓信号
if self.pos == 0:
# 如果牛市区间以及极值信号都出现,满仓入场
if bull_range_signal and bull_mom_signal:
self.buy(bar.close_price*1.05, trading_size)
# 判断平仓信号
if self.pos > 0:
# 如果信号不再成立,清仓
if not (bull_range_signal or bull_mom_signal):
self.sell(bar.close_price*0.95, self.pos)
# 推送UI更新
self.put_event()
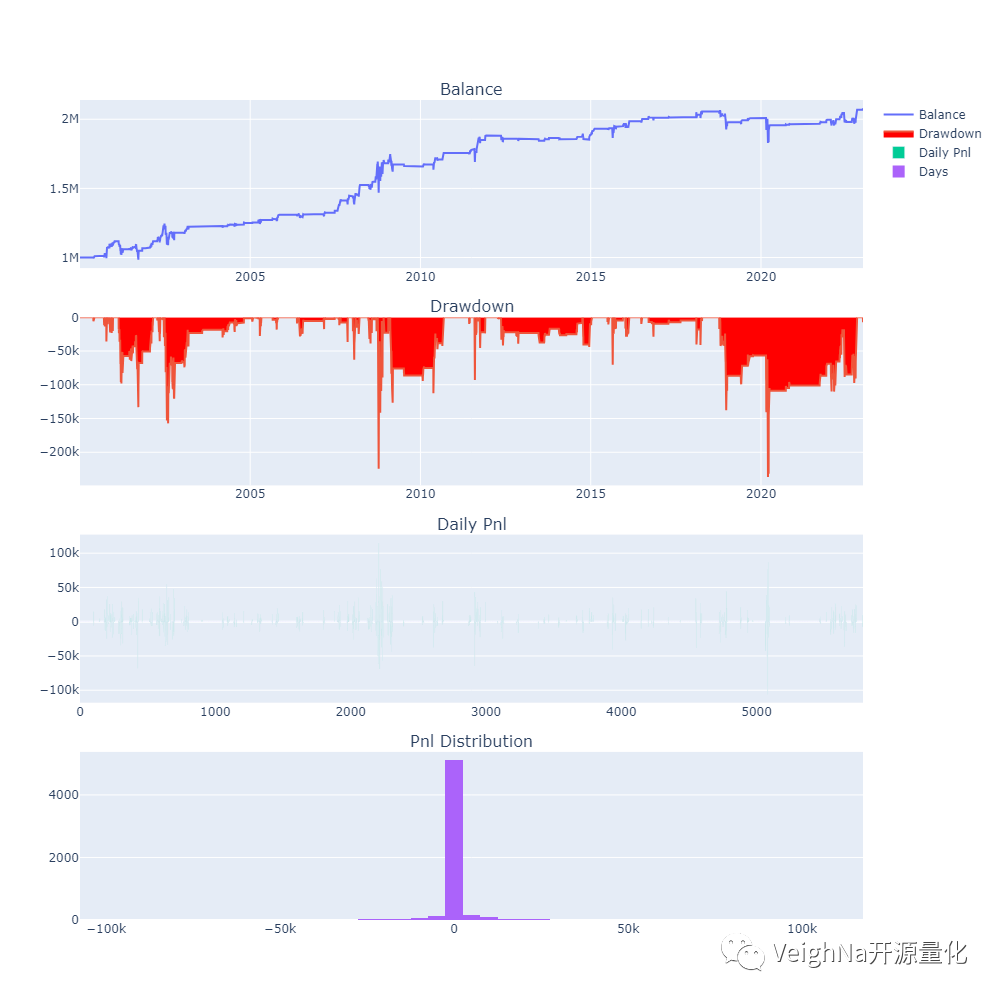

策略中用到的IBS(内部K线强度),指标计算公式如下:
(Close - Low) / (High - Low)
IBS指标的波动范围从0到1,测量收盘价相对于日内高低点的位置,较低的值被认为是看涨的,而较高的值则是短期看跌的,IBS的基本假设是市场具有均值回归的特性。
策略交易逻辑为:
class RsiIbsStrategyOG(CtaTemplate):
"""RSI-IBS策略"""
# rsi指标窗口
rsi_window: int = 21
# 入场rsi指标阈值
rsi_entry: int = 45
# 入场ibs指标阈值
ibs_entry: float = 0.25
# 风险资金
risk_capital: int = 1_000_000
parameters = [
"rsi_window",
"rsi_entry",
"ibs_entry",
]
variables = []
def on_init(self):
"""
Callback when strategy is inited.
"""
self.write_log("策略初始化")
self.bg = BarGenerator(self.on_bar)
self.am = ArrayManager()
self.prev_close = 0
self.load_bar(60)
def on_bar(self, bar: BarData):
"""
Callback of new bar data update.
"""
# 撤销之前发出的委托
self.cancel_all()
# 对am更新bar数据
am = self.am
am.update_bar(bar)
if not am.inited:
return
# 计算开仓手数
trading_size = int(self.risk_capital / bar.close_price / 100) * 100
# 计算rsi指标数值
rsi_value = am.rsi(self.rsi_window)
# 计算ibs指标数值
ibs_value = ((bar.close_price - bar.low_price) /
(bar.high_price - bar.low_price))
# 分别计算开仓信号
cond_1 = rsi_value < self.rsi_entry
cond_2 = ibs_value < self.ibs_entry
# 汇总合成信号
long_signal = cond_1 and cond_2
# 执行开仓操作
if self.pos == 0 and long_signal:
self.buy(bar.close_price * 1.05, trading_size)
# 计算平仓信号,并执行平仓操作
if self.pos > 0:
if bar.close_price > self.prev_close:
self.sell(bar.close_price * 0.95, self.pos)
# 记录当今bar的收盘价
self.prev_close = bar.close_price
# 推送UI更新
self.put_event()
前文中的三套策略虽然都围绕RSI指标开发,但由于核心思路的区别,其回测绩效曲线还是体现出了较低的相关性。那么下一步的研究方向,就是把三套策略中的交易信号提取出来后,集成组合成为一个新的策略,看看能否达到更优秀的整体绩效。
为了实现信号的集成组合,需要对之前的策略代码进行调整,拆分成为策略信号和交易执行两块部分,具体逻辑流程看了下图应该会有一个更加清晰直观的理解:
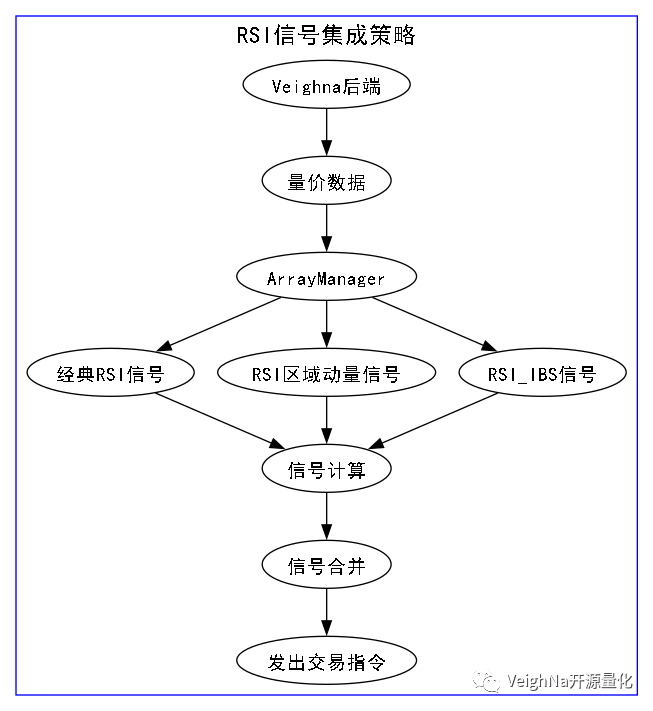
当任一策略信号给出True值即入场做多,当所有策略信号都返回False值或达到止损目标时平仓离场。

信号生成部分被封装在独立的信号类中,分别是:
1. RsiSignal
2. RsiRangeMomSignal
3. RsiIbsSignal
实现这些信号的方式并没有什么特别之处,单单是将前述三个策略的信号生成部分截取出来封装成一个可以返回布尔值(信号)的函数即可。
RsiSignal
class RsiSignal:
def __init__(
self,
rsi_window: int = 2,
rsi_lower: int = 15
):
# 计算RSI指标的窗口
self.rsi_window: int = rsi_window
# RSI低阈值
self.rsi_lower: int = rsi_lower
def calculate_signal(self, am: ArrayManager) -> bool:
# 计算RSI指标
rsi_value = am.rsi(self.rsi_window)
# 判断是否要进行交易
return rsi_value <= self.rsi_lower
RsiRangeMomSignal
class RsiRangeMomSignal:
def __init__(
self,
rsi_window: int = 14,
rsi_lower: int = 40,
rsi_upper: int = 100,
rsi_highest: int = 70
) -> None:
# 计算RSI指标的窗口
self.rsi_window: int = rsi_window
# RSI低阈值
self.rsi_lower: int = rsi_lower
# RSI高阈值
self.rsi_upper: int = rsi_upper
# RSI极值阈值
self.rsi_highest: int = rsi_highest
def calculate_signal(self, am: ArrayManager) -> bool:
# 计算rsi的值,并返回一个【rsi_window】长度的数组
rsi_array: np.ndarray = am.rsi(self.rsi_window, array=True)
# 计算该rsi数组的平均值,使用【np.nanmean】的原因是因为返回的数组中包含NaN值
mean_value: float = np.nanmean(rsi_array)
# 将NaN值使用【mean_value】填充
rsi_array: np.ndarray = np.nan_to_num(rsi_array, nan=mean_value)
# 使用历史rsi值计算趋势是否处于牛市区间
# 判断标准为本段历史中所有rsi的值是否都在【rsi_lower】与【rsi_upper】之间
bull_range_signal: bool = (np.all(rsi_array > self.rsi_lower) and
np.all(rsi_array < self.rsi_upper))
# 判断本段历史中是否存在较强的rsi值,只要有一个超过设定的【rsi_highest】即成立
bull_mom_signal: bool = np.any(rsi_array > self.rsi_highest)
return bull_range_signal and bull_mom_signal
RsiIbsSignal
class RsiIbsSignal:
def __init__(
self,
rsi_window: int = 21,
rsi_entry: int = 45,
ibs_entry: float = 0.25
):
# rsi指标窗口
self.rsi_window: int = rsi_window
# 入场rsi指标阈值
self.rsi_entry: int = rsi_entry
# 入场ibs指标阈值
self.ibs_entry: float = ibs_entry
def calculate_signal(self, am: ArrayManager) -> bool:
# 计算rsi指标数值
rsi_value = am.rsi(self.rsi_window)
# 计算ibs指标数值
ibs_value = ((am.close[-1] - am.low[-1]) /
(am.high[-1] - am.low[-1]))
# 计算开仓信号
cond_1 = rsi_value < self.rsi_entry
cond_2 = ibs_value < self.ibs_entry
return cond_1 and cond_2
前文已经详细讲解过各个信号的生成逻辑,这里便不再赘述。
在主策略的【on_init】函数下,将上述三个信号类实例化为成员对象,并分别传入量价数据缓存容器(通过ArrayManager类的封装):
class RsiEnsembleStrategy(CtaTemplate):
""""""
author = "Tony"
rrms_rsi_window: int = 14
rrms_rsi_lower: int = 40
rrms_rsi_upper: int = 100
rrms_rsi_highest: int = 70
ris_rsi_window: int = 21
ris_rsi_entry: int = 45
ris_ibs_entry: float = 0.25
rs_rsi_window: int = 2
rs_rsi_lower: int = 15
# 风险资金
risk_capital: int = 1_000_000
parameters = [
"rrms_rsi_window",
"rrms_rsi_lower",
"rrms_rsi_upper",
"rrms_rsi_highest",
"ris_rsi_window",
"ris_rsi_entry",
"ris_ibs_entry",
"rs_rsi_window",
"rs_rsi_lower",
]
variables = []
def on_init(self):
"""
Callback when strategy is inited.
"""
self.write_log("策略初始化")
self.bg = BarGenerator(self.on_bar)
self.am = ArrayManager()
# 初始化信号生成器实例
self.rrms = RsiRangeMomSignal(
self.rrms_rsi_window,
self.rrms_rsi_lower,
self.rrms_rsi_upper,
self.rrms_rsi_highest
)
self.ris = RsiIbsSignal(
self.ris_rsi_window,
self.ris_rsi_entry,
self.ris_ibs_entry
)
self.rs = RsiSignal(
self.rs_rsi_window,
self.rs_rsi_lower,
)
self.load_bar(150)
def on_start(self):
"""
Callback when strategy is started.
"""
self.write_log("策略启动")
def on_stop(self):
"""
Callback when strategy is stopped.
"""
self.write_log("策略停止")
def on_bar(self, bar: BarData):
"""
Callback of new bar data update.
"""
# 撤销之前发出的委托
self.cancel_all()
# 对am更新bar数据
am = self.am
am.update_bar(bar)
if not am.inited:
return
# 计算开仓手数
trading_size = int(self.risk_capital / bar.close_price / 100) * 100
# 传入am,计算三个信号的值
rrms_signal = self.rrms.calculate_signal(am)
ris_signal = self.ris.calculate_signal(am)
rs_signal = self.rs.calculate_signal(am)
# 如果任一信号成立则进行开仓
if self.pos == 0:
if rrms_signal or ris_signal or rs_signal:
self.buy(bar.close_price*1.05, trading_size)
# 如果三个信号都不成立则进行平仓
if self.pos != 0:
if not rrms_signal and not ris_signal and not rs_signal:
self.sell(bar.close_price*0.95, abs(self.pos))
# 移动止损逻辑
elif self.pos > 0:
self.sell(bar.close_price*0.95, abs(self.pos), stop=True)
# 推送UI更新
self.put_event()
该策略历史回测需要用到的SPY历史数据,可以下载zip文件后解压,找到其中load_bar_data.py脚本文件,然后用Python运行即可自动导入数据库。
具体的回测参数配置如下:
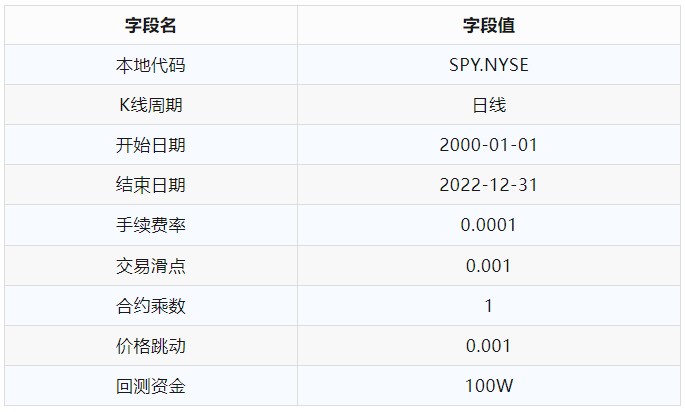
本文选择的回测数据时间段中SPY整体处于长周期大牛市,因此多头逻辑的交易策略可能天然具有明显优势(毕竟简单买入做多就能赚钱),所以这里选择使用IF股指期货来作为策略有效性的交叉验证:
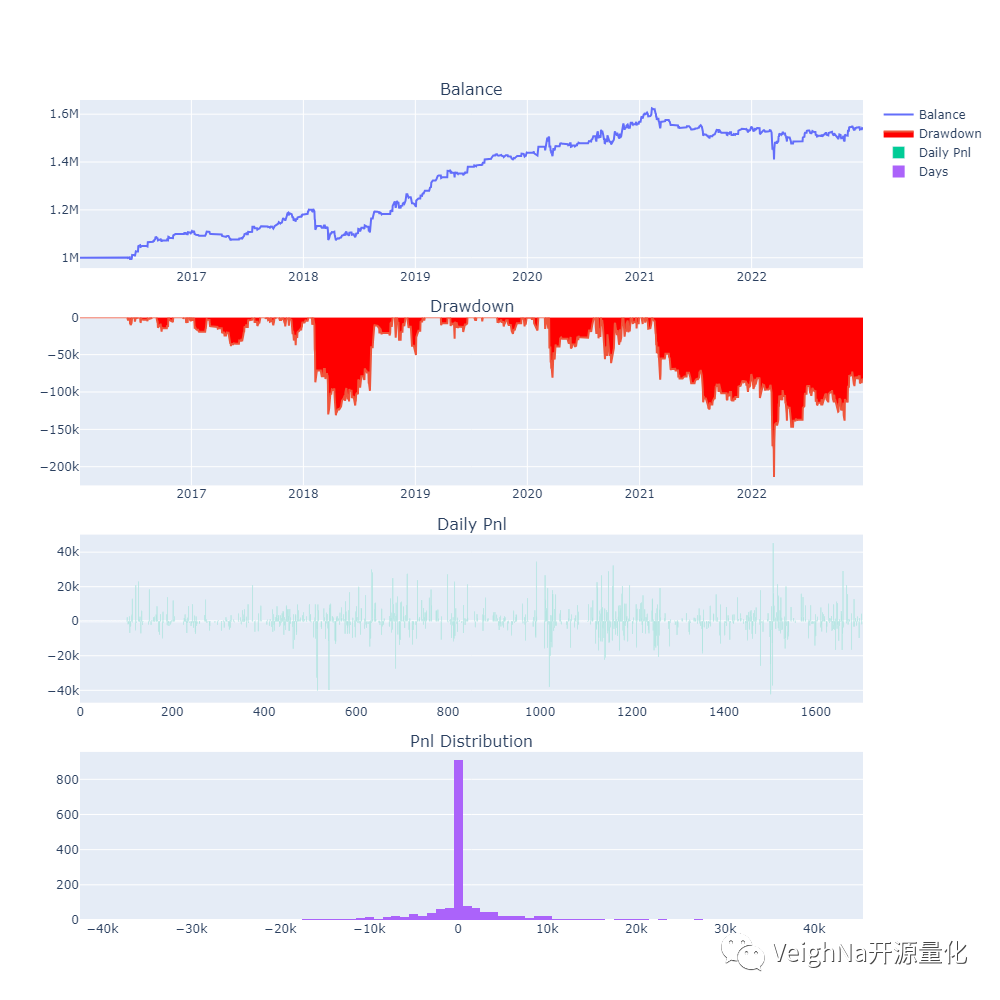
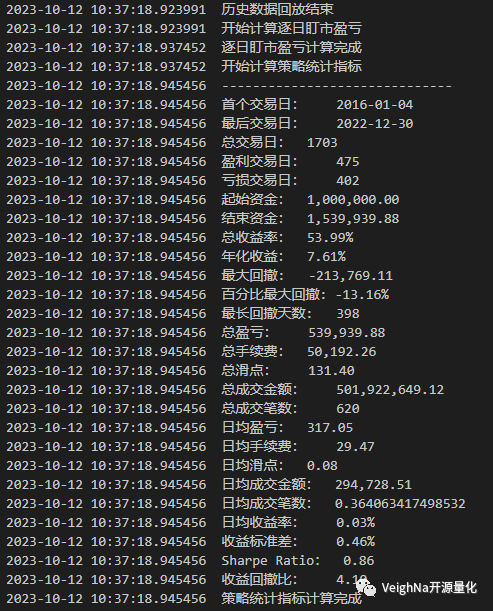
可以看出,RSI多信号集成策略在IF上的绩效也是相当可观的,虽然自2021年起策略的有效性变差了许多,但是仍然将回撤保持在了一个可控的范围,这也体现了CTA策略中多信号组合的优势。
本文代码中多次运用了numpy库中提供的向量化计算函数,例如【np.nan】、【np.mean】、【np.any】、【np.all】等。向量化计算是一种使用数组或矢量操作来处理数据的方法,它具有性能提升、代码简洁、可读性高、跨平台性,适用于大规模数据等优势。
完整策略代码和回测数据文件,可以通过【VeighNa进阶用户交流群】获取:

免责声明
文章中的信息或观点仅供参考,作者不对其准确性或完整性做出任何保证。读者应以其独立判断做出投资决策,作者不对因使用本报告的内容而引致的损失承担任何责任。
发布于veighna社区公众号【vnpy-community】
原文作者:用Python的交易员 | 发布时间:2023-10-11
VeighNa全实战进阶期权系列的第三阶段《精研期权价差策略》正式上线!
这套课程差不多筹划了两年时间,核心原因在于期权策略回测真的很复杂(对比CTA策略来说要复杂得多),列举几个关键点:
为了解决这些问题我们开发了OptionStrategy期权策略模块,但底层需要依赖于【VeighNa 机构版】的服务端架构,对于个人交易员或者小型团队来说运维太过复杂。
截止今年三季度终于基本完成了OptionStrategy在Elite版上的移植工作,所以《精研期权价差策略》课程将会使用【VeighNa Elite版 仿真模拟】来讲解,带着大家由浅入深研究期权价差策略的开发、回测、优化的全流程,同时基于策略历史回测绩效来精研期权价差交易中的各种细节:
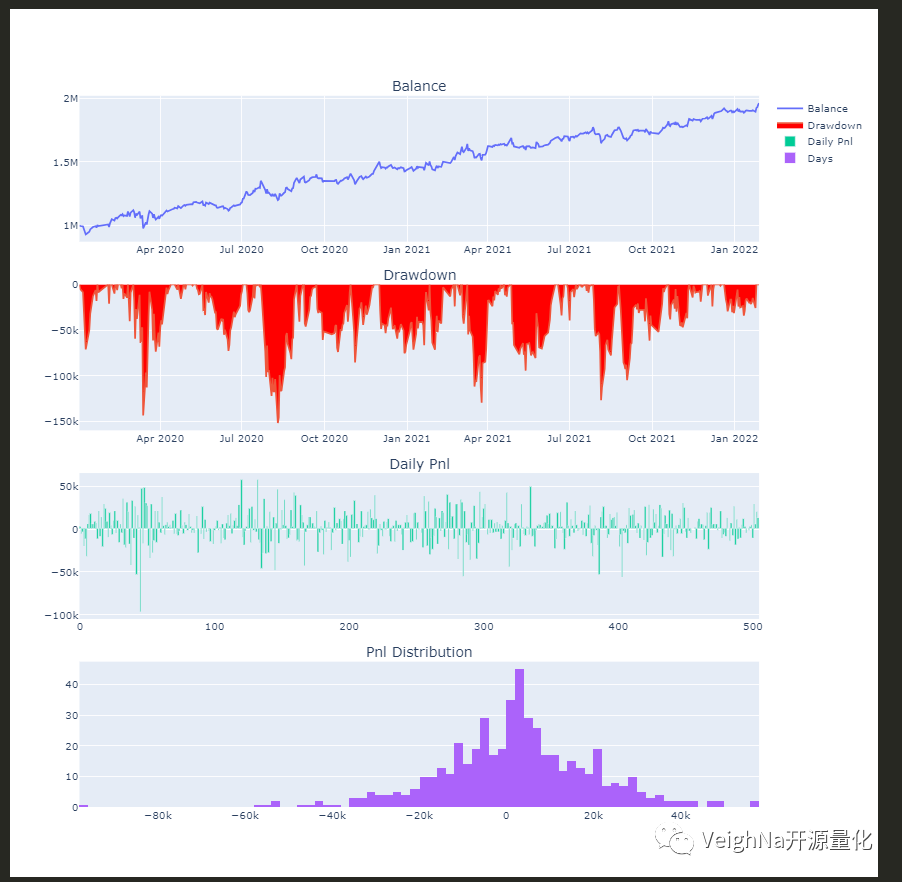
目前【VeighNa Elite版 仿真模拟】已经可以直接在官网下载,安装完成后使用社区论坛的账号密码登录即可(和VeighNa Station一样),仿真交易目前支持上期技术的SimNow环境,后续也计划接入更多其他仿真环境。
课程目前一共计划40节,内容大纲如下(黑体加粗课时为代码实践内容):
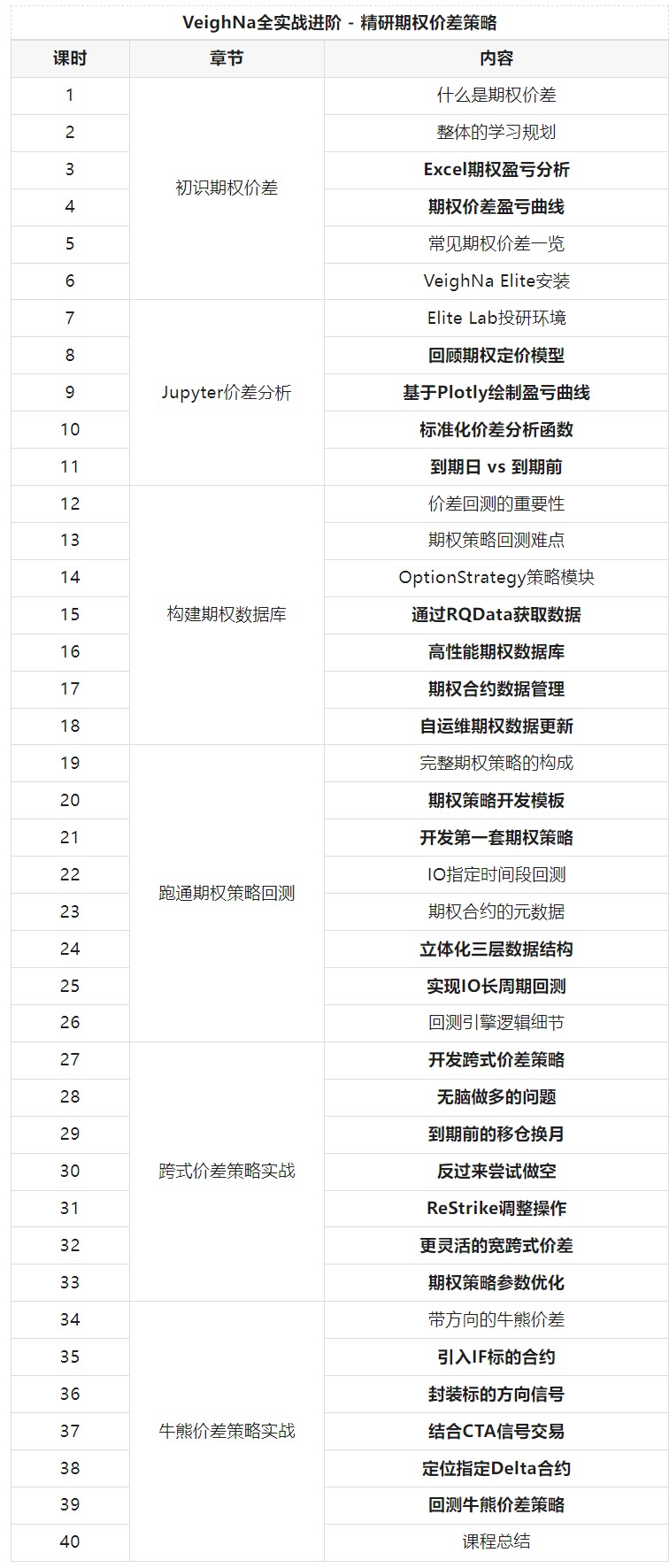
这门课程适合的人群:
课程当前已经上线,价格499元,前100名购买享受9折优惠(449元)。直接在【VeighNa开源量化】公众号(vnpy-community)里就能购买和观看(点击底部菜单栏的【进阶资料】进入)。推荐使用PC微信打开,视频分辨率更加清晰。
本线上课程包含在【Elite会员】免费学习权益内。
发布于vn.py社区公众号【vnpy-community】
原文作者: 丛子龙 | 发布时间:2023-09-19
2023年VeighNa小班特训营【套利价差交易】即将在10月中旬开班!对比趋势跟踪类的CTA策略,均值回归类的价差策略由于其高胜率的特征,能够实现相对更加平稳的盈利绩效,适合用于量化投资组合在市场横盘震荡期的配置优化。目前半数名额已经被报名锁定,感兴趣的同学请抓紧!内容大纲戳这里。
本文将会在上一篇文章中提到的策略基础之上,扩大可投资的标的数量,在更多种类的大类资产中寻找超额收益。
我们从上市时间在2016年以前的ETF中选择了如下标的:
医药50ETF(512120.SSE)
金融ETF(510230.SSE)
TMTETF(512220.SSE)
信息科技ETF(512330.SSE)
证券保险ETF(512070.SSE)
可选消费ETF(159936.SZSE)
必选消费ETF(512600.SSE)
能源ETF(159930.SZSE)
材料ETF(159944.SZSE)
大宗商品ETF(510170.SSE)
黄金ETF(518880.SSE)
相信大家对A股市场中的行业轮动现象都不陌生。行业轮动是利用市场趋势获利的一种主动交易策略,其本质是利用不同投资品种强势时间的错位对行业持仓进行切换,以达到投资收益优化的目的。
通俗点讲,就是根据不同行业的区间表现差异性进行轮动配置,力求能够抓住区间内表现较好的行业、剔除表现不佳的行业,在判断市场不佳的时候,降低权益类仓位,提升另类资产的比例。
在本策略中,专门选择了能代表具体行业的ETF作为资产配置标的,上述列表中除了行业ETF之外还包括了大宗商品和黄金ETF。大宗商品具有较好的抗通胀属性,而黄金则是具有避险资产的属性。同时它们自身也与权益类资产一样,拥有较强的趋势性。
选定了资产池以后,下一步就是将数据加载到回测引擎中进行回测,策略层面将会沿用上篇文章中的EtfRotationStrategy。
这次在回测任务层面会与常用的单次回测稍有不同,原因是我们并不知道怎样配置资产组合才能获得更好的效果,所以在每次回测中需要尝试调整:
为了尽可能寻找到优质的资产组合,本次投研将使用“嵌套循环+批量回测”的方法,具体实现包括以下三步:
第一步:确定组合搜索空间
第二步:遍历组合列表回测
第三步:对回测结果排序分析
首先要计算的是:给定一定数量的合约,一共有多少种组合方法。在这里会用到Python的内置库【itertools】:
# 大类资产ETF范围
etf_list = [
"510170.SSE",
"159944.SZSE",
"512220.SSE",
"512120.SSE",
"159936.SZSE",
"159930.SZSE",
"512330.SSE",
"510230.SSE",
"512600.SSE",
"512070.SSE",
"518880.SSE",
]
# 筛选投资池,下限4只
all_combinations = []
for r in range(4, len(etf_list)):
all_combinations.extend(combinations(etf_list, r))
# 显示总投资池数量
len(all_combinations)
运行上述代码,即可得到一个缓存着所有可能组合的列表。
这么多组合,用手来一个一个敲入系统进行回测肯定是不现实的。随着标的池扩大,组合总数会以指数级增长。此时需要编写一段脚本让程序实现批量回测并缓存目标数据:
def run_backtesting(vt_symbols: list[str], holding_size: int) -> float:
"""运行回测并返回夏普比率"""
engine = BacktestingEngine()
engine.output = lambda a: a
engine.set_parameters(
vt_symbols=vt_symbols,
interval=Interval.DAILY,
start=datetime(2016, 1, 1),
end=datetime.now(),
rates={key: 0.0001 for key in vt_symbols},
slippages={key: 0.001 for key in vt_symbols},
sizes={key: 1 for key in vt_symbols},
priceticks={key: 0.001 for key in vt_symbols},
capital=1_000_000,
)
setting = {"holding_size": holding_size}
engine.add_strategy(EtfRotationStrategy, setting)
engine.load_data()
engine.run_backtesting()
engine.calculate_result()
statistics = engine.calculate_statistics(output=False)
return statistics["sharpe_ratio"]
# 遍历执行回测
results = {}
for combo in all_combinations:
vt_symbols = list(combo)
for i in range(1, math.floor(len(vt_symbols) / 2) + 1):
sharpe_ratio = run_backtesting(vt_symbols, i)
results[combo, i] = sharpe_ratio
运行完成后就会得到一个名为【results】的字典,字典当中包含每一个组合的夏普比率,下一步对results进行排序:
# 基于Sharpe Ratio排序
sorted_results = sorted(results, key=results.get, reverse=True)
# 查看排名前100的组合
print(sorted_results[:100])
首先需要查看在排名靠前的组合中哪些ETF出现的次数较多:
# 计算参数出现频次
etf_counts = defaultdict(int)
size_counts = defaultdict(int)
for tp in sorted_results[:100]:
vt_symbols, holding_size = tp
for vt_symbol in vt_symbols:
etf_counts[vt_symbol] +=1
size_counts[holding_size] += 1
# 绘制ETF代码的出现频率
plt.figure(figsize=(12, 6))
plt.bar(etf_counts.keys(), etf_counts.values()) ))
# 绘制持仓数量出现频率
plt.bar(size_counts.keys(), size_counts.values())
运行过后得到下图(为了阅读清晰,这里将ETF代码转换成了名称):

排名靠前的投资组合中,出现频率较高的有必选消费ETF,信息科技ETF,金融ETF和黄金ETF。这说明在回测时段中,能为策略提供较好收益的资产是它们。
同时不同资产出现频率的差别并没有非常显著,说明每一个资产都可以在不同的时间提供一定的超额收益。
另一方面,排名靠前的ETF持仓数量为2,其次是3和1:
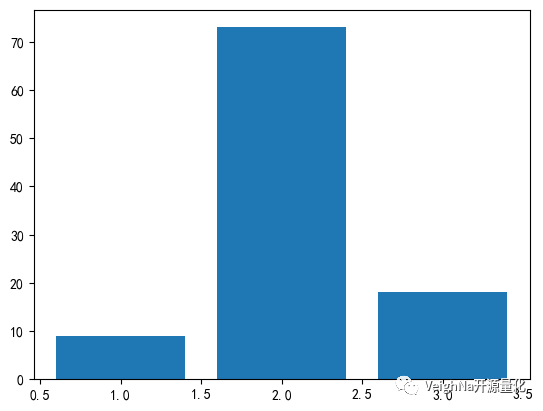
这显示并非同时持仓合约的数量越大效果就越好,反而将合约数量控制在一定水平以内可能获得更好的整体绩效。
接下来使用排名靠前的ETF组合池作为回测合约,并用优化引擎对【regression_window】参数进行穷举优化,得到的结果如下:
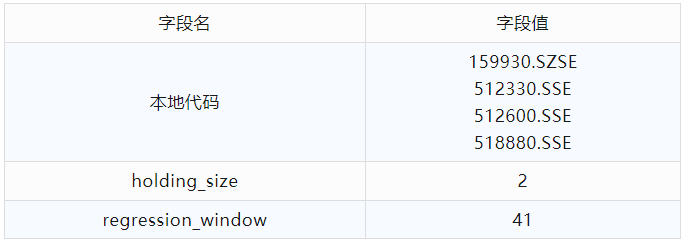

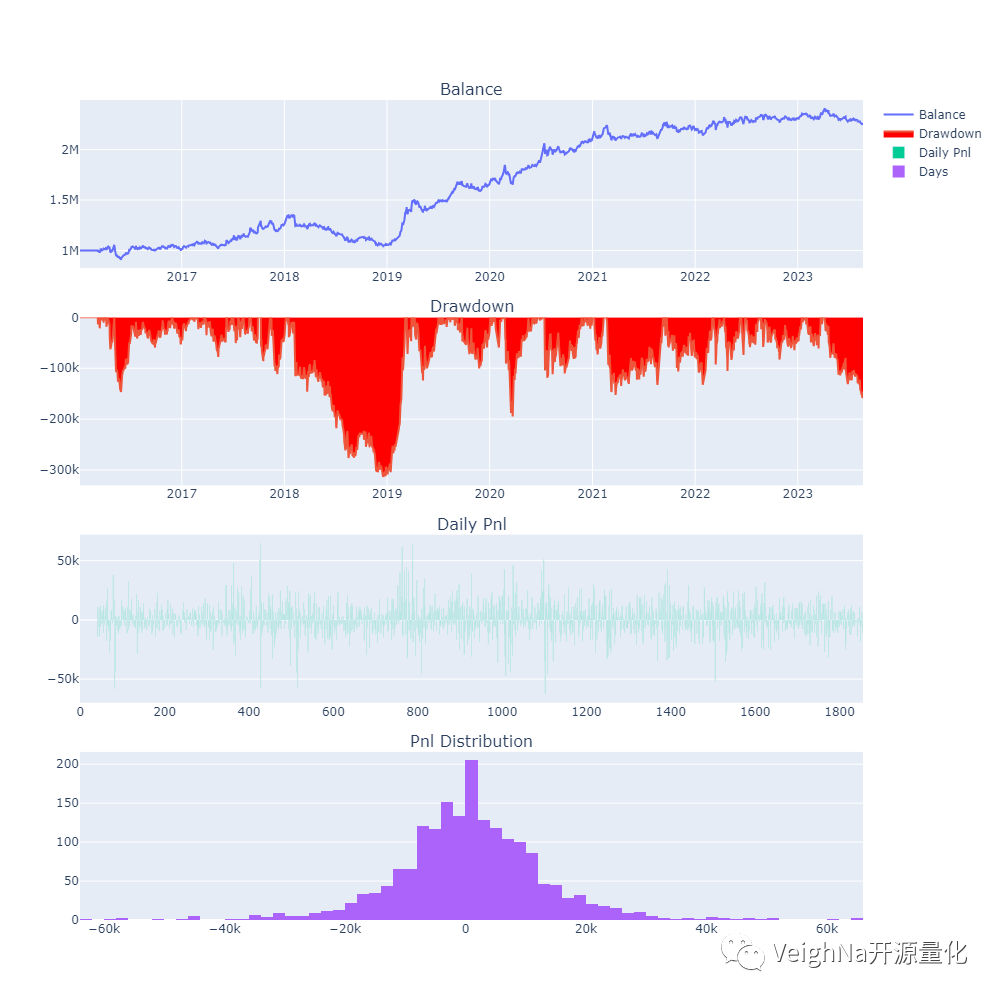
从资金曲线上看,虽然经过了前文的种种优化,但本次选择的ETF组合池整体回测绩效不如之前文章中的结果。
既然是轮动策略,那么理所当然会希望分析在历史回测过程中策略持仓成分的变化。这时可以遍历回测引擎的逐笔成交记录字典(engine.trades)来一笔笔检视每日持仓的变化,但无疑很麻烦,而且不够直观。
更方便的方法,是通过回测引擎提供的【get_all_daily_results】获取策略的逐日盯市统计数据来实现可视化分析:
import pandas as pd
import plotly.graph_objects as go
# 这里的实现需要运行完回测程序,并得到了一个engine对象
# 获取每日持仓数据
results = engine.get_all_daily_results()
# 创建DataFrame
df = pd.DataFrame(
[pos.end_poses for pos in results], index=[pos.date for pos in results]
)
# 这里对数据进行简单处理,我们假设所有持仓都是同等大小
df = df.clip(0, 100)
# 还记得持仓种类数额吗?这里将N设置为策略里的security_size
df[df.T.sum() > 100] *= 1 / 2
# 绘制图表
fig = go.Figure()
for col in df.columns:
fig.add_trace(
go.Scatter(x=df.index, y=df[col], mode="none", fill="tozeroy", name=col)
)
fig.show()
输出的历史持仓分布图表如下:
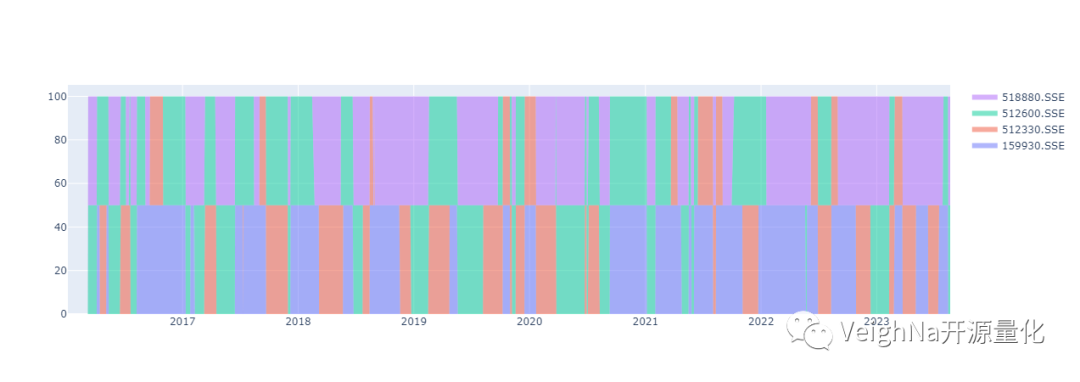
需要注意的是,上述绘图方法只适用于策略在每只ETF上持仓市值相同的情况。有兴趣的同学也可以自行调整大类资产ETF的范围,结合之前两篇文章介绍的优化方法进一步的研究。
完整策略代码和回测数据文件,可以通过【VeighNa进阶用户交流群】获取:

免责声明
文章中的信息或观点仅供参考,作者不对其准确性或完整性做出任何保证。读者应以其独立判断做出投资决策,作者不对因使用本报告的内容而引致的损失承担任何责任。
发布于veighna社区公众号【vnpy-community】
原文作者:用Python的交易员 | 发布时间:2023-09-15
2023年VeighNa小班特训营【套利价差交易】即将在10月中旬开班!对比趋势跟踪类的CTA策略,均值回归类的价差策略由于其高胜率的特征,能够实现相对更加平稳的盈利绩效,适合用于量化投资组合在市场横盘震荡期的配置优化。目前半数名额已经被报名锁定,感兴趣的同学请抓紧!内容大纲戳这里。
上周发布了VeighNa的3.8.0版本,本次更新的主要内容是IB接口的整体功能强化,升级到10.19.1新版本API的同时,也进一步完善了期权相关的交易功能,包括期权链合约数据的查询获取,以及订阅获取IB实时推送的隐含波动率和希腊值风险数据。
对于已经安装了VeighNa Studio的用户,可以使用快速更新功能完成自动升级。对于没有安装的用户,请下载VeighNa Studio-3.8.0,体验一键安装的量化交易Python发行版,下载链接:
https://download.vnpy.com/veighna_studio-3.8.0.exe
使用Ubuntu或者Mac系统的用户,推荐使用VeighNa Docker量化交易容器解决方案:
https://hub.docker.com/repository/docker/veighna/veighna
VeighNa平台的IB接口模块vnpy_ib,底层基于IB官方推出的ibapi接口库开发。目前ibapi的10.19.1新版本已经不再通过PyPI发布,也就是无法直接通过pip install来安装了(会安装到老版本的9.81.1.post1),同样也意味着无法在VeighNa Studio中打包提供。
用户首先需要前往IB官网的API下载页面,下载自己操作系统对应的API安装程序:
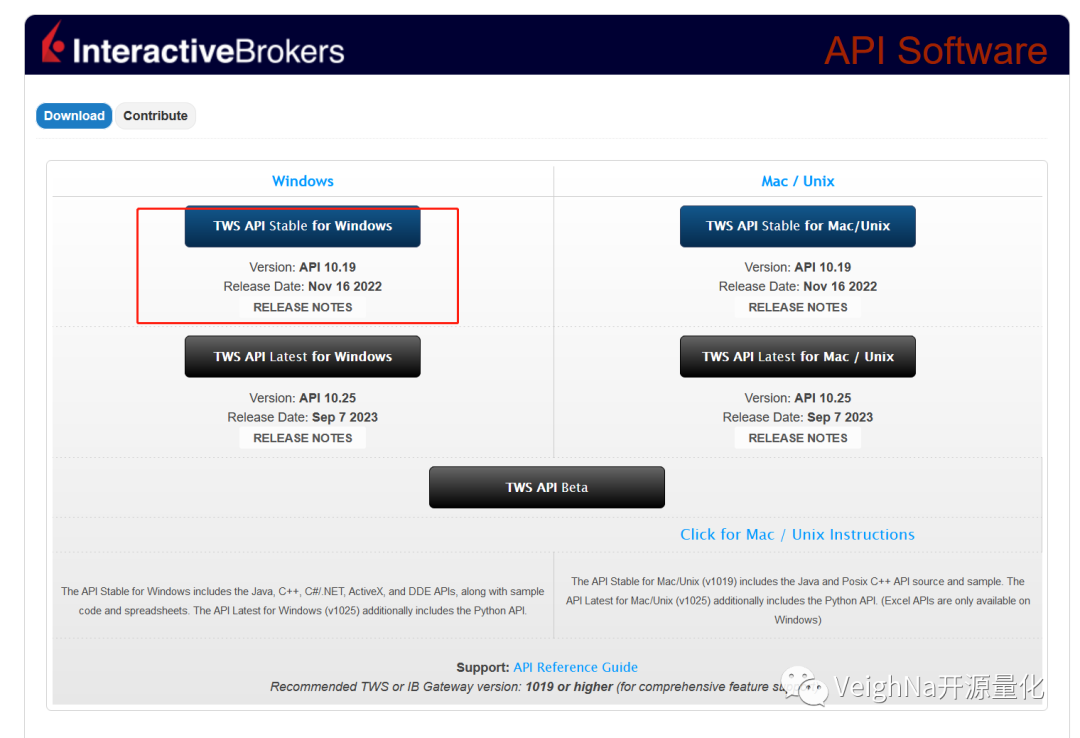
推荐选择Stable版本,图中这里对应的是2022年11月16日发布的10.19版本(左上红色方框),下载完成后运行安装,API开发库会被安装到指定目录(默认为C:\TWS API)。
打开该目录下的source\pythonclient文件夹,看到如下图所示的内容:
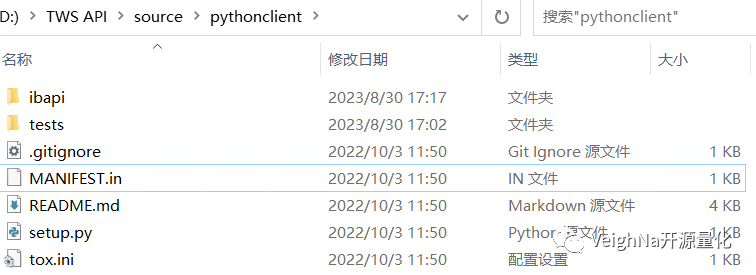
该文件夹中包含的就是ibapi接口库源代码,在空白处按住Shift点击鼠标右键,菜单中选择【在此处打开Powershell窗口】,在弹出的命令行中运行下述命令即可将ibapi安装到Python环境中:
python setup.py install
由于IB接入的金融市场数量众多,导致其上可交易的合约数量非常庞大,不同交易所之间经常会出现合约代码冲突的情况。而国内金融市场大部分情况下都可以通过一个简短的代码来确定具体要交易的合约,比如IF2309.CFFEX、600036.SSE等。
VeighNa核心框架设计上遵循了这一规则,在早期vnpy_ib版本中合约代码(symbol)使用的是由IB(而非交易所)为每个合约分配的ConId,即【数字代码】(如下图中的51529211):
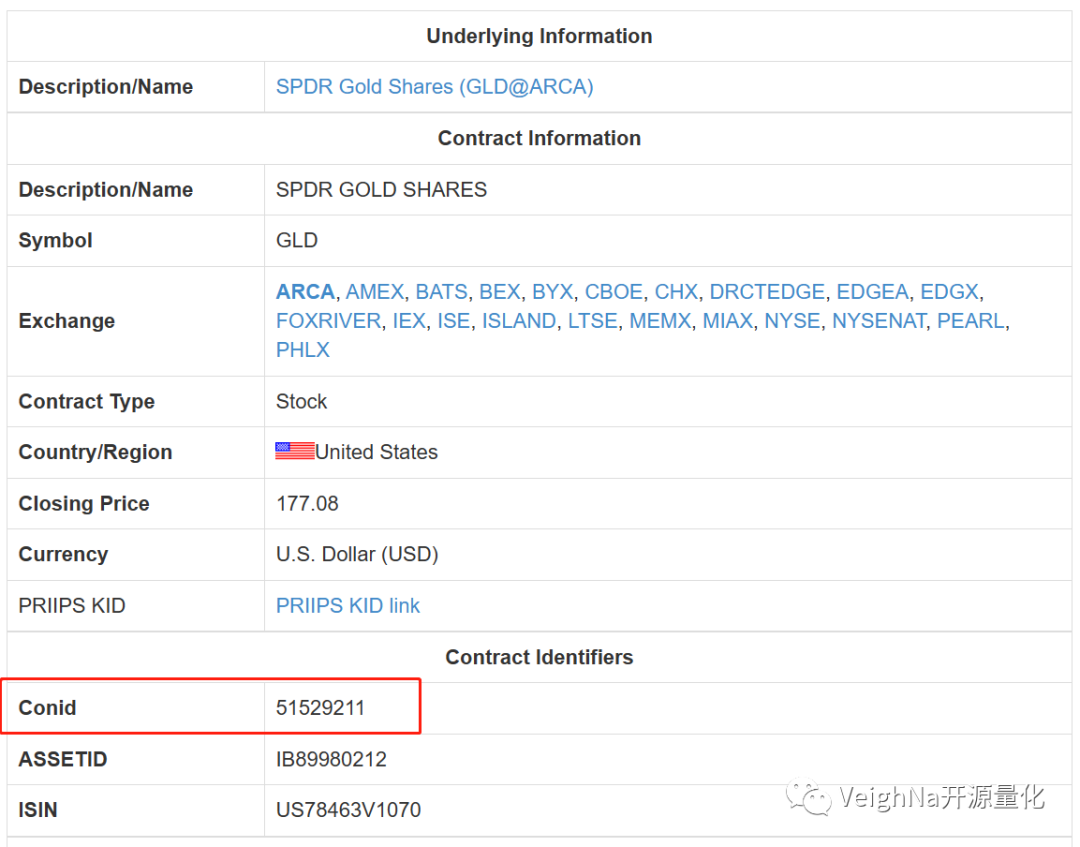
在TWS软件中【右键点击任意合约】->【金融产品信息】->【详情】,即可弹出上图中的页面。
尽管使用ConId在程序内部逻辑上非常方便,但对于交易员来说却不便记忆。基于社区用户的反馈建议,vnpy_ib后续版本中替换为了IB合约描述信息的一个字符串组合,即【描述代码】(如SPY-USD-STK、ES-202002-USD-FUT)。
使用【描述代码】2年多后,陆续收到期权交易相关的问题反馈,核心原因有两点:
综合来看,这两种代码类型都有各自好用的场景和难用的问题,那解决方案自然就是两者一起支持。所以在3.8.0版本中,vnpy_ib接口重新引入了对于【数字代码】的支持,并且两种代码类型可以混合使用,遵循以下规则:
建议之前已经习惯了【描述代码】的用户可以正常继续使用,对于有期权交易需求的用户则更推荐使用【数字代码】。
Interactive Brokers(IB)创始人Thomas Peterffy,早年以期权交易所场内做市交易员身份进入金融行业,后来创建了Timber Hill这家在全球期权市场发展历史上贡献颇多的自营做市商公司,而今的IB只是其当时的副业(用于提供全球交易所的交易链路接入)。
因此IB的TWS平台期权交易方面的功能可谓十分强大,本文封面图片就是TWS平台内置的Volatility Lab(波动率实验室)截图,对内部功能细节感兴趣的话推荐可以看这里的IB官方文档。
3.8.0版本的IB接口,在连接登录时提供了【查询期权】选项:
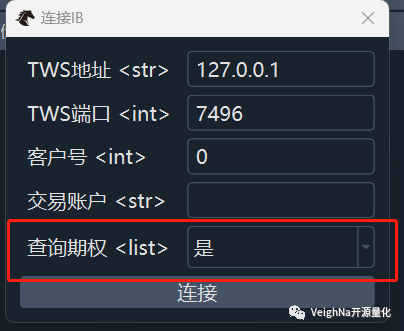
选择为【是】后,每次订阅标的合约行情时,均会自动发起查询其上期权链合约,从而满足期权策略交易中所需的期权产品组合信息。
同时在IB期权Tick行情数据推送中,增加了IB所提供的隐含波动率和希腊值风险数据支持,可以通过TickData.extra字典来访问获取,其中具体包括:
前缀
后缀
前缀和后缀两者组合为具体的数据字段,举例来说:
以上TickData数据对象,可以通过VeighNa平台中策略模块(CtaStrategy、PortfolioStrategy等)下策略模板所提供的on_tick函数来接收获取实时推送。
之前版本中的vnpy_tora基于奇点官方提供的Python 3.7 API开发,只能在Python 3.7环境中使用,VeighNa Station因为内置环境是Python 3.10一直用不了。
本次3.8.0版本更新中使用了奇点的C++ API重构封装,对于API层和Gateway层都做了兼容性调整,目前已经可以在VeighNa Station中直接加载使用。
K线合成器(BarGenerator)增加对日K线的合成支持
基于华鑫奇点柜台的C++ API重构vnpy_tora,实现VeighNa Station加载支持
新增vnpy_ib对于期权合约查询、波动率和希腊值等扩展行情数据的支持
vnpy_rest/vnpy_websocket限制在Windows上改为必须使用Selector事件循环
vnpy_rest/vnpy_websocket客户端关闭时确保所有会话结束,并等待有异步任务完成后安全退出
vnpy_ctp升级6.6.9版本API
vnpy_ctp支持大商所的1毫秒级别行情时间戳
vnpy_tqsdk过滤不支持的K线频率查询并输出日志
vnpy_datamanager增加数据频率下按交易所显示支持,优化数据加载显示速度
vnpy_ctabacktester如果加载的历史数据为空,则不执行后续回测
vnpy_spreadtrading采用轻量级数据结构,优化图形界面更新机制
vnpy_spreadtrading价差子引擎之间的事件推送,不再经过事件引擎,降低延迟水平
vnpy_rpcservice增加对下单返回委托号的gateway_name替换处理
vnpy_portfoliostrategy策略模板增加引擎类型查询函数get_engine_type
vnpy_sec更新行情API至1.6.45.0版本,更新交易API版本至1.6.88.18版本
vnpy_ib更新10.19.1版本的API,恢复对于数字格式代码(ConId)的支持
没有配置数据服务或者加载模块失败的情况下,使用BaseDatafeed作为数据服务
遗传优化算法运行时,子进程指定使用spawn方式启动,避免数据库连接对象异常
合约管理控件,增加对于期权合约的特有数据字段显示
修复vnpy_datarecorder对于新版本vnpy_spreadtrading价差数据的录制支持
修复vnpy_algotrading条件委托算法StopAlgo全部成交后状态更新可能缺失的问题
修复vnpy_ctastrategy策略初始化时,历史数据重复推送调用on_bar的问题
修复vnpy_wind查询日线历史数据时,数值存在NaN的问题
发布于vn.py社区公众号【vnpy-community】
原文作者: 丛子龙 | 发布时间:2023-08-31
2023年VeighNa小班特训营【机器学习CTA】、【套利价差交易】报名进行中,目前半数名额已经被报名锁定,感兴趣的同学请抓紧!内容大纲戳这里。
在探讨多标的资产投资策略的过程中,或许有些同学会产生疑问:为何不同时持有多个合约?这样不仅可以分散风险,还能够捕捉更多有利的行情机会。所以接下来我们就在上篇文章策略的基础上,引入多个投资标的同时持仓的逻辑。
在新的策略中,我们仍然依据R方和斜率的乘积来评估趋势的强弱,得出趋势强弱评分(score)。然而,这次与之前的策略不同,我们决定从中选出两个得分较高的ETF来进行买入持有,而不再仅限于选择一个。每次买入开仓时,将每个选中的ETF买入数量设定为固定资本(fixed_capital)的一半。
来看一下调整后的历史回测绩效表现:
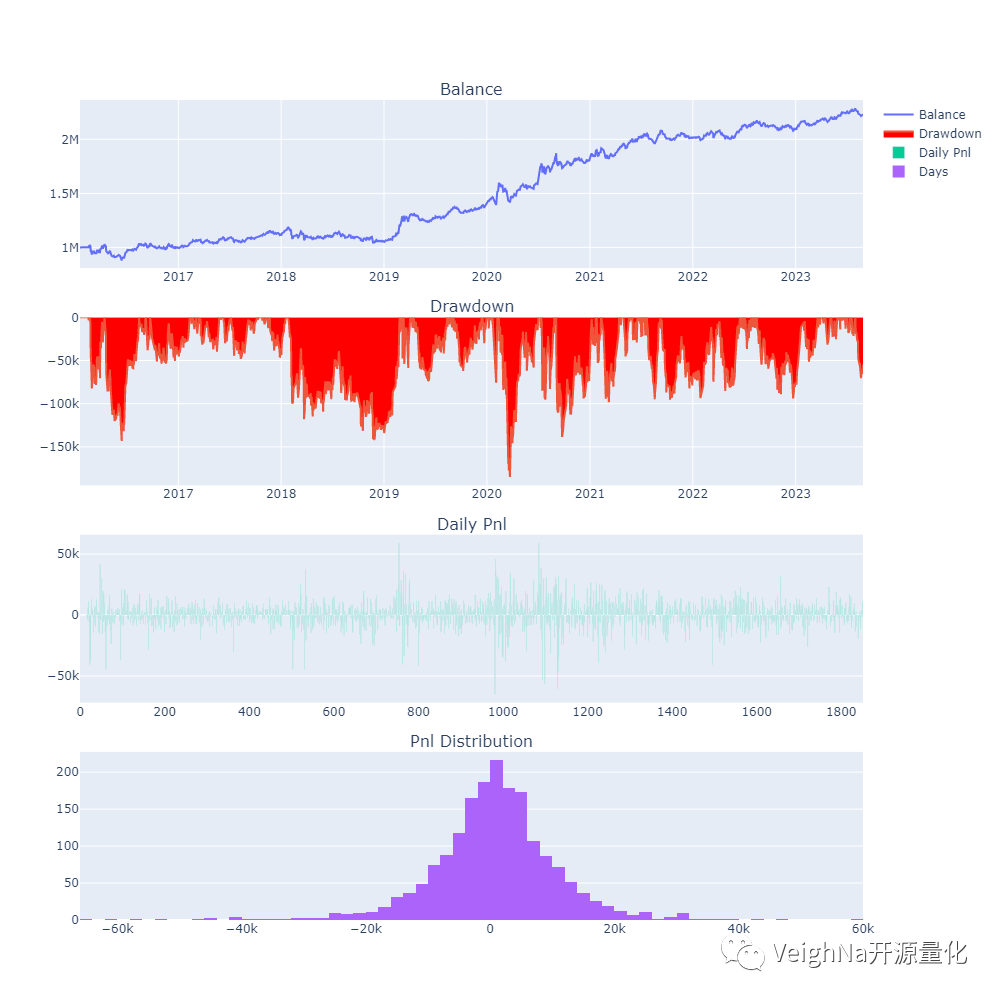
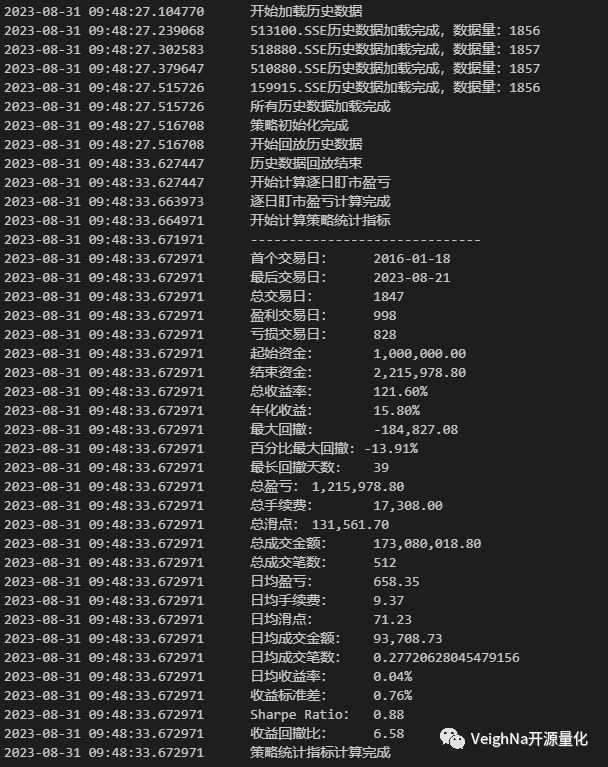
调整的结果展示在历史回测的绩效数据中:尽管年化收益略微下降,但百分比回撤和收益回撤比得到了改善,夏普比率相较于原策略也有所提升。
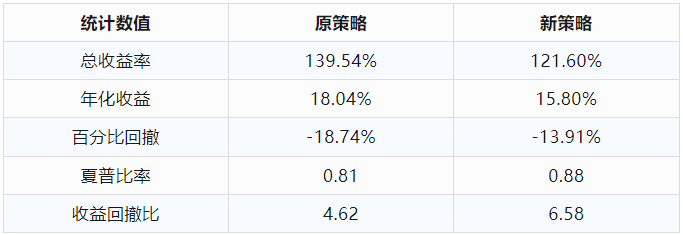
以上改进反映在实际交易中将会转化为更良好的持仓体验,为投资者带来更加稳定和满意的交易结果,具体绩效统计数值对比请看下表:
新的策略代码中引入了名为【holding_size】的变量,用来控制同时持仓的合约数量。
对于记录当前持仓合约的策略成员变量,需要由之前的单一字符串【holding_symbol】,改为字符串列表【holding_symbols】。由于列表属于Python中的可变对象,因此【holding_symbols】的创建需要移动到策略的【on_init】初始化函数之下。
经过调整后的策略模板创建部分的代码如下:
class EtfRotationStrategy(StrategyTemplate):
"""ETF轮动策略"""
author: str = "CZL"
regression_window: int = 25 # 线性回归窗口
holding_size: int = 2 # 同时持仓数量
fixed_capital: int = 1_000_000 # 固定持仓市值
parameters = [
"regression_window",
"holding_size",
]
def on_init(self) -> None:
"""策略初始化"""
# 确保缓存数据足够回归计算
size: int = self.regression_window + 1
# 创建缓存持仓合约的列表
self.holding_symbols: list = []
# 创建每个合约的时序数据容器
self.ams: dict[str, ArrayManager] = {}
for vt_symbol in self.vt_symbols:
self.ams[vt_symbol] = ArrayManager(size)
self.write_log("策略初始化")
在on_bars回调函数下需要做出相应的更改,这里我们也将目标交易执行的逻辑进行了优化,避免在持仓ETF没有发生变化时进行不必要的调仓:
def on_bars(self, bars: dict[str, BarData]) -> None:
"""K线切片推送"""
# 更新K线到时序容器
score_data: Dict[str, float] = {}
for vt_symbol, bar in bars.items():
am: ArrayManager = self.ams[vt_symbol]
am.update_bar(bar)
for vt_symbol, bar in bars.items():
am: ArrayManager = self.ams[vt_symbol]
if not am.inited:
return
# 对ETF进行打分
score_data[vt_symbol] = calculate_score(am.close[-self.regression_window:])
# 重置目标仓位
self.set_target(vt_symbol, 0)
# 对score进行排序,切片选出得分靠前的N个ETF
top_ranked = sorted(score_data, key=score_data.get, reverse=True)[:self.holding_size]
# 如果新一轮入选的ETF与目前持仓不一样,进行调仓
if set(top_ranked) != set(self.holding_symbols):
self.holding_symbols = top_ranked
for security in self.holding_symbols:
price: float = bars[security].close_price
# 每个入选的合约获得同样资金
volume: int = 100 * int((self.fixed_capital / self.holding_size) / (price * 100))
self.set_target(security, volume)
# 根据设置好的目标仓位进行交易
self.rebalance_portfolio(bars)
# 推送UI更新
self.put_event()
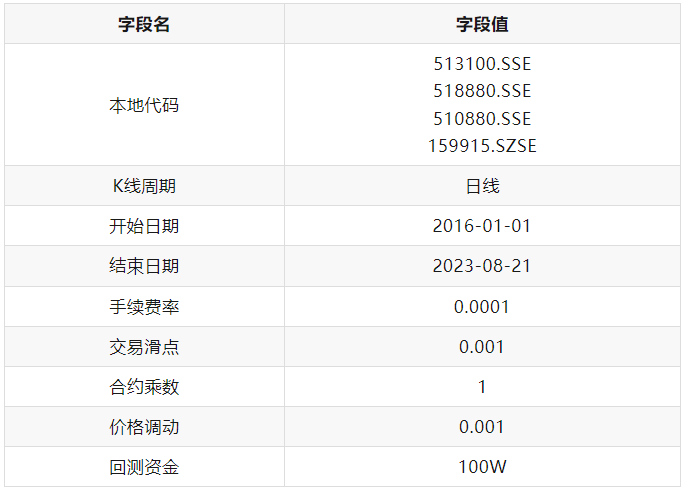
改进后策略的历史回测依旧使用上篇文章中用到的数据,具体的回测参数配置如下:
目前策略已经拥有了两个核心参数【regression_window】和【holding_size】,那么到底这两个参数的数值要怎么设置才能实现更好的策略绩效,接下来的任务自然就是参数优化。
考虑到回测中使用的是日线数据(计算速度较快),所以直接选择暴力穷举优化,下面使用热力图的方式来直观展示参数优化的结果:
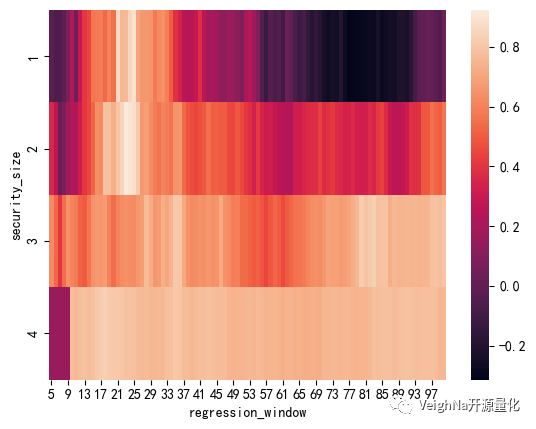
上图中颜色越浅,代表夏普比率(优化的目标函数)越高。可以看出,排名靠前的参数组合聚集在【holding_size】为2,【regression_window】为25~29的区域。
以下是运行参数优化和绘制热力图的代码,可以根据自己的实际需求进行调整:
# 这里需要用到pandas和seaborn两个包
import pandas as pd
import seaborn as sns
# 先运行穷举优化,并将优化结果缓存
setting = OptimizationSetting()
setting.set_target("sharpe_ratio")
setting.add_parameter("holding_size", 1, 4, 1)
setting.add_parameter("regression_window", 5, 100, 1)
result = engine.run_optimization(setting)
# 创造一个空字典用于缓存
data = {}
# 遍历解析result中数据,并缓存进入data
for i in range(len(result)):
d.setdefault('holding_size', []).append(eval(result[i-1][0])['holding_size'])
d.setdefault('regression_window', []).append(eval(result[i-1][0])['regression_window'])
d.setdefault('sharpe_ratio', []).append(result[i-1][1])
# 将数据转化为DataFrame,并按照夏普比率的大小进行排序
sorted_result = (pd.DataFrame(data)
.sort_values('sharpe_ratio', ascending=False)
.reset_index(drop=True))
# 将数据格式转化为pivot table方便绘制热力图
pivoted_table = sorted_result.pivot("holding_size", "regression_window", "sharpe_ratio")
# 绘制热力图
sns.heatmap(pivoted_table)
对于双参数的优化场景,使用热力图可以清晰地观察不同参数组合下策略的绩效表现。这样的分析能够帮助更好地把握参数对策略影响的程度,为进一步的策略改良决策提供有力的依据。
下篇文章中我们准备扩展策略交易的大类资产ETF范围,看看能否获得更加稳健的回测结果。
完整策略代码和回测数据文件,可以通过【VeighNa进阶用户交流群】获取:

免责声明
文章中的信息或观点仅供参考,作者不对其准确性或完整性做出任何保证。读者应以其独立判断做出投资决策,作者不对因使用本报告的内容而引致的损失承担任何责任。
发布于vn.py社区公众号【vnpy-community】
原文作者: 丛子龙 | 发布时间:2023-08-25
2023年VeighNa小班特训营【机器学习CTA】、【套利价差交易】报名进行中,目前半数名额已经被报名锁定,感兴趣的同学请抓紧!内容大纲戳这里。
对于不少VeighNa社区的同学来说,CtaStrategy和PortfolioStrategy这两个策略模块到底有什么区别,可能一直傻傻分不清楚。这里做了个对比表格,希望能够给大家一个比较清晰的认识:
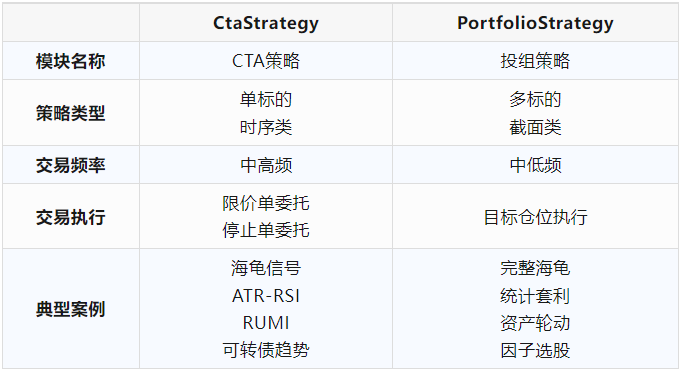
过去几篇的【Elite量化策略实验室】系列文章围绕CTA策略模块(CtaStrategy)相关的内容展开,主要是针对期货市场的中高频策略,实盘中需要程序化自动交易执行。
本篇文章中将要分享的则是一套基于投组策略模块(PortfolioStrategy)的大类资产ETF轮动策略,该策略采用中低频日线级别数据生成交易信号,实盘中即使手动交易执行基本也能满足需求。
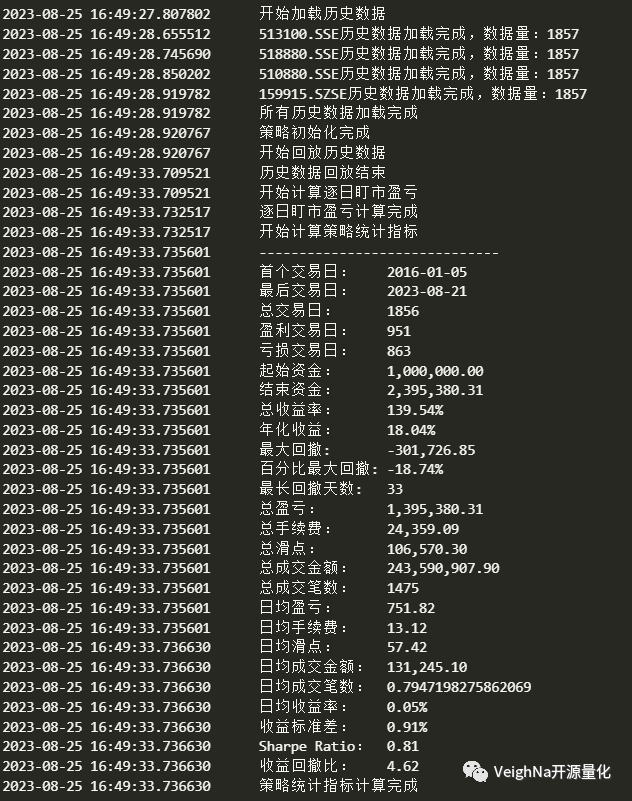
同样先来看一下策略的历史回测绩效:


本文中策略的思路来源于微信公众号【量化君也】的文章:
对于该策略的一些背景情况和详细原理,推荐直接看这篇文章(同时也强烈推荐【量化君也】公众号,其中有不少精彩的量化策略分享),所以这里只梳理下策略的核心逻辑。
对众多普通投资者来说,ETF基金是一种非常适合用来追踪大类资产价格波动,并且拥有较好流动性的交易品种,这里选择了四只比较典型的ETF来构建轮动组合:
在具体决定每日要持仓的ETF时,使用的则是在金融领域中已经被广泛应用的时序动量(Time-Series Momentum)作为策略信号。
对每只ETF的收盘价时间序列,计算其线性回归后的的斜率,斜率越大代表走势越强。同时计算线性回归结果中的决定系数R平方(又名R方),其数值越大(越接近1)则说明拟合效果越好,反之(越接近0)则说明效果越差。
利用斜率和R平方的乘积得出一个趋势强弱评分score,score越高就表示动量越强,每日都选择持有当前score排名靠前的ETF进行轮动。
EtfRotationStrategy基于PortfolioStrategy模块下的策略模板类StrategyTemplate开发,可以直接在VeighNa开源版中使用(不依赖Elite版)。
class EtfRotationStrategy(StrategyTemplate):
"""ETF轮动策略"""
author: str = "CZL"
regression_window: int = 25 # 线性回归窗口
fixed_capital: int = 1_000_000 # 固定持仓市值
holding_symbol: str = "" # 持仓合约代码
parameters = [
"regression_window",
"fixed_capital"
]
variables = [
"holding_symbol"
]
def on_init(self) -> None:
"""策略初始化"""
# 确保缓存数据足够回归计算
size: int = self.regression_window + 1
# 创建每个合约的时序数据容器
self.ams: dict[str, ArrayManager] = {}
for vt_symbol in self.vt_symbols:
self.ams[vt_symbol] = ArrayManager(size)
self.write_log("策略初始化")
因为要使用前N天的收盘价历史来计算score,所以这里在创建ArrayManager实例时传入了size参数(self.regression_window + 1),在保证有足够缓存数据满足计算需求的同时,减少花费在回测初始化上的数据长度(日线的总数据长度相对分钟线要少几个数量级)。
首先需要使用sklearn库中的线性回归功能,来实现对ETF当前趋势强弱得分score的计算函数:
from sklearn.linear_model import LinearRegression
def calculate_score(data: np.ndarray) -> float:
"""计算强弱得分"""
# 执行回归
x: np.ndarray = np.arange(1, len(data) + 1).reshape(-1, 1)
y: np.ndarray = data / data[0]
reg: LinearRegression = LinearRegression().fit(x, y)
# 返回得分
slope: float = reg.coef_[0]
r2: float = reg.score(x, y)
return slope * r2
然后在on_bars回调函数中即可计算各只ETF的得分score,并统一缓存到数据字典score_data中:
def on_bars(self, bars: dict[str, BarData]) -> None:
"""K线切片推送"""
# 更新K线到时序容器
for vt_symbol, bar in bars.items():
am: ArrayManager = self.ams[vt_symbol]
am.update_bar(bar)
# 计算每只ETF的分数
score_data: dict[str, float] = {}
for vt_symbol, bar in bars.items():
am: ArrayManager = self.ams[vt_symbol]
if not am.inited:
return
data: np.array = am.close[-self.regression_window:]
score_data[vt_symbol] = calculate_score(data)
多标的截面类的PortfolioStrategy经常需要对多个合约同时交易,由用户在策略中直接实现具体的买卖委托操作可能较为麻烦,因此这里使用StrategyTemplate提供的目标仓位交易执行功能:
# 重置所有合约目标
for vt_symbol in self.vt_symbols:
self.set_target(vt_symbol, 0)
# 选出得分领先的ETF
self.holding_symbol: str = max(score_data, key=score_data.get)
price: float = bars[self.holding_symbol].close_price
# 交易数量必须是100整数倍
volume: int = 100 * int((self.fixed_capital / (price * 100)))
self.set_target(self.holding_symbol, volume)
# 根据设置好的目标仓位进行交易
self.rebalance_portfolio(bars)
# 推送UI更新
self.put_event()
在上文代码中,每日的交易执行步骤可以分解为:
该策略的历史回测需要用到前文提及的四只ETF日线数据,可以下载zip数据文件后解压,找到其中csv格式的数据文件,然后使用DataManager模块导入数据库即可。
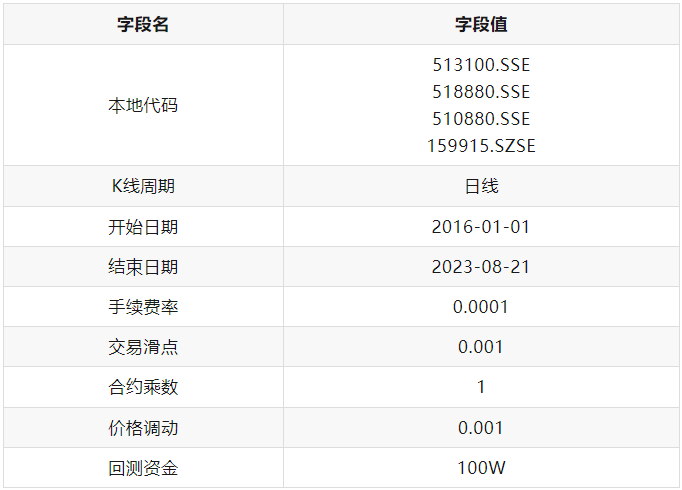
具体的回测参数配置如下:
回测结果的资金曲线和绩效统计可以参考前文中的内容。
需要注意的是,本文中EtfRotationStrategy的策略代码采用了固定市值持仓进行交易,在回测机制上属于单利模式(忽略了由于盈利带来的复利增长),更多为了体现策略本身逻辑的稳健性,而在实际交易中仍然应该根据账户的盈亏变化进行动态市值的持仓轮动。
完整策略代码和回测数据文件,可以通过【VeighNa进阶用户交流群】获取:

免责声明
文章中的信息或观点仅供参考,作者不对其准确性或完整性做出任何保证。读者应以其独立判断做出投资决策,作者不对因使用本报告的内容而引致的损失承担任何责任。
职位名称
上海某券商资管量化研究岗
职位职责
深入海量金融数据进行研究分析、挖掘有效信号,开发和优化量化模型策略,包括但不限于股票、期货、期权等市场,包括但不限于:
职位要求
1、国内外名校金融工程、数学、计算机、统计、物理或其他理工科相关专业研究生及以上学历(国内学校排名前15,国外学校QS前100);
2、熟练使用Python/ C++/C#编程语言;
3、具备扎实的数理基础,一流的概率统计能力,和严谨的研究习惯;
4、对大数据挖掘、概率统计、机器学习、深度学习、时间序列分析、模式识别、自然语言处理与提取有深入的理解和实践经验;
5、积极思考并积极求证,对解决复杂问题有强烈兴趣,能够自我驱动;
6、2024届及以后毕业应届生,实习期至少保证3个月以上,有留用机会。
其他信息
加分项:
1、国内外各种竞赛经历并取得优异成绩;
2、有计算机领域顶会或顶刊paper发表;
3、有券商金工、私募等中高频量化研究实习经历并取得一定的研究成果,包括但不限于股票/期货/期权等各类二级市场品种;
4、对机器学习有过实际项目经验。
联系方式
简历发送邮箱:hr@mail.vnpy.com,简历请以姓名+学校+专业命名
工作地点
上海
发布于vn.py社区公众号【vnpy-community】
原文作者:用Python的交易员 | 发布时间:2023-08-08
由于上期小班特训营【机器学习CTA】的报名人数超出我们的预期,结束后也已经有不少同学报名了下期开班,看来大家对于如何将机器学习技术应用在量化交易领域还是非常的感兴趣,所以这次在2023年原定计划的第二场【套利价差交易】之外,特别再增开一场【机器学习CTA】,结合均值回归类的价差策略和趋势跟踪类的CTA策略可以构建Sharpe Ratio更加优秀的量化投资组合。
目前已经有部分名额被提前报名锁定,感兴趣的同学请抓紧。老规矩还是放几张之前特训营的照片:

准备完毕,静候同学们到达

学习量化,先从掌握核心框架

深入代码,分析策略逻辑细节
所有小班特训营时间定在周末两天,一共包含周六周日两个下午共计10+小时的课程,设立特训营专属答疑群,包括后续三个月的助教跟踪辅导,提供VeighNa小班特训营专属内部核心资料。
线下课程的地点在上海浦东,不方便来上海的同学我们也提供远程线上听课(直播+录播)。对于所有参加小班特训营的学员,在课程结束后都会拿到课程的完整录播视频,可永久回看。
VeighNa套利价差交易
日期:2023年10月14日(周六)和10月15日(周日)
时间:两天下午1点-6点,共计10小时
大纲:
初识套利价差交易
a. 套利类策略的特点:靠高胜率获得核心优势
b. 如何寻找好的套利价差,从数据面和基本面着手
c. 价差组合时间序列建模:相关性分析、协整算法
价差数据结构设计
a. 价差腿LegData和价差组合SpreadData
b. 价差盘口计算原理:价格、数量、统计算法
c. 基于动态解析的灵活价差数据计算
d. 实盘数据流驱动,底层接口到上层算法
价差交易算法实现
a. 价差执行算法和价差量化策略的异同
b. 基于SpreadAlgoTemplate实现狙击算法
c. 价差做市算法实现,盘口细粒度委托控制
价差量化策略开发
a. 半自动固定范围买卖策略
b. 全自动统计套利模型策略
c. 网格区间价差交易策略
价差交易实战进阶:
a. 价差策略回测:TICK模式和K线模式
b. 实盘策略运维原则,安全、稳定
c. 主动腿挂单做市算法的实现
价格:11999元
VeighNa机器学习CTA
日期:2023年11月4日(周六)和11月5日(周日)
时间:两天下午1点-6点,共计10小时
大纲:
搭建机器学习环境
a. 选择合适的硬件机器和操作系统
b. VeighNa和GPLearn开发环境准备
c. 针对机器学习的高性能数据存储
认识遗传规划学习
a. 从【先有逻辑、后有公式】到【先有公式、后有逻辑】
b. 算法基础:种群生成、适应度评价、自然选择、组合变异
c. 数据集的拆分处理:训练集、验证集、测试集
上手CTA特征工程
a. 基础特征数据的清洗准备:加载、预处理、缓存
b. 梳理GPLearn内置特征函数:参数分类、边界情况处理
c. 时序类特征函数的扩展开发:技术指标类、统计模型类
适应度评价的选择
a. 适合量化交易的Fitness适应度评价体系
b. 简单的收益率相关性:不依赖历史回测
c. 全面的回测统计值:向量化策略回测框架
策略开发实战应用
a. 机器学习CTA的三部曲:特征、信号、策略
b. 趋势跟踪和震荡反转两种信号的实现
c. CTA策略中的细节:资金管理、止损风控、平仓出场
价格:11999元
报名方式和之前一样,请发送邮件到vn.py@foxmail.com,注明想参加的课程、姓名、手机、公司、职位即可。或者也可以扫描下方二维码添加小助手咨询报名:

课程对于之前参加过小班特训营的学员优先开放。
发布于vn.py社区公众号【vnpy-community】
原文作者:何若楠 | 发布时间:2023-08-02
社区有不少新接触VeighNa的同学咨询如何上手学习,这里推荐下官方团队推出的小鹅通线上课程:《零基础入门系列》覆盖【Python基础】、【数据分析】、【GUI开发】三阶段,适合有金融背景的编程小白快速建立自己的Python开发知识体系;《全实战进阶系列》则针对具体的量化策略应用,适合有开发背景的金融小白通过实践来迅速掌握量化投研能力,包括【CTA实战】、【超越海龟】、【期权入门】和【投组策略】。
PyCharm是由JetBrains公司推出针对Python语言的IDE,其内置一整套可以帮助用户在使用Python语言开发时提高其效率的工具。本文意在为用户提供通过PyCharm开发使用VeighNa的方案以供参考。
本中的内容基于Windows系统编写,但对于Linux和Mac系统大部分也都适用。
当前时点,VeighNa适用的Windows系统包括:
Windows Server 2019/2022
其他版本的Windows系统安装时可能遇到各种依赖库问题,不推荐使用。
在Windows系统上使用VeighNa,推荐安装官方推出的【VeighNa Studio】Python发行版,尤其是初次接触Python开发的新手用户。
首先从PyCharm官网下载PyCharm Community安装包:
下载完成后,双击安装包则可进入PyCharm安装向导:
如果想对安装选项进行设置,可以在PyCharm Community Edition Setup页面对相关选项进行勾选:
安装完成后,会跳转到安装成功页面:

如果前面勾选了Create Desktop Shortcut选项来创建桌面快捷方式的话,此时桌面上会出现PyCharm的图标,双击图标即可运行PyCharm。
启动PyCharm之后,在弹出的欢迎界面中点击【New Project】创建新项目,如下图所示:
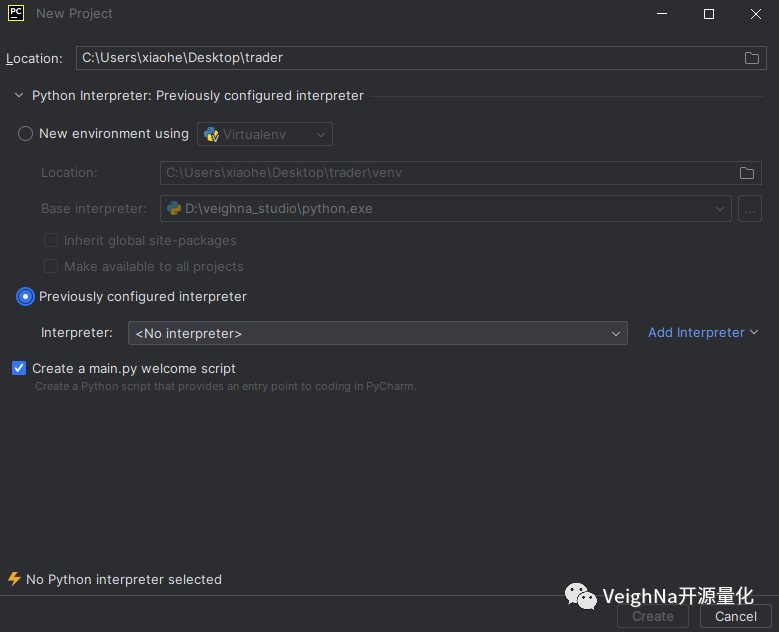
在弹出的新项目窗口中,首先需要选择存放项目的文件夹路径【Location】,然后勾选Python解释器选项中的【Previously configured interpreter】选项(即当前系统中已经安装的Python环境):
点击右侧Add Interpreter下拉框中的【Add Local Interpreter】,在弹出的对话框中点击左侧的【System Interpreter】标签,并在右侧出现的下拉框中选择VeighNa Studio自带Python解释器所在的路径:
点击底部的【OK】按钮保存解释器配置,回到新项目窗口中,点击右下方的【Create】按钮来完成新项目的创建:

创建成功的项目窗口如下图所示:
此时点击左上方的【External Libraries】,即可看到项目中可以调用的外部库:
点击site_packages文件夹,往下滚动就能找到VeighNa Studio中的vnpy核心框架包以及vnpy_前缀的插件模块包。此时可以通过点击对应图标来查看每个包中的文件源码,如下图所示:

把鼠标光标移到代码上方,会自动弹出对应代码的文档信息:
若按住Ctrl键的同时用鼠标左键点击代码,则会跳转到代码的声明部分:

点击窗口右下角的【Python 3.10】按钮,会弹出【Settings】项目配置窗口,可以看到当前解释器环境下安装的包名称和版本号信息。带有升级符号(向上箭头)的包,说明当前版本有更新版本,点击升级符号即可自动升级。
请注意:由于VeighNa对于部分依赖库有严格的版本要求,不建议用户手动升级安装的包,可能会出现版本冲突。
从Github代码仓库下载VeighNa Trader启动脚本文件run.py,并将其放置于trader文件夹下,即可在窗口左侧的项目导航栏中看见run.py文件:
若部分代码下方可以看见绿色波浪线显示(变量名称英文词语检查),可以点击项目名称左方的主菜单按钮 -【File】-【Settings】-【Editor】-【Inspections】-【Proofreading】,取消【Typo】的勾选后点击【OK】确认。再回到主窗口,可以发现绿色波浪线已经消失:
点击鼠标右键,选择【Run 'run'】,即可开始运行run.py脚本:
此时在界面底部的终端内容输出区域中,可以看到程序运行时的打印信息:
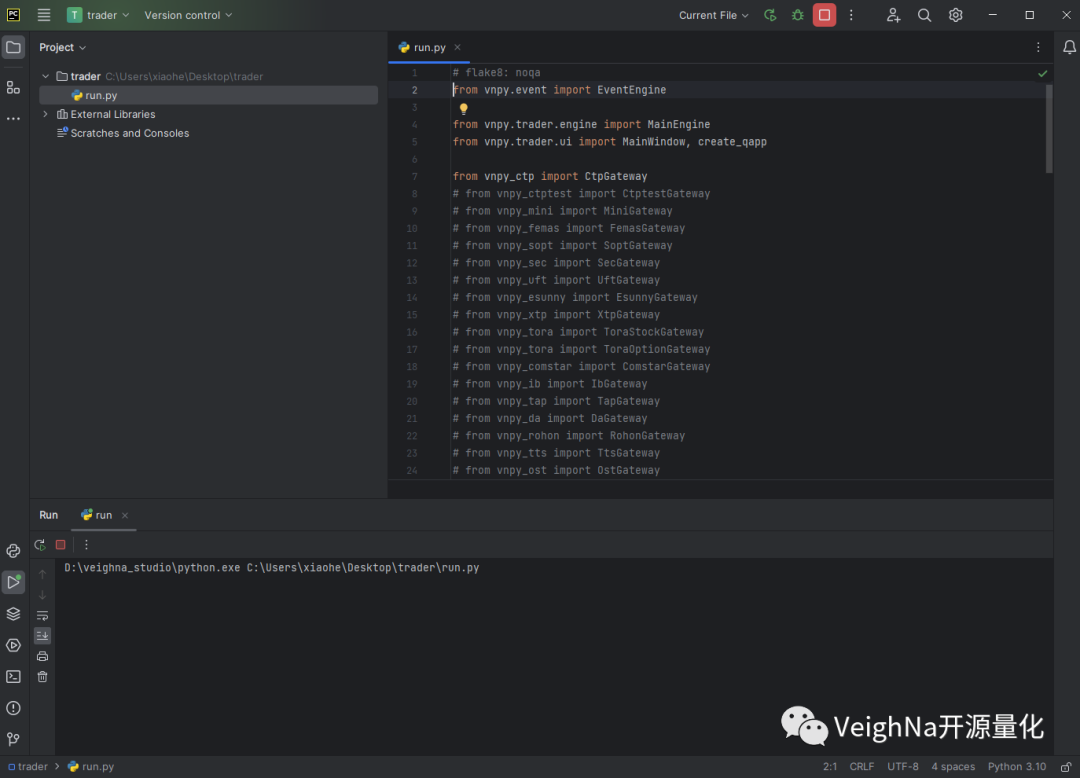
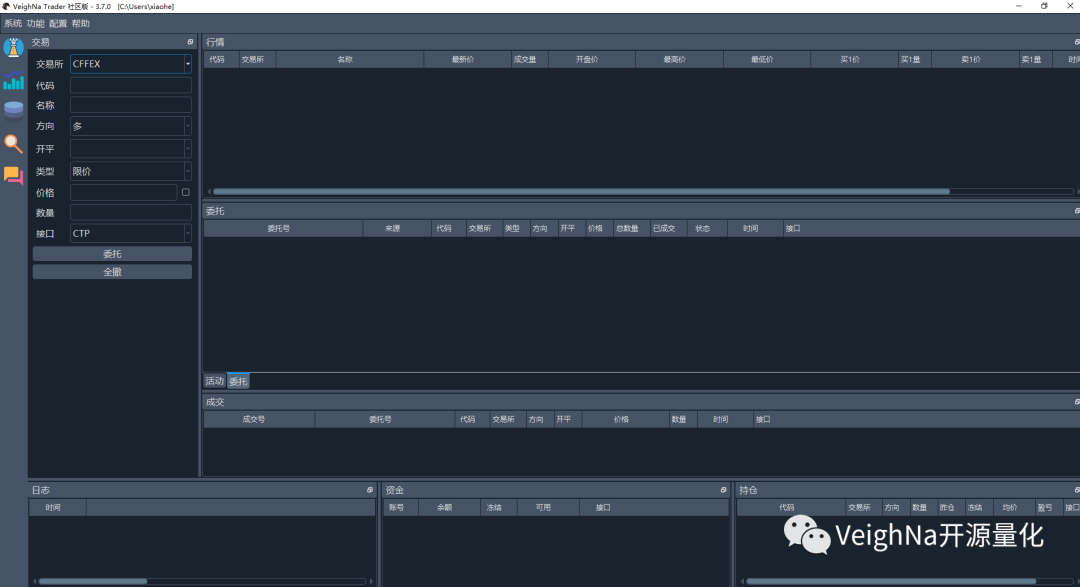
与此同时,VeighNa Trader的主窗口也会自动弹出显示:
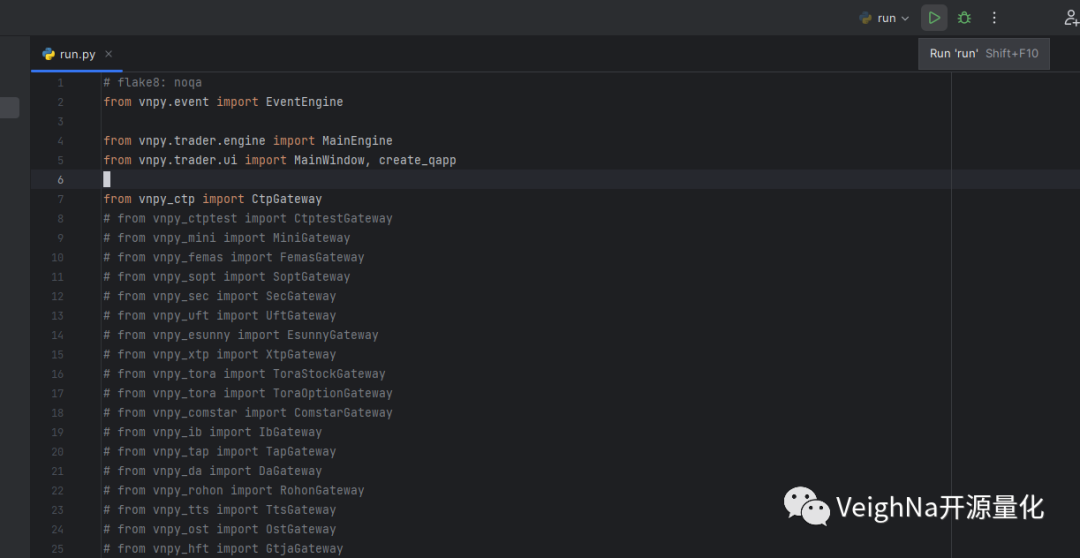
回到PyCharm,可以看到项目界面右上角已经有run脚本的运行记录了,后续直接点击三角形运行按钮也可运行脚本,如下图所示:
PyCharm的断点调试功能十分强大,这里使用一个VeighNa的策略历史回测脚本来演示。
在左侧项目导航栏中点击鼠标右键,选择【New】-【File】, 在弹出的对话框中创建backtest.py:
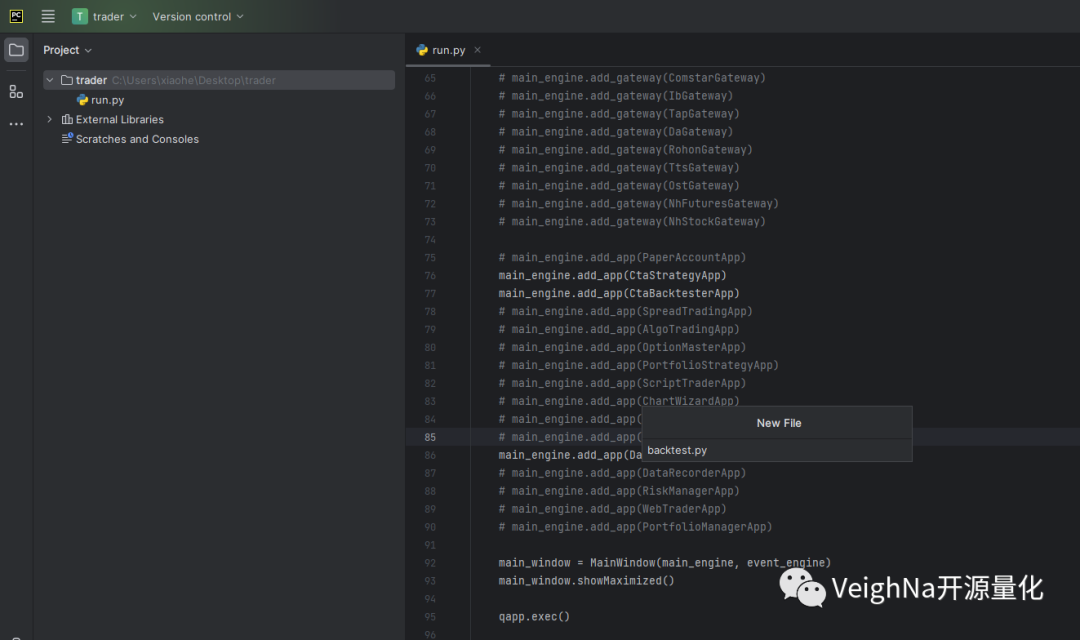
然后在文件中编写简单的策略回测代码(具体可参考Github仓库中的回测示例),在想要调试的地方打上断点,如下图所示:
点击鼠标右键选择【Debug 'backtest'】, 即可开始调试脚本:
此时项目界面右上角已经可以看到backtest.py的运行记录,后续也可以通过点击这里的按钮直接启动调试任务:
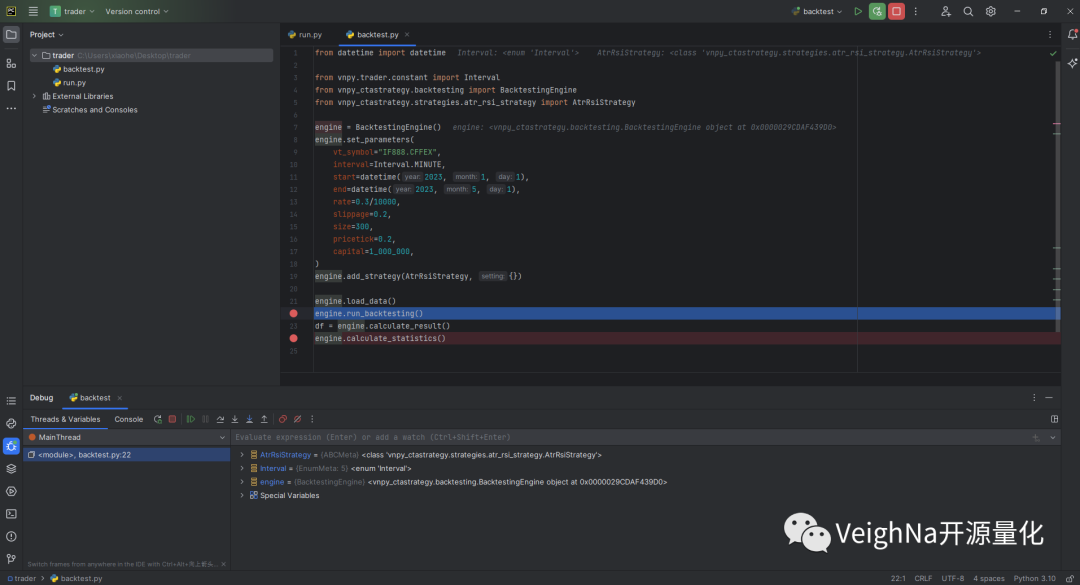
启动调试后,可以看到主界面底部的Debug窗口开始输出程序运行信息,并且程序会暂停运行在第一个断点处。左侧显示的是线程信息,右侧则是当前上下文中的变量信息:
点击类似播放键的【Resume Program】即可继续运行调试,直到下一个断点处再次暂停:
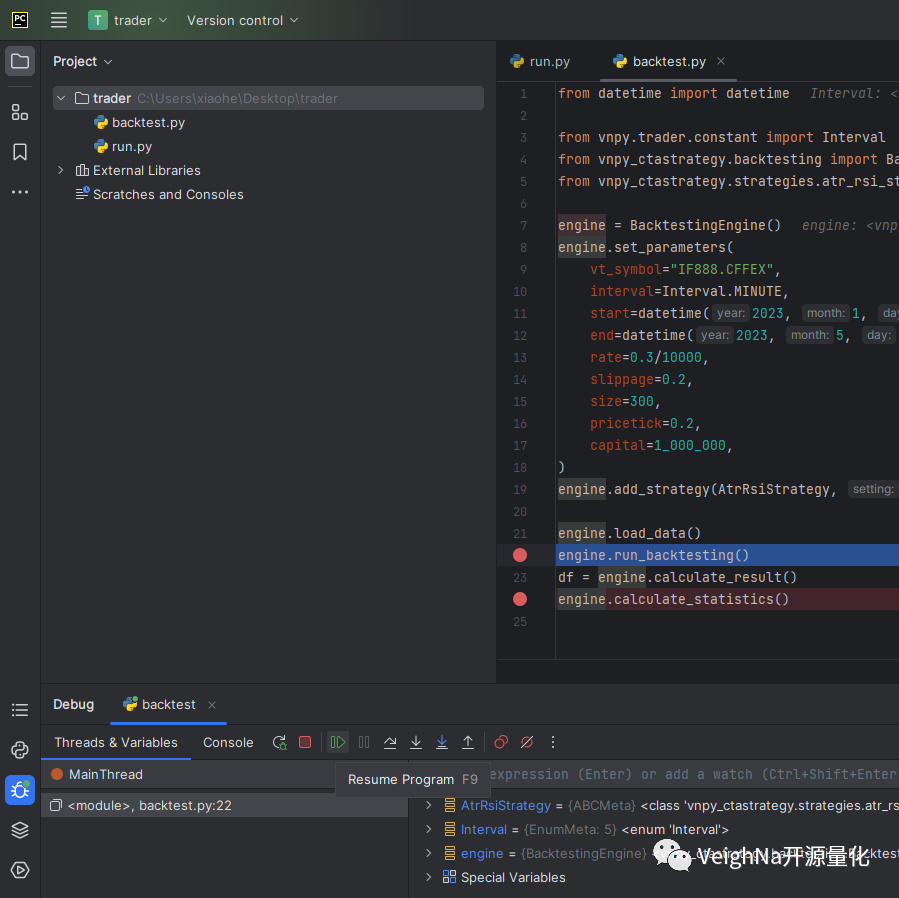
此时可以看到底部右侧监控窗口中,当前上下文中的变量发生了变化:
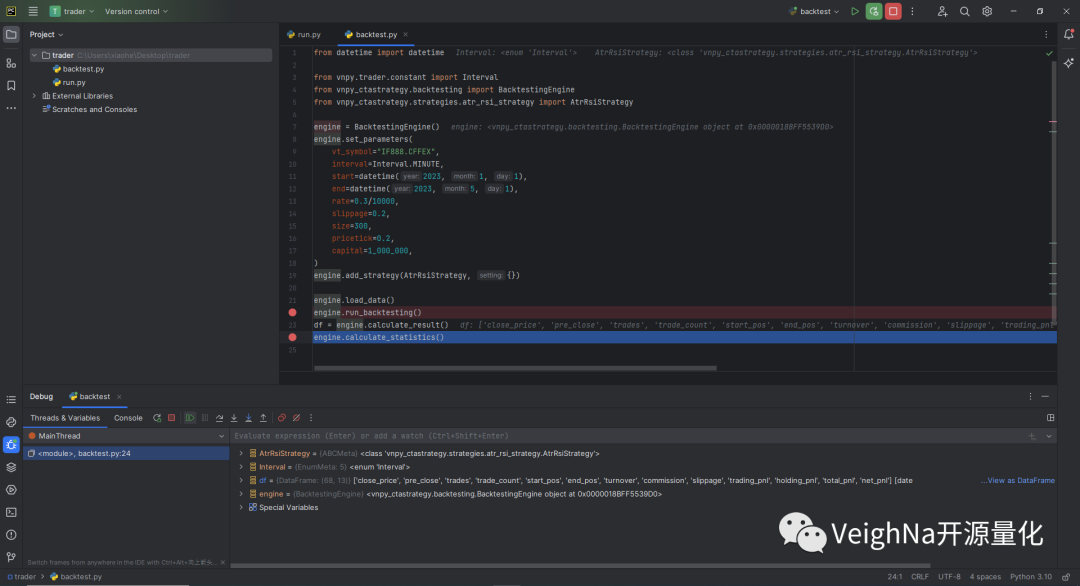
后续重复上述步骤,点击【Resume Program】直到调试结束,可以看到Debug窗口的相应输出:
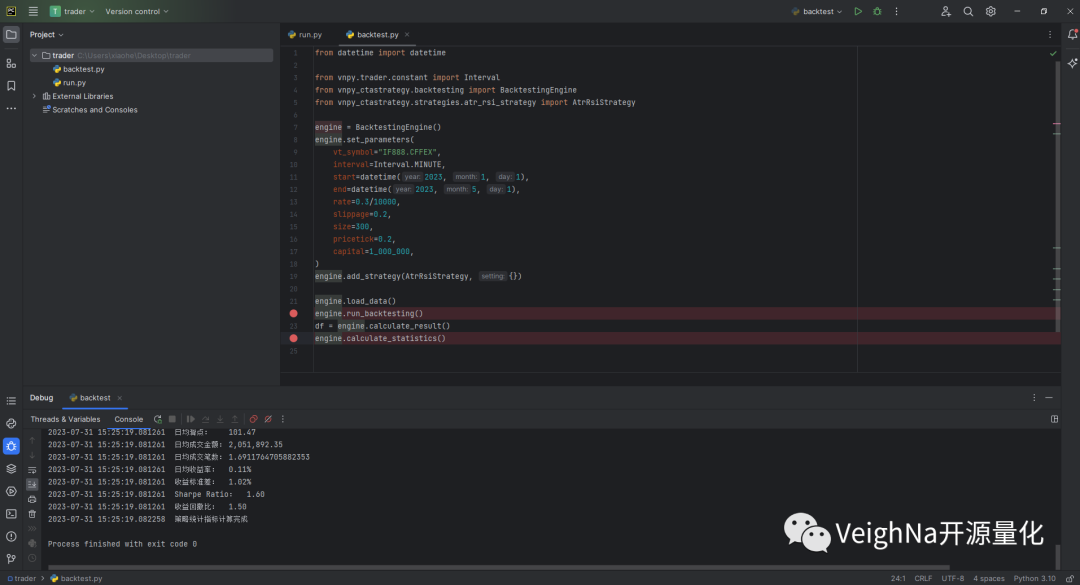
调试完之后,点击【Rerun 'backtest'】即可重新调试:
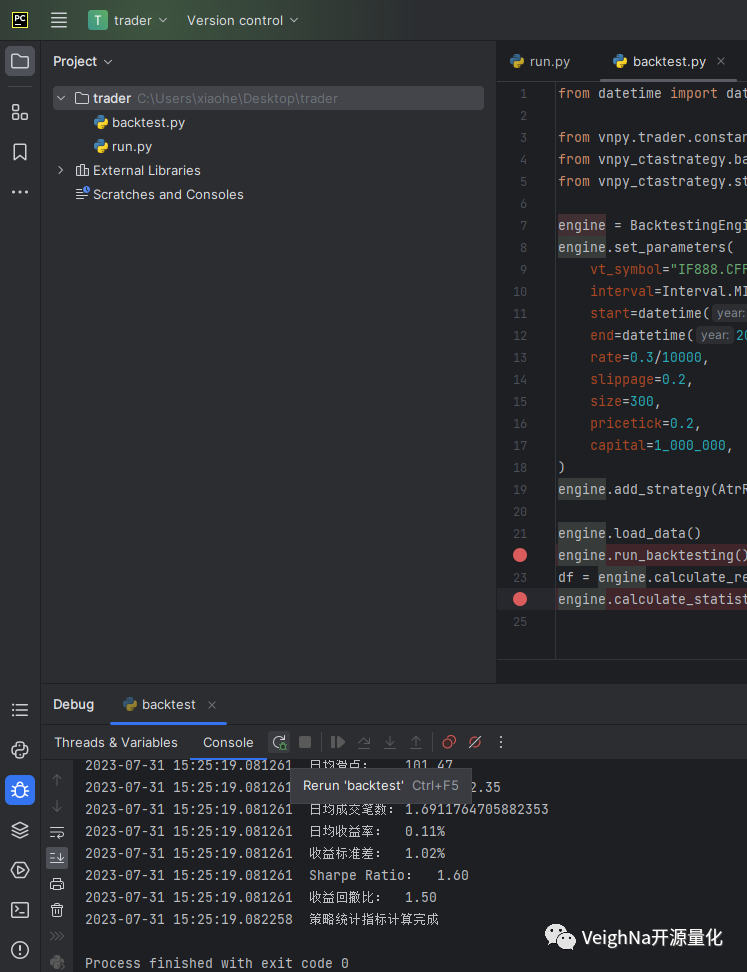
在调试过程中,点击【Step Into】可以进入函数的内部查看运行时的细节状态:
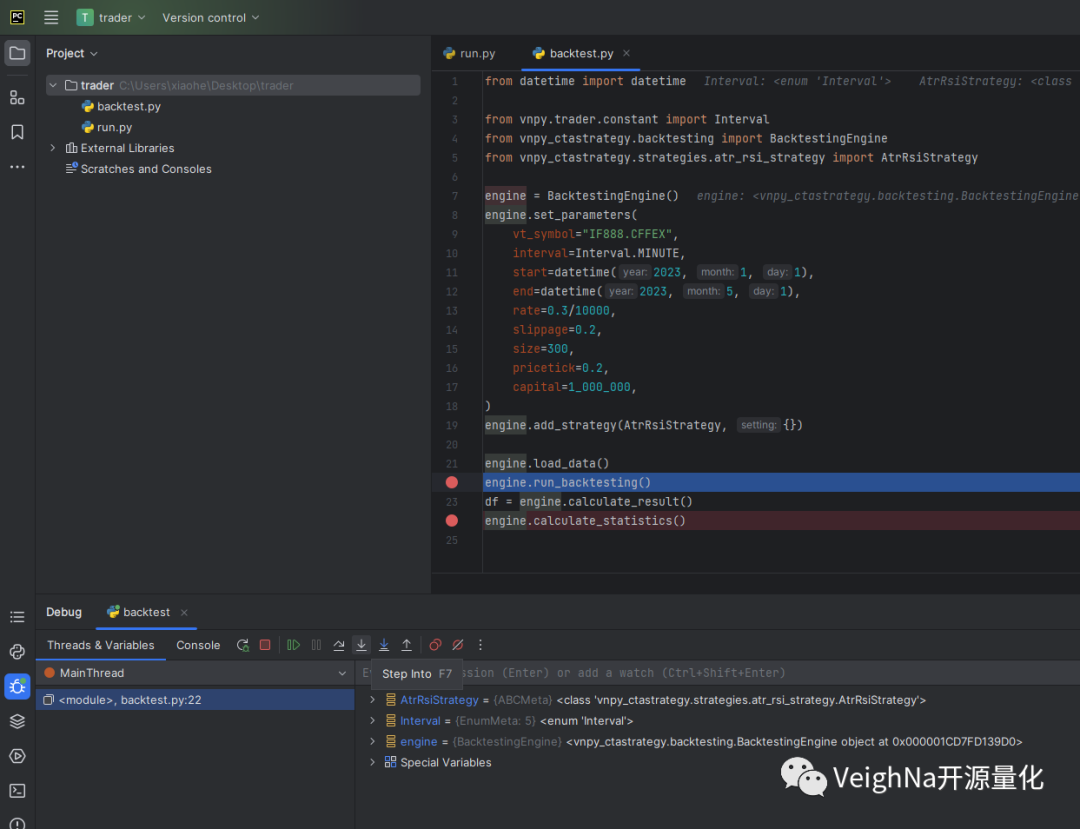
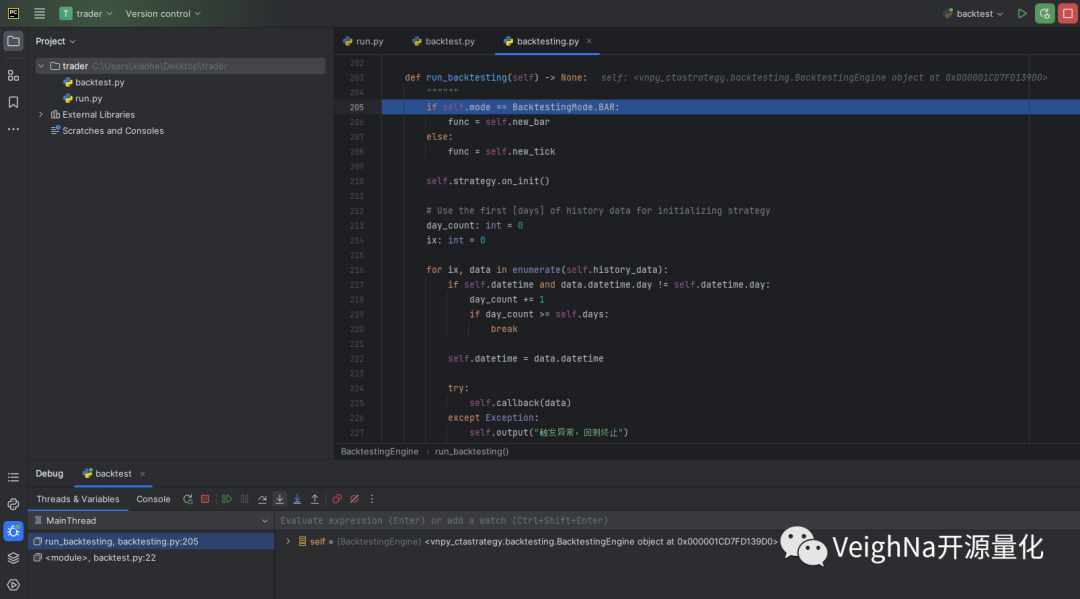
点击【Step Out】则可跳出当前函数,查看外层调用栈的状态:
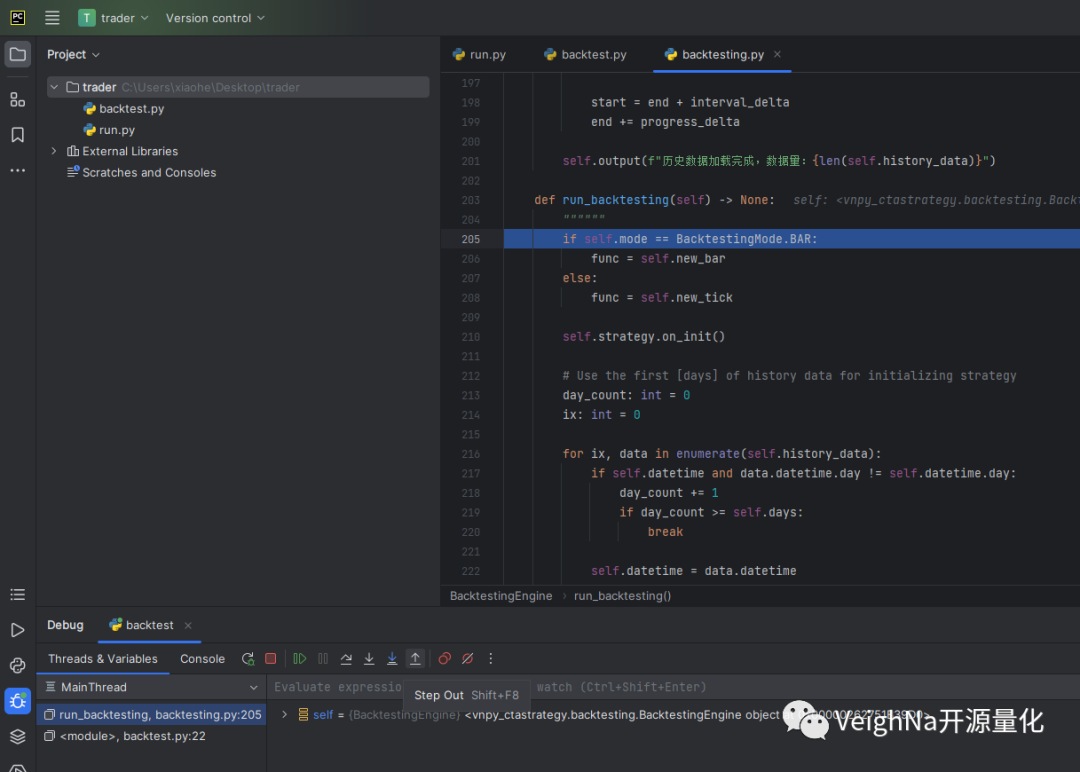
点击【Step Over】可越过子函数(子函数会执行):
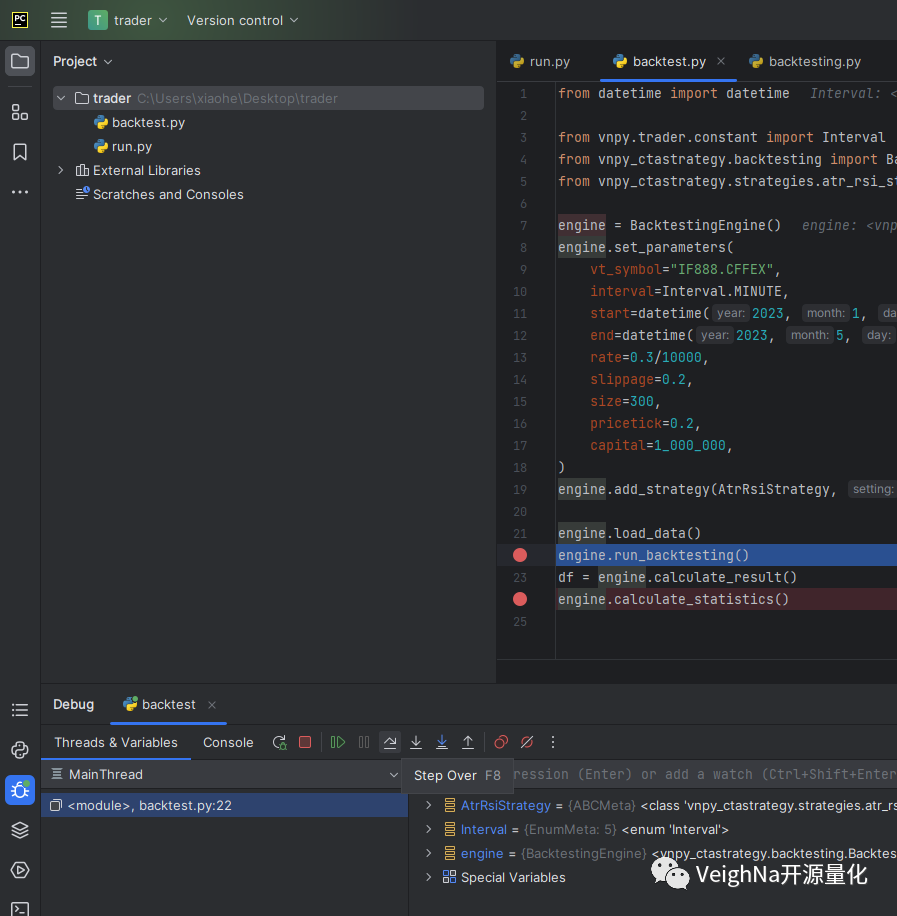
点击【Stop 'backtest'】则会直接停止当前程序的运行:
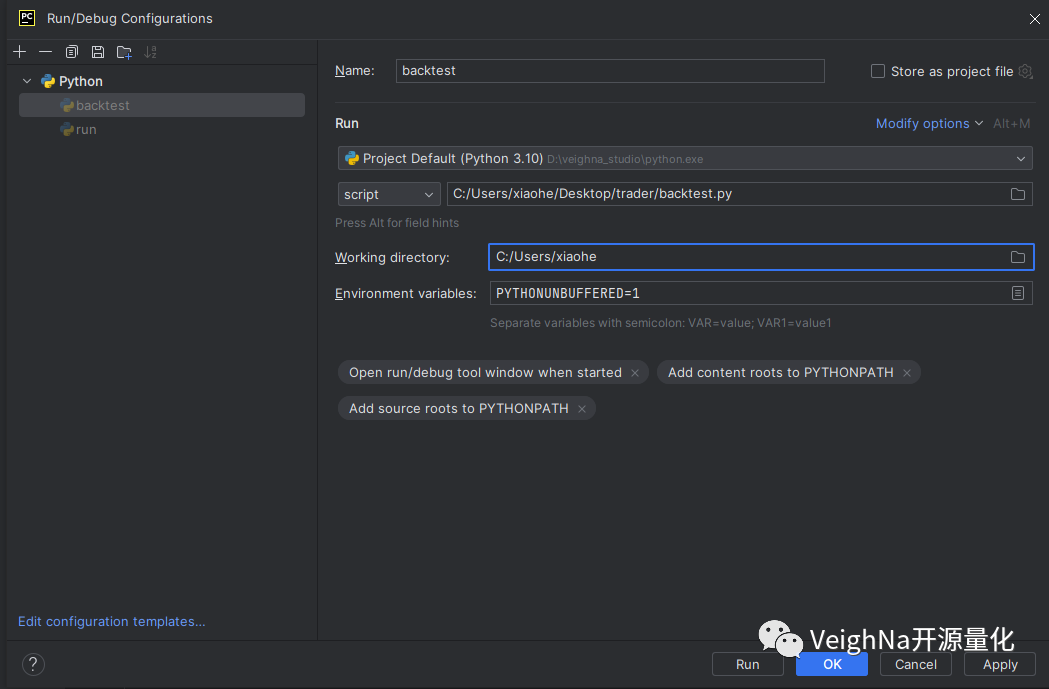
在PyCharm中新建项目时,默认是在当前目录下运行程序。若需要指定程序运行的目录,可以点击项目界面右上角的【Edit】进入【Run/Debug Configurations】界面:
修改程序启动时的目录【Working directory】即可:
通常情况下,PyCharm只能在Python解释器中启动的线程里进行代码断点调试。之前有部分用户反馈过尝试在C++回调函数(如CTP API接口、PySide图形库等)中打断点但无法起效的问题。针对这种情况,可以通过在代码中设置断点的方式,来实现对非Python线程(即C++线程)的断点调试。
在项目左侧导航栏中点击鼠标右键,选择【New】-【File】, 创建geteway_test.py。
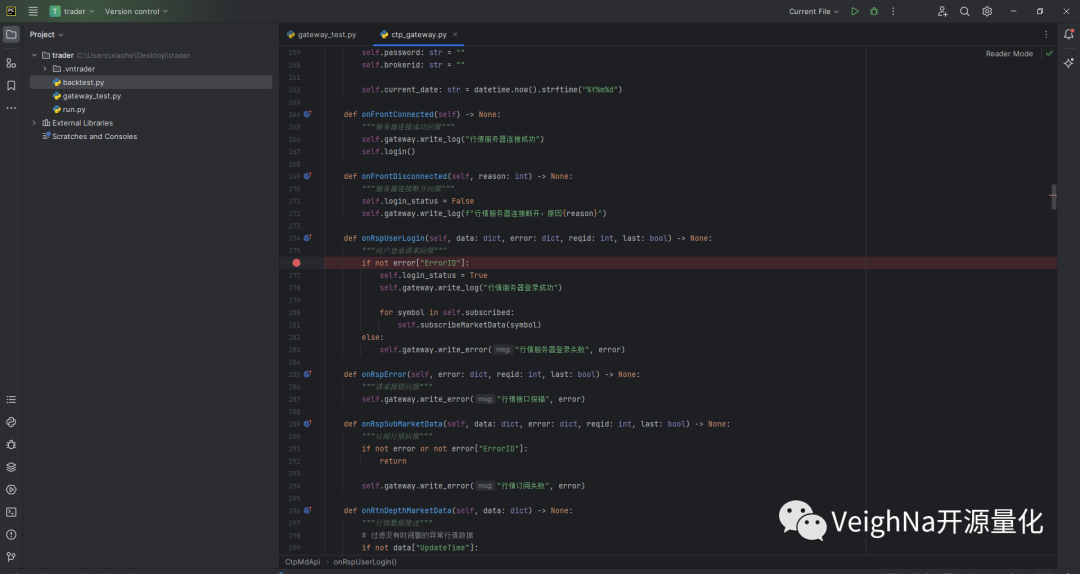
在创建成功的geteway_test.py中添加一段脚本策略的代码(可参考该文件),然后按住Ctrl同时用鼠标左键点击代码中的CtpGateway,跳转至ctp_gateway.py的源码中,在想要调试的回调函数内打上断点(注意不要打在函数定义的def那一行),如下图所示:
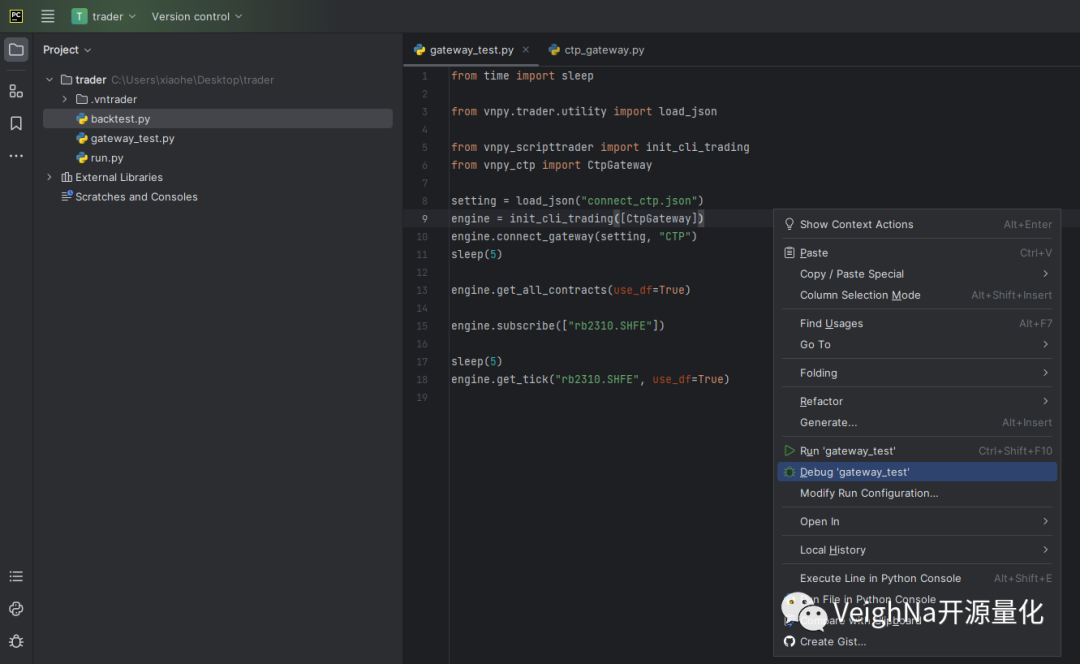
回到gateway_test.py,点击鼠标右键选择【Debug 'gateway_test'】开始调试:
请注意,如果用load_json函数读取connect_ctp.json,请确保读取对应.vntrader文件夹的json文件中配置了CTP账户登录信息。
此时可观察到并没有进入之前设定的断点,如下图所示:
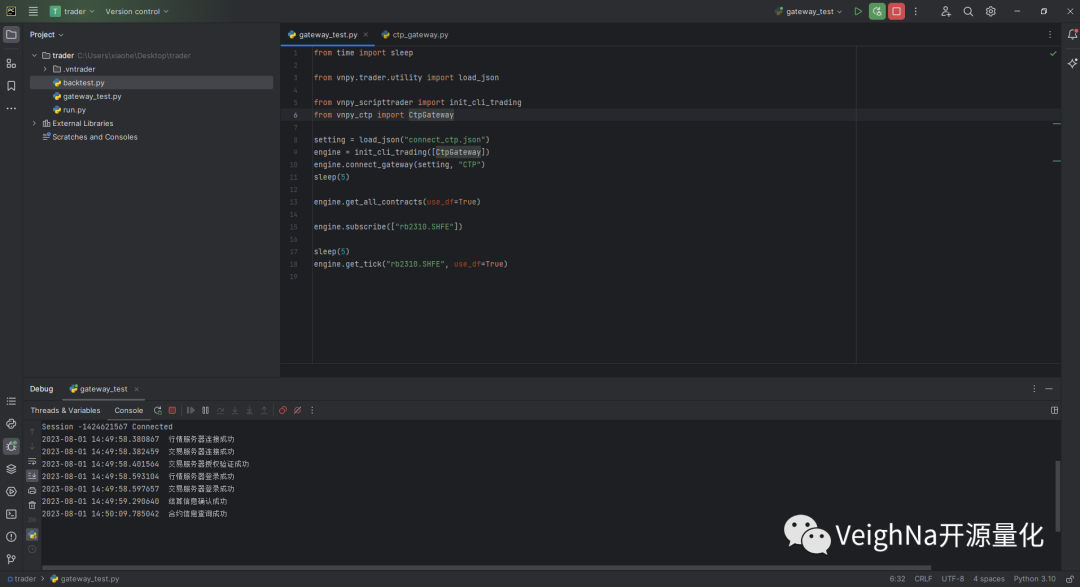
终止调试后,找到之前在ctp_gateway.py中设定的断点处,在回调函数内的断点之前添加以下代码:
import pydevd
pydevd.settrace(suspend=False, trace_only_current_thread=True)请注意:
然后再次运行调试gateway_test.py脚本:
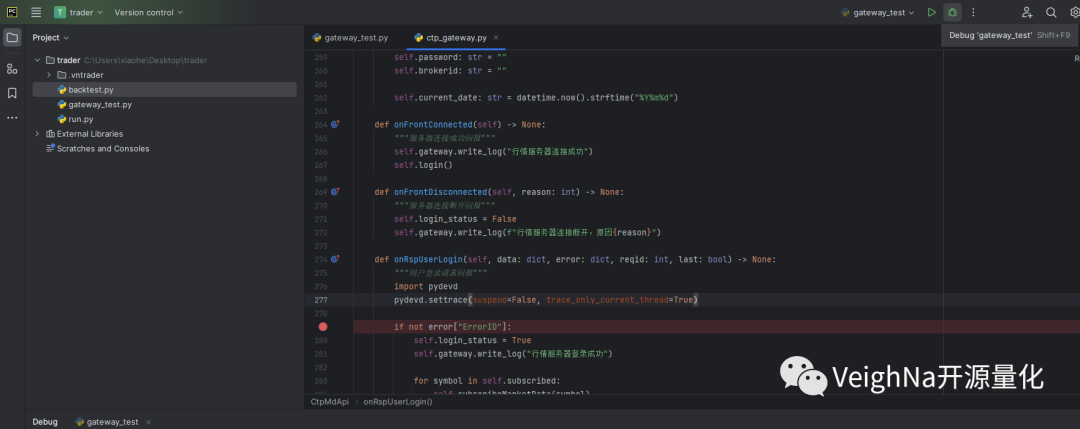
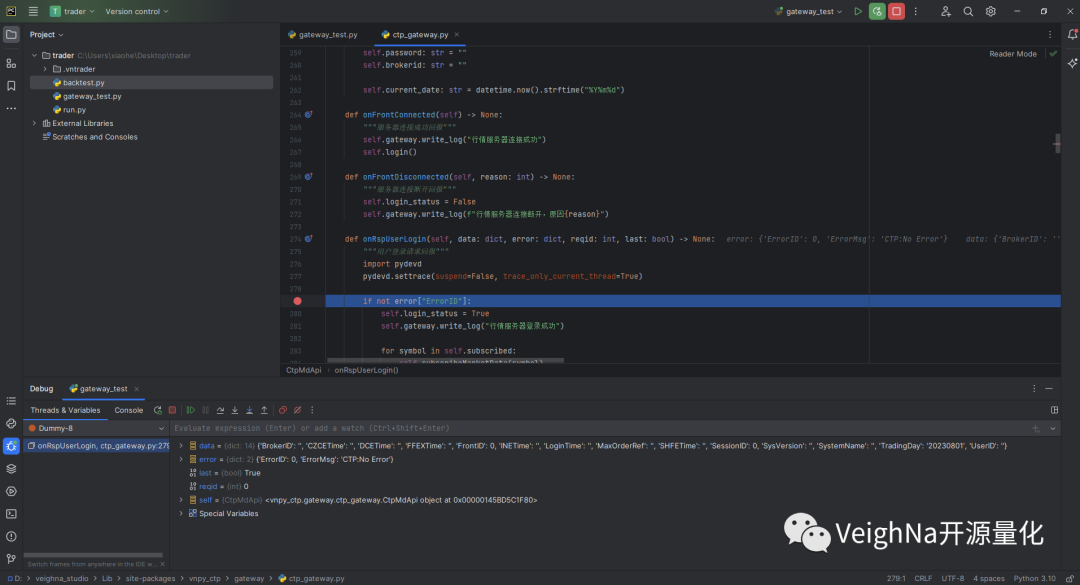
此时可以看到底部的调试窗口中开始输出相关信息,同时程序暂停在了之前设置的断点处。左侧显示的是线程信息(可以看到多了一个Dummy线程显示),右侧显示的是变量信息(可以看到回调函数的入参):
发布于veighna社区公众号【vnpy-community】
原文作者:用Python的交易员 | 发布时间:2023-7-5
2023年第4场VeighNa社区活动开始报名,本场活动将在上海举办,分享主题是【VeighNa Docker量化交易容器解决方案】。
本场活动提供30个线下名额,报名优先对机构量化从业人员开放,感兴趣的同学不要错过!
内容:
初探Docker容器化技术
VeighNa Docker量化应用
构建专属VeighNa容器镜像
QA问答和交流环节
时间:7月29日 14:00-17:00
地点:上海
报名费:99元(Elite会员免费参加)
报名方式:扫描下方二维码报名,线下参会请记得【加群获取参会地址】!

发布于vn.py社区公众号【vnpy-community】
原文作者: 黄太哲、李思佳 | 发布时间:2023-06-21
上篇文章分享了BollMACD策略对焦炭(j99.DCE)在分钟级别回测运行的结果,接下来为了更全面地认识BollMACD策略,我们也尝试对焦炭进行小时级别的回测。
回测参数:
交易成本
策略参数
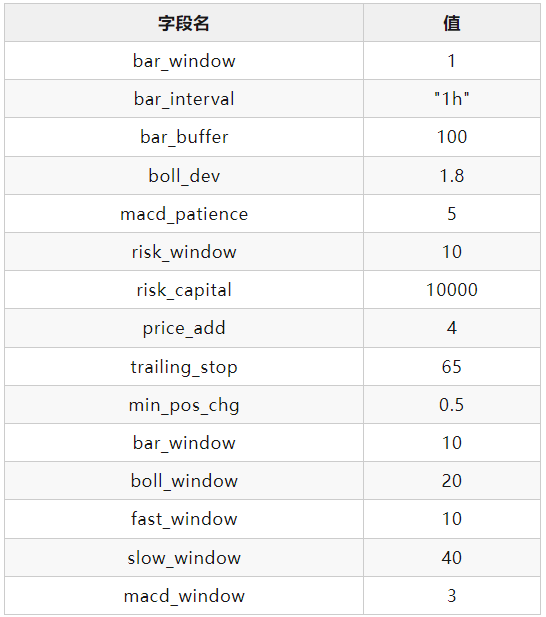
j99.DCE(焦炭)

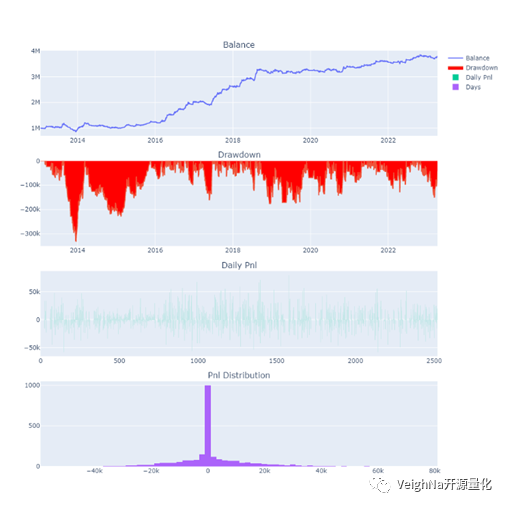
可以看到资金曲线的整体形状和分钟线的结果较为一致,体现了不错的跨时间周期普适性。
除了时间周期这一维度,我们还从不同期货品种的角度出发,用BollMACD策略对橡胶、螺纹钢及棉花三种商品期货进行了尝试,结果如下:
ru99.SHFE(橡胶)
回测参数:
交易成本
策略参数
rb99.SHFE(螺纹钢)
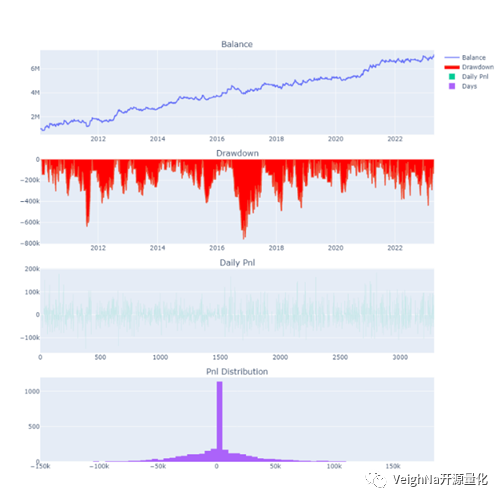
回测参数:
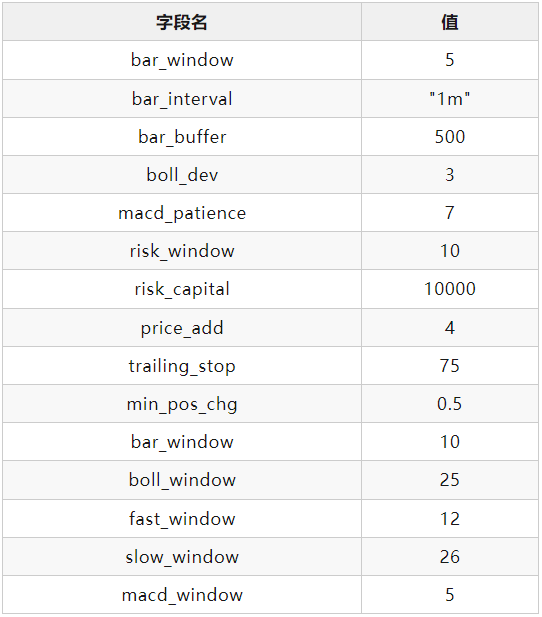
交易成本
策略参数
CF99.CZCE(棉花)

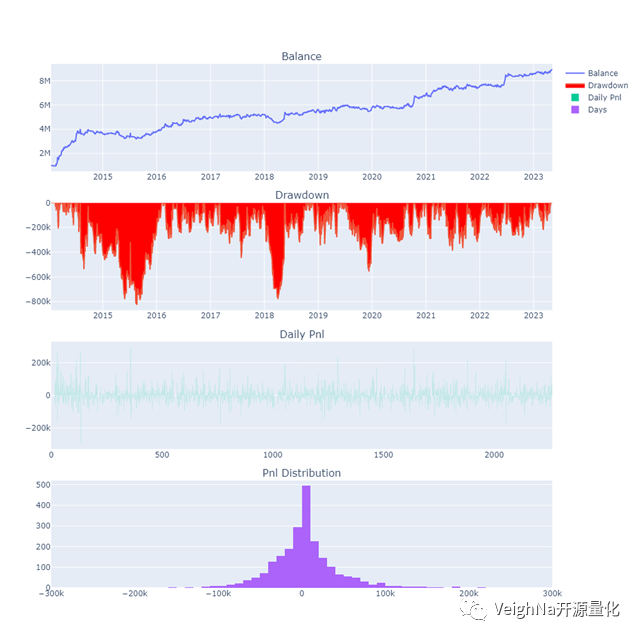
回测参数:
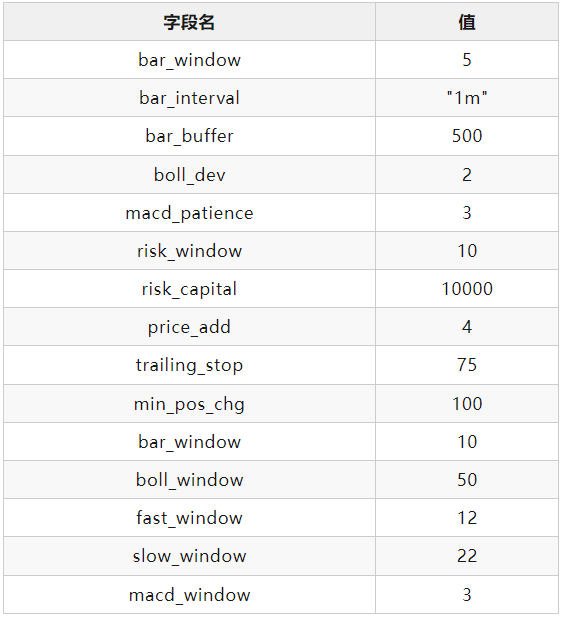
交易成本
策略参数
至此,围绕BollMACD策略的研究画上了句点。两大著名的CTA指标并肩合作,共同塑造了这一优秀策略,也是量化研究中站在巨人肩膀上进一步探索与发展的实践。
今年接下来的时间里【Elite量化策略实验室】系列会持续更新,努力为大家带来更多量化策略深入解析。
VeighNa Elite版已正式上线发布1.0.4版本,目前对量化私募机构的投研人员提供一个月免费试用,感兴趣的同学请扫码添加小助手:
免责声明
文章中的信息或观点仅供参考,作者不对其准确性或完整性做出任何保证。读者应以其独立判断做出投资决策,作者不对因使用本报告的内容而引致的损失承担任何责任。
发布于vn.py社区公众号【vnpy-community】
原文作者:李思佳 | 发布时间:2023-06-12
更新于月前的VeighNa 3.7.0版本新增了量化交易容器解决方案VeighNa Docker,《VeighNa发布v3.7.0 - 量化交易容器解决方案VeighNa Docker!》一文中,介绍了在Linux服务器环境下的VeighNa Docker安装步骤。
与前文不同的是,本文是基于Windows操作系统WSL2环境下的 VeighNa Docker安装指南。文章以Windows 10为示例操作系统,Windows11系统的操作方式与之类似,尽管存在细微差异,但无需担心操作系统版本差异会导致安装步骤发生巨大变化。
同时,文章使用的Ubuntu为22.04 LTS版本,请谨慎选择其他版本作为Linux发行版的部署(可能细节步骤差异较大)。需要特别注意的是,部分Windows操作系统自带的WSL并不足以支持接下来的操作,请务必确保跟随指南完成WSL2的部署再进行Docker安装。
如果已经有完整的WSL2部署,可从【基于Ubuntu的Docker安装】开始;如果也已经完成了Docker的正确安装且完成了中文环境的配置,可直接从【VeighNa Docker安装开始】。
内容目录
1.虚拟环境部署
2.WSL2及Ubuntu部署
3.基于Ubuntu的Docker安装
4.Docker中文环境配置
5.VeighNa Docker安装
1.1. 检查Windows操作系统内部版本,在命令提示符(CMD)中运行winver命令,会弹出如下图的窗口:
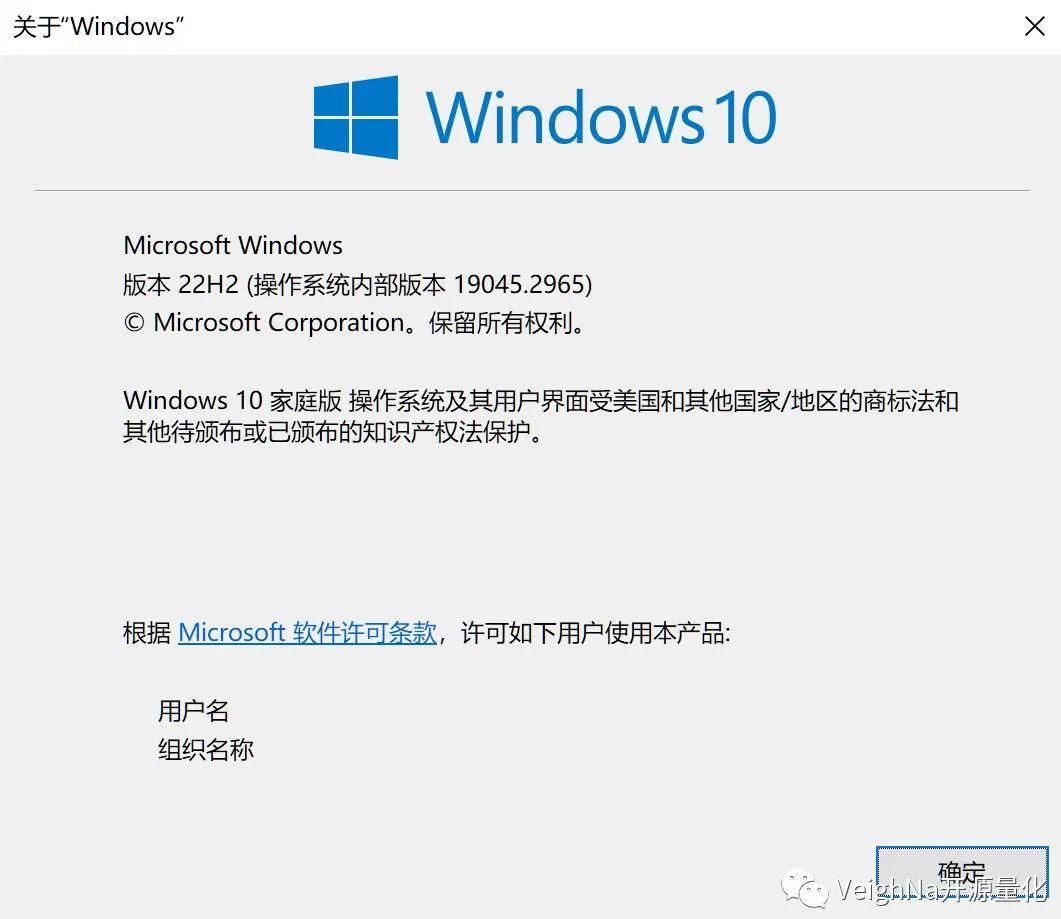
请检查【操作系统内部版本】,确保内部版本在19041及以上。若版本过低,推荐使用Windows官方更新助手,更新过程中,系统可能会多次重启。
1.2. 查看CPU的虚拟化支持特性:进入任务管理器,点击导航栏中的“性能”进入如图所示的界面。注意右下角“虚拟化”一栏状态是否为“已启用”。
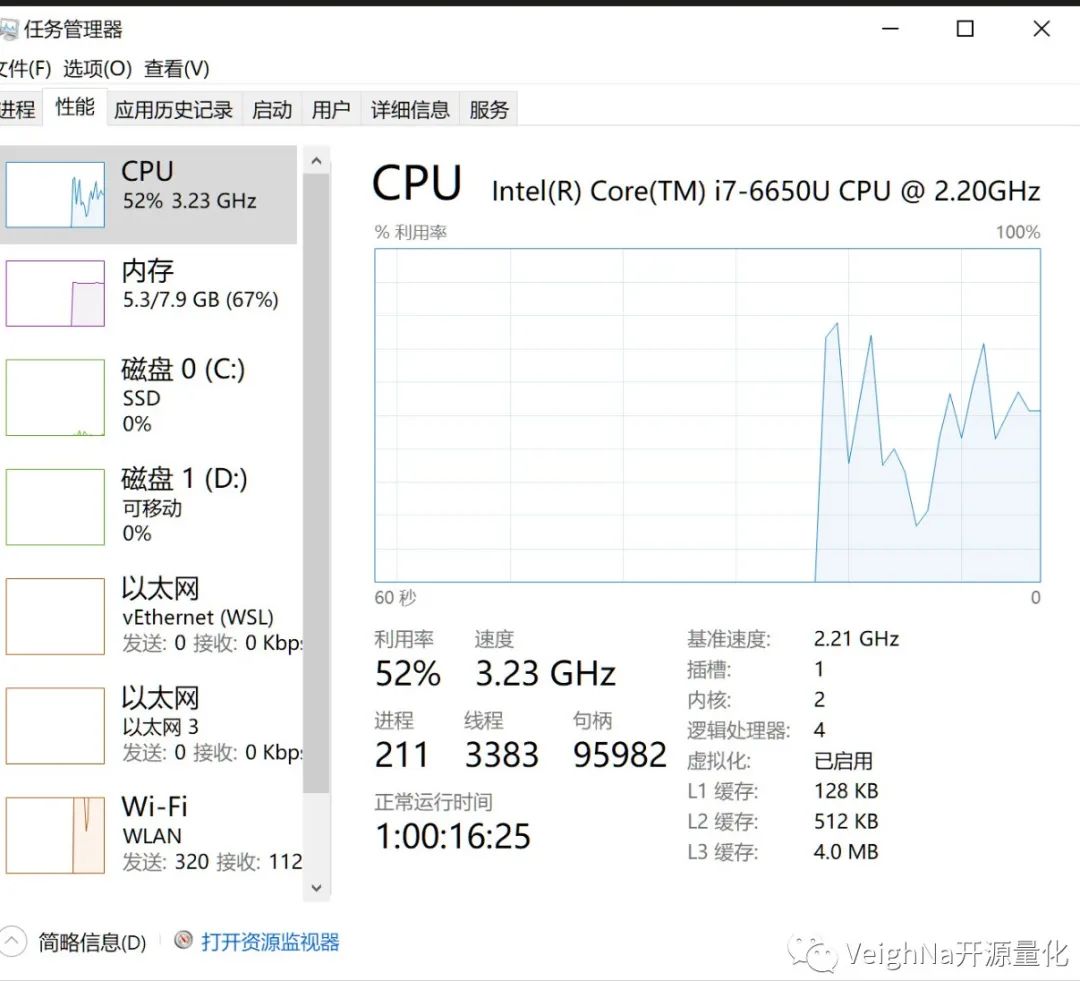
若显示【已禁用】,请耐心进行如下操作:
进入BIOS
找到Virtualization Technolog或Intel Virtualization Technology选项
选择上述选项
更改完成后,要进行保存才能够生效
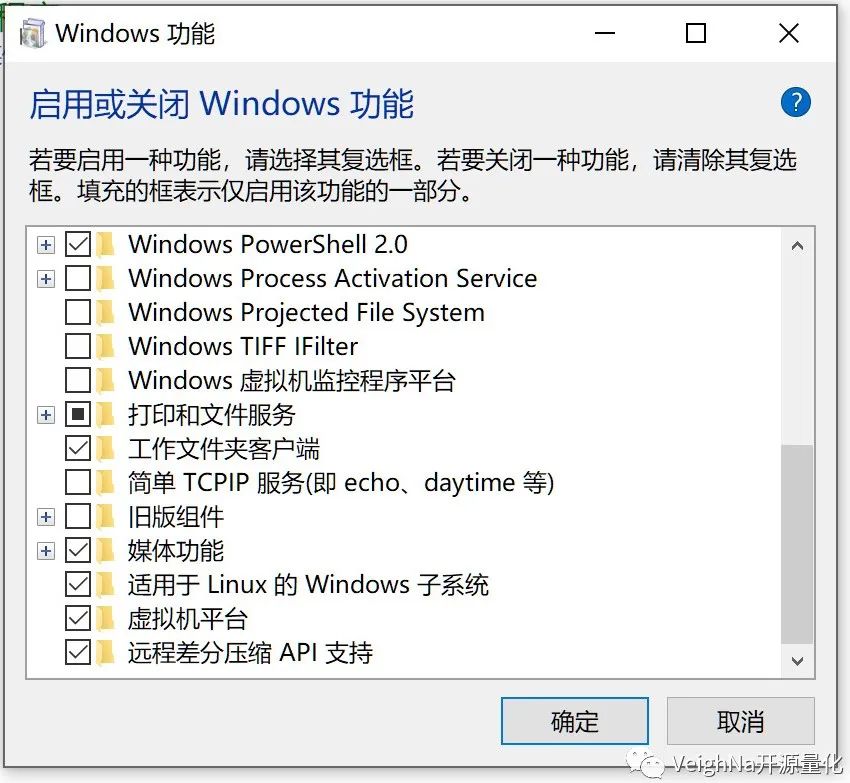
1.3. 在“控制面板\程序\程序和功能”中打开“启用或关闭Windows功能”,并勾选【适用于Linux的Windows子系统】和【虚拟机平台】,点击确认键退出页面。
2.1. 下载WSL2需要使用的Linux内核:
下载完成后,双击运行更新包,系统将提示需要管理员权限,选择【是】以批准此安装;
2.2. 将WSL2设置为默认版本并更新到latest版本,管理员权限下在命令提示符(CMD)中运行命令:
wsl --set-default-version 2
wsl --update
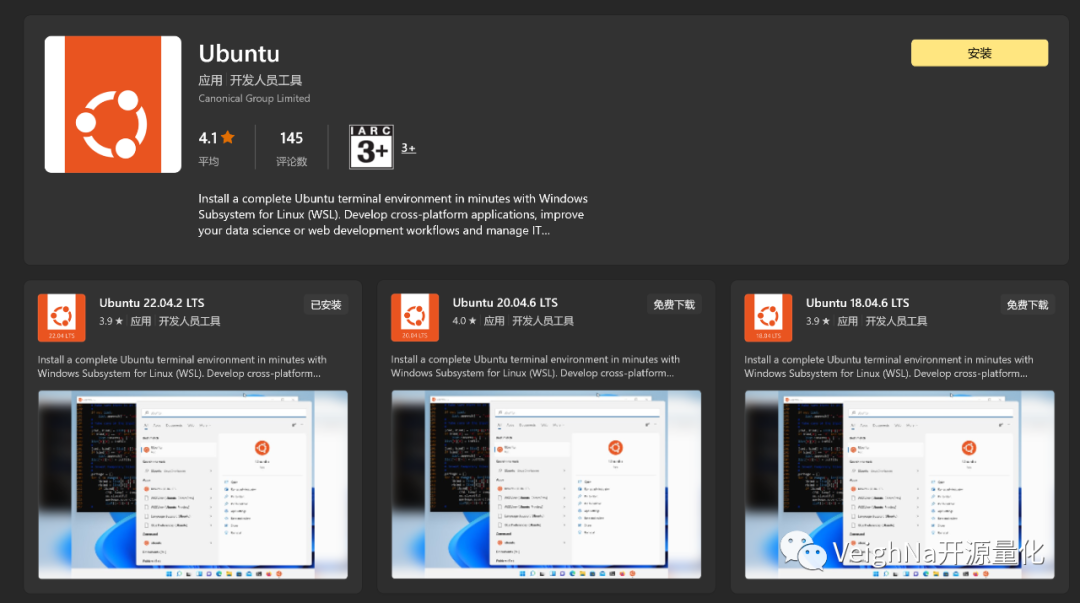
2.3. 安装Ubuntu 22.04 LTS:
打开Microsoft Store,查找Ubuntu 22.04.2 LTS并获取下载安装,请注意,不要在本步骤立即启动该Linux分发:
2.4. 运行以下命令,注销并卸载以前的Linux版本,以便重新安装干净的Linux(Ubuntu):
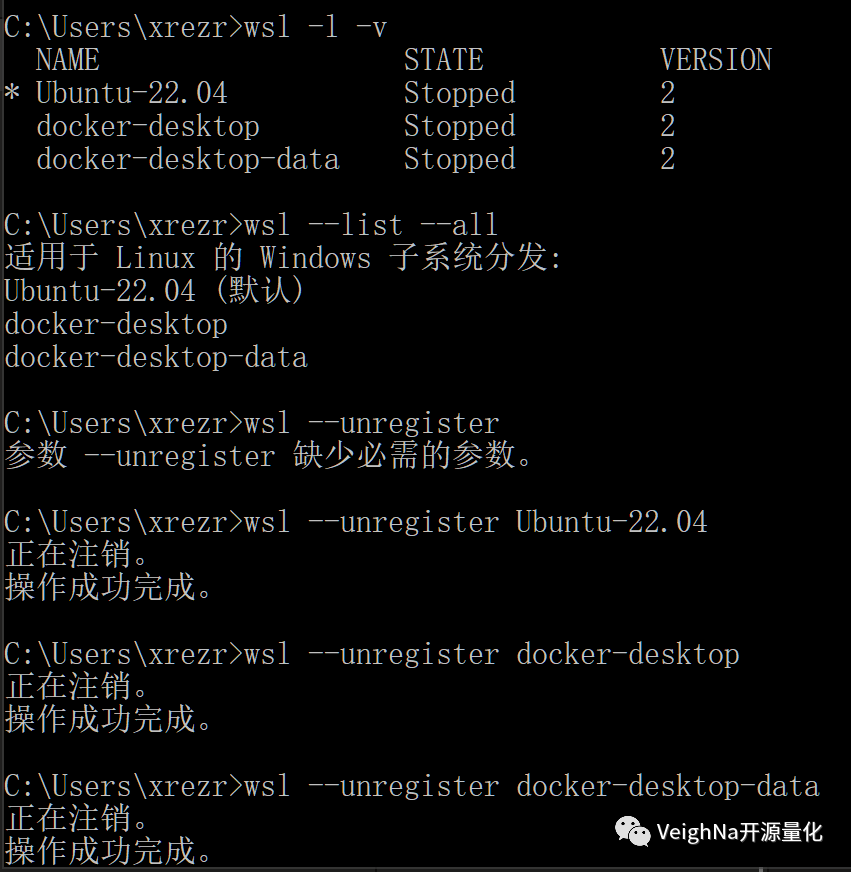
wsl -l -v
wsl --list --all
--unregister Ubuntu-22.04
--unregister docker-desktop
--unregister docker-desktop-data
运行结果如下图所示:
2.5. 以管理员身份运行Ubuntu 22.04.2 LTS.exe:
首次启动新安装的 Linux 分发版时,将打开一个命令行窗口,系统会要求等待一分钟或两分钟,以便文件解压缩并存储到电脑上,后续每次使用时的启动时间通常不到一秒;
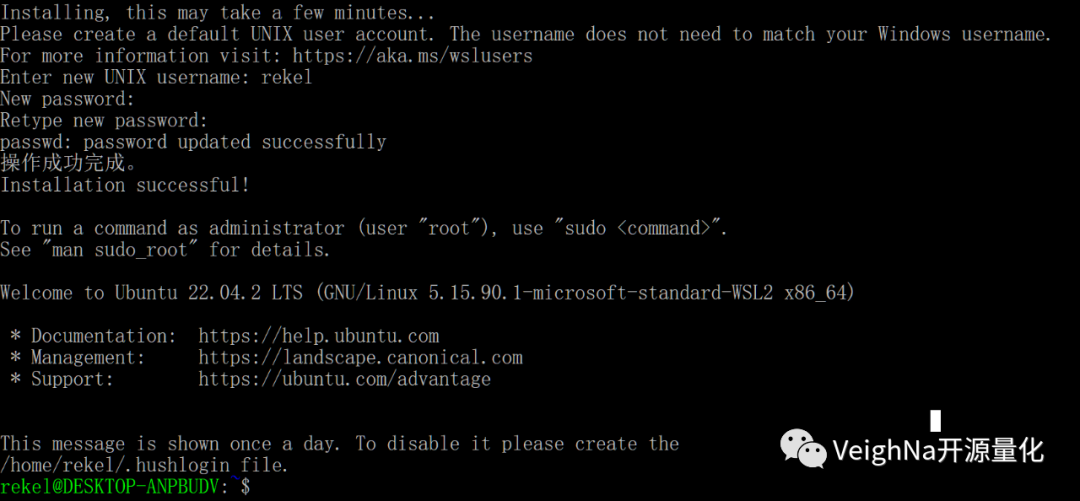
2.6. 为新的 Linux 分发版创建用户帐户和密码:
当完成文件解压存储后,Ubuntu将显示“Enter new UNIX username:”,用户可以按照要求进行用户名的设置。需要注意的是,用户名的表达规则需要符合Ubuntu对命名规定的正则表达式(#NAMEREGEX="^[a-z][-a-z0-9]*\$"),即用户名:
完成用户名设置后,Ubuntu将提示用户设定相应的“New password”,并需要再次输入以确认密码。请注意,在Ubuntu中的密码设置,即便键入任意字符密码也不会显示在屏幕上,这并不是没有输入,只是没有打印在屏幕上,因此建议用户不要设置过于复杂的密码。密码设置成功后,Ubuntu将输出日志,如图所示,当带用户名的可操作命令行出现时则可认为成功安装并设置了与 Windows 操作系统集成的 Linux 分发:
2.7. 更新系统上的软件包,在Ubuntu命令面板中使用命令:
sudo apt-get update
至此,WSL2及Ubuntu的部署已经完成,如果依照流程仍然无法顺利运行Ubuntu,请参考WSL官方的疑难解答排查原因并重新安装Ubuntu。另外,Ubuntu终端下Windows快捷键是无法使用的,可使用鼠标右键粘贴命令到Ubuntu命令面板。
3.1. 在官网下载Docker Desktop并安装:
https://www.docker.com/products/docker-desktop/
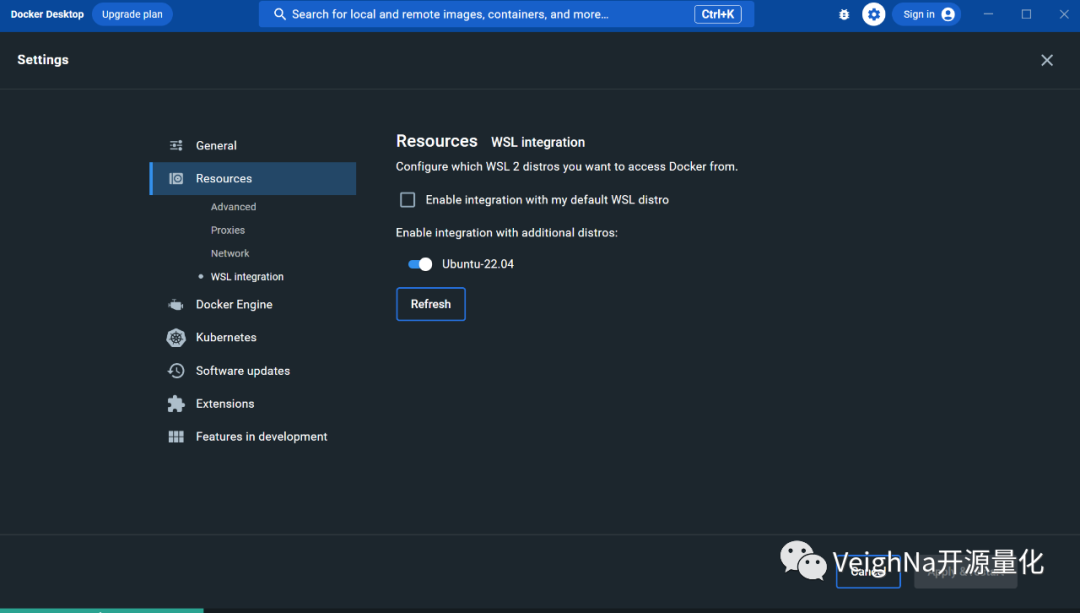
3.2. 运行Docker Desktop并更改如下设置项:
Docker Engine
{ "insecure-registries": [],
"registry-mirrors": [
"http://hub-mirror.c.163.com"
]
}
Resources:WSL integration
3.3. 验证Docker Desktop与Ubuntu集成。在Ubuntu终端运行命令:
sudo docker run hello-world
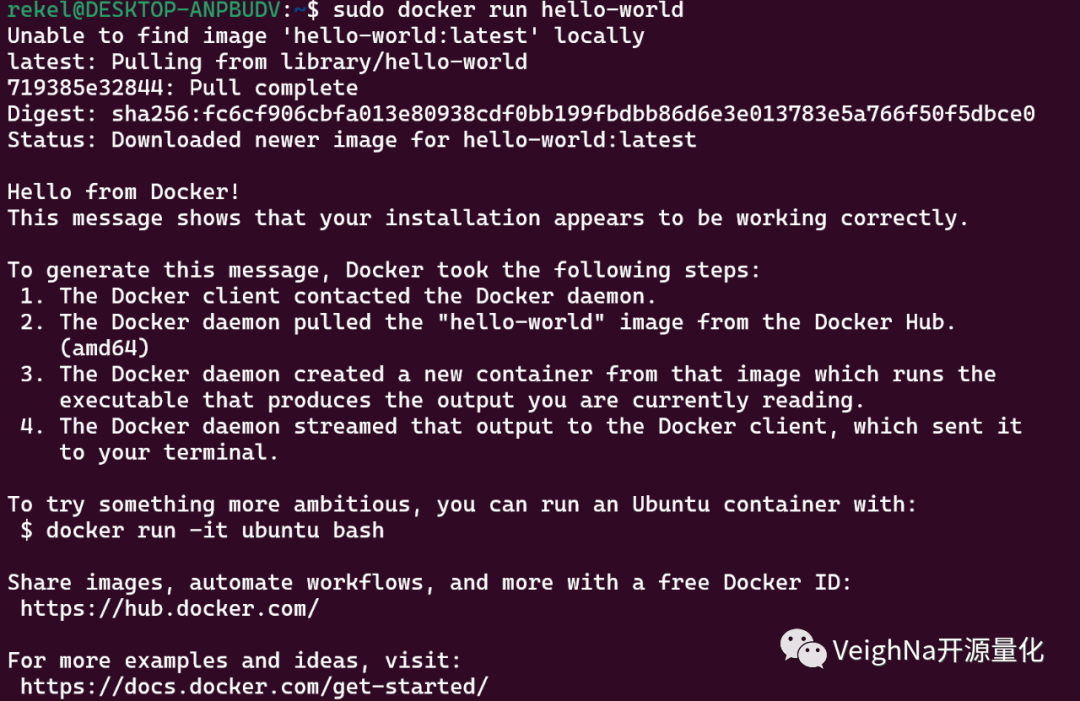
在Ubuntu终端看到"Hello from Docker!"信息,并且在Docker Desktop中Containers列表中看到一个如下图被随机命名且镜像为“hello-world”的容器,则说明Docker安装无误,可以进行下一步操作。

与在Linux服务器环境下操作不同的是,WSL2环境下的用户本地存在X server,默认不做访问控制,因此无需像Linux环境在每次重启系统后必须运行xhost相关命令以开放权限。特殊情况需要解除访问控制,则运行命令:
apt-get install x11-xserver-utils
xhost +

WSL的中文环境设定并非必须在VeighNa Docker安装前完成,用户可在安装完毕后进行。但需注意,未执行此步骤,VeighNa Docker中的中文字符可能会出现乱码。
4.1. 安装中文字库及中文语言包:
apt install fonts-noto-cjk
sudo apt install language-pack-zh-hans language-pack-zh-hans-base
4.2. 设置操作系统语言为UTF-8,该设置将在终端重启后生效:
echo "LANG=zh_CN.UTF-8" >> ~/.profile
4.3. 设置整个操作系统的默认语言为中文:
sudo dpkg-reconfigure locales
此时将出现软件包设置页面,如下图所示:
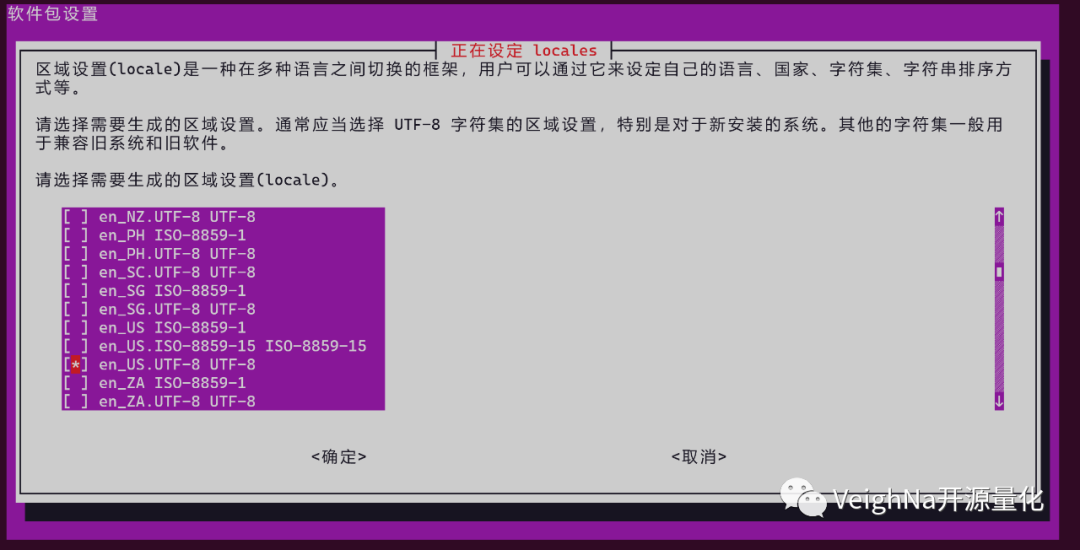
使用方向键滚动找到zh_CN.UTF-8后,点击空格键选中,然后用Tab键切换至【确定】。
5.1. 在ubuntu用户下创建文件夹:
mkdir trader
ls
可将"trader"更改为任意文件夹名称,以该命名的文件夹为例(此后文章均使用此例),输出结果如下图:

后续如果想要删除文件请使用如下命令。注意,如果在文件夹内的文件,请提供路径和文件名称来进行删除操作:
sudo rm -f trader
5.2. 进入新建的文件夹,在该文件夹下创建文件run.py,并检查是否创建成功:
cd trader
touch run.py
ls

5.3. 可以通过"cd .."回到上一级目录,通过"pwd"及"cd -"均可显示当前文件路径,记录文件路径或者文件夹路径,以便后续操作;
5.4. 使用nano(或者其他习惯使用的编辑器软件)打开创建的run.py文件:
sudo nano /user/trader/run.py打开run.py文件后,在Ubuntu命令面板内右键粘贴以下内容:
from vnpy.event import EventEngine
from vnpy.trader.engine import MainEngine
from vnpy.trader.ui import MainWindow, create_qapp
from vnpy_ctp import CtpGateway
from vnpy_ctastrategy import CtaStrategyApp
from vnpy_ctabacktester import CtaBacktesterApp
def main():
"""Start VeighNa Trader"""
qapp = create_qapp()
event_engine = EventEngine()
main_engine = MainEngine(event_engine)
main_engine.add_gateway(CtpGateway)
main_engine.add_app(CtaStrategyApp)
main_engine.add_app(CtaBacktesterApp)
main_window = MainWindow(main_engine, event_engine)
main_window.showMaximized()
qapp.exec()
if __name__ == "__main__":
main()
请注意,对run.py进行更改后的退出方法不是通过右上角的关闭按钮,请确保run.py文件内容已经保存后,根据编辑器使用快捷键从文件编辑页面退回到命令面板。
5.5. 使用下列命令运行run.py文件:
docker run \
-e DISPLAY=$DISPLAY \
-v /tmp/.X11-unix:/tmp/.X11-unix \
-v /home/user/trader:/home \
veighna/veighna:3.7 python3 run.py
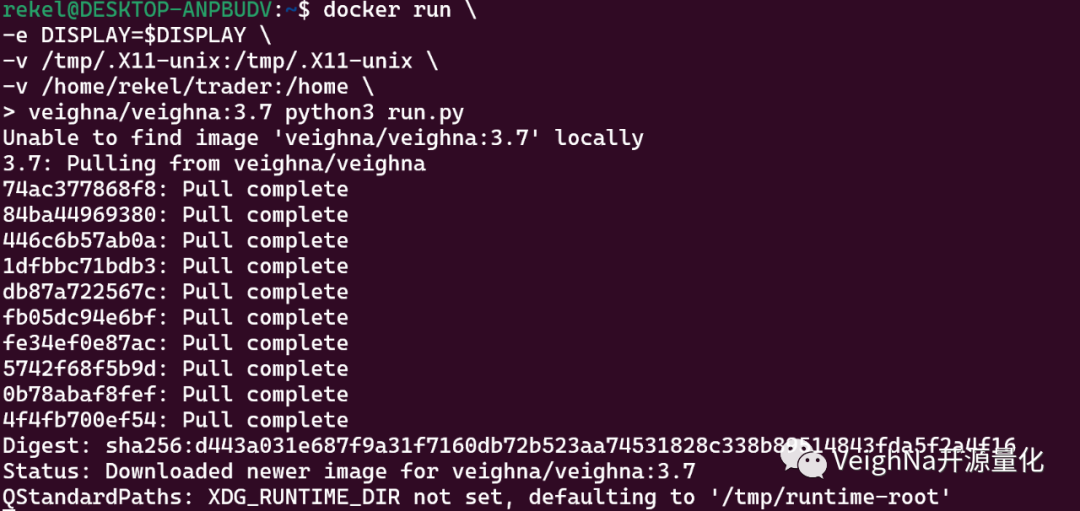
如果是首次运行,Docker引擎会自动从Docker Hub网站上下载拉取veighna/veighna:3.7镜像(大约几分钟的时间,取决于网络带宽),并在下载完成后直接启动容器,此时就可以看到熟悉的VeighNa Trader界面了:
同时,在Docker Desktop容器列表中会出现镜像名为 “veighna/veighna:3.7” 的容器实例,此后启动VeighNa Docker可直接点击容器右侧Action的播放键以运行,无需反复通过命令行在终端进行操作。

如果发现VeighNa Docker界面中出现中文乱码,请回到前面的WSL中文环境配置步骤检查语言配置。
发布于vn.py社区公众号【vnpy-community】
原文作者: 黄太哲、李思佳 | 发布时间:2023-05-30
本篇文章的分享内容为BollMACD策略,在各种互联网平台上围绕“Boll+MACD”主题的量化文章层出不穷,使得策略原作者的身份无法查证。
本文中通过VeighNa Elite平台对该思路进行了代码上的实现与改进,希望能给大家后续的策略研究带来些许灵感。

BollMACD策略希望利用布林通道和MACD双指标共振来完成对于交易信号的判断,由于在震荡行情下,MACD容易发生钝化,因此需要对于趋势判断更加敏锐的布林带协助对趋势的捕捉。
在VeighNa Elite平台下的EliteCtaStrategy模块中提供了专门的boll、macd等常用技术指标的计算函数来减轻策略代码化的工作量,并提供了协助交叉判断的cross_over及cross_below函数,这些函数的用法将在策略代码实现的内容里详细说明。
结合布林通道和MACD指标二者共同对趋势进行判断,可以得到以下的交易信号:
布林通道从通道突破的角度进行判断,结合使用均线交叉的MACD,使得策略对于趋势的判断更加稳健,布林通道的判断又补全了MACD高延迟的缺陷。需要指出的是,尽管互联网资料中广泛使用布林通道中轨方向来进行开仓信号判断,但在本策略的实测中,该方法的效果并不理想。
和之前的RumiStrategy一样,BollMacdStrategy也同样采用EliteCtaStrategy模块下的策略模板类EliteCtaTemplate开发,通过基础参数来配置策略运行的K线数据周期的方式,使得策略的开发更加简易和规范:
class BollMacdStrategy(EliteCtaTemplate):
"""布林带MACD策略"""
author = "VeighNa Elite"
# 基础参数(必填)
bar_window: int = Parameter(5) # K线窗口
bar_interval: int = Parameter("1m") # K线级别
bar_buffer: int = Parameter(500) # K线缓存
分别使用Parameter和Variable辅助类来定义策略的参数和变量:
# 策略参数(可选)
boll_window: int = Parameter(20) # 布林带窗口
boll_dev: float = Parameter(2.0) # 布林带标准差乘数
fast_window: int = Parameter(9) # 快线窗口
slow_window: int = Parameter(26) # 慢线窗口
macd_window: int = Parameter(4) # MACD窗口
macd_patience: int = Parameter(3) # MACD交叉回看窗口
trailing_stop: int = Parameter(75) # 移动止损系数
risk_window: int = Parameter(10) # 风险计算窗口
risk_capital: int = Parameter(1_000_000) # 交易风险投入
price_add: int = Parameter(5) # 委托下单超价
min_pos_chg: float = Parameter(0.05) # 持仓变动下限
# 策略变量
trading_size: float = Variable(0.0) # 交易数量
boll_up: float = Variable(999_999.0) # 布林带上轨
boll_down: float = Variable(-1.0) # 布林带下轨
time_coef: float = Variable(1.0) # 跟踪时间系数
intra_trade_high: float = Variable(999_999.0) # 持仓期间高价
intra_trade_low: float = Variable(-1.0) # 持仓期间低价
def on_history(self, hm: HistoryManager) -> None:
"""K线推送"""
# 计算布林带上下轨
channel_up, channel_down = boll(hm.close, self.boll_window, self.boll_dev)
self.boll_up = channel_up[-1]
self.boll_down = channel_down[-1]
# 计算MACD柱
macd_hist: np.ndarray = macd(hm.close, self.fast_window, self.slow_window, self.macd_window)[2]
# 记录MACD交叉
self.cross_array[:-1] = self.cross_array[1:]
if cross_over(macd_hist, 0):
self.cross_array[-1] = 1
elif cross_below(macd_hist, 0):
self.cross_array[-1] = -1
else:
self.cross_array[-1] = 0
在上述代码中,展示了EliteCtaStrategy模块中的boll函数和macd函数,下文将专注于对这两个关键函数的讲解。
boll – 计算布林通道上下轨
参数:
返回:
tuple[np.ndarray, np.ndarray]
macd – 计算MACD指标
参数:
返回:
tuple[np.ndarray, np.ndarray, np.ndarray]
同RUMI策略一样,借助EliteCtaTemplate提供的calculate_volume函数,可以轻松地计算出适合当前市场环境的交易委托数量,基于市场价格的波动水平对交易风险进行动态调整:
# 计算交易数量self.trading_size = self.calculate_volume(self.risk_capital, self.risk_window, 1000, 1)
在【Elite量化策略实验室】RUMI策略 - 1 文章中,已对EliteCtaTemplate提供的目标仓位交易执行功能进行了详尽的阐述。相信阅读过此文的读者能够在接下来的代码部分发现许多熟悉的内容:
# 初始化新一轮目标(默认不变)
new_target: int = last_target
# 判断交易信号
recent_crosses: np.ndarray = self.cross_array[-self.macd_patience:]
long_signal: bool = hm.close[-1] > self.boll_up and (recent_crosses >= 0).all() and (recent_crosses > 0).any()
short_signal: bool = hm.close[-1] < self.boll_down and (recent_crosses <= 0).all() and (recent_crosses < 0).any()
# 执行开仓信号
if not last_target:
if long_signal:
new_target = self.trading_size
elif short_signal:
new_target = -self.trading_size
# 突破阈值动态调仓
if last_target != 0:
pos_chg: float = abs(1 - self.trading_size / last_target)
if pos_chg > self.min_pos_chg:
if last_target > 0:
new_target = self.trading_size
elif last_target < 0:
new_target = -self.trading_size
# 记录时间系数变化
if not last_target:
self.time_coef = 1
self.bar_num = 0
elif self.bar_since_entry() >= self.bar_num:
self.time_coef = self.time_coef - 0.1
self.time_coef = max(self.time_coef, 0.5)
self.bar_num = self.bar_since_entry()
# 记录价格极大值和极小值
if self.bar_since_entry() == 0:
self.intra_trade_high = hm.high[-1]
self.intra_trade_low = hm.low[-1]
else:
self.intra_trade_high = min(self.intra_trade_high, hm.high[-1])
self.intra_trade_low = max(self.intra_trade_low, hm.low[-1])
# 移动止损平仓
trailing_value: float = (hm.open[-2] * self.trailing_stop / 1000) * self.time_coef
long_stop: float = self.intra_trade_low - trailing_value
short_stop: float = self.intra_trade_high + trailing_value
if last_target > 0 and hm.low[-1] < long_stop:
new_target = 0
elif last_target < 0 and hm.high[-1] > short_stop:
new_target = 0
# 设置新一轮目标
self.set_target(new_target)
# 执行目标交易
self.execute_trading(self.price_add)
# 推送UI更新
self.put_event()
基于EliteCtaTemplate提供的目标交易执行模式,可以显著降低策略编写的难度,同时也削减了后续策略代码的管理维护成本。除此之外,该模式还能在开盘初始化时,通过历史数据回放直接恢复到正确的策略状态,从而降低了实盘运维中的错误风险。
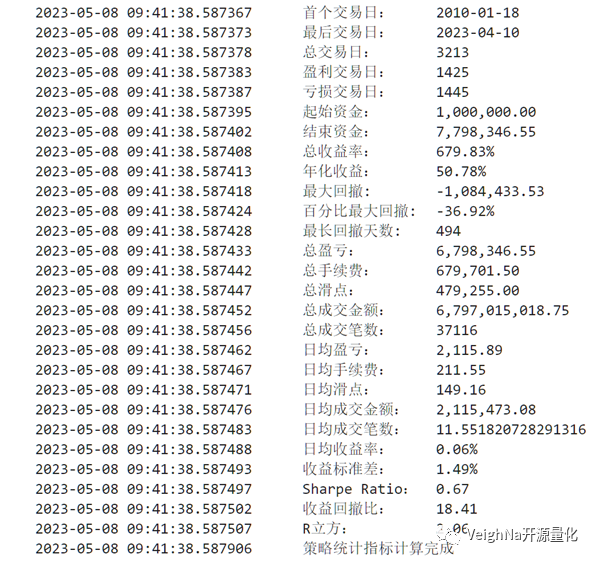
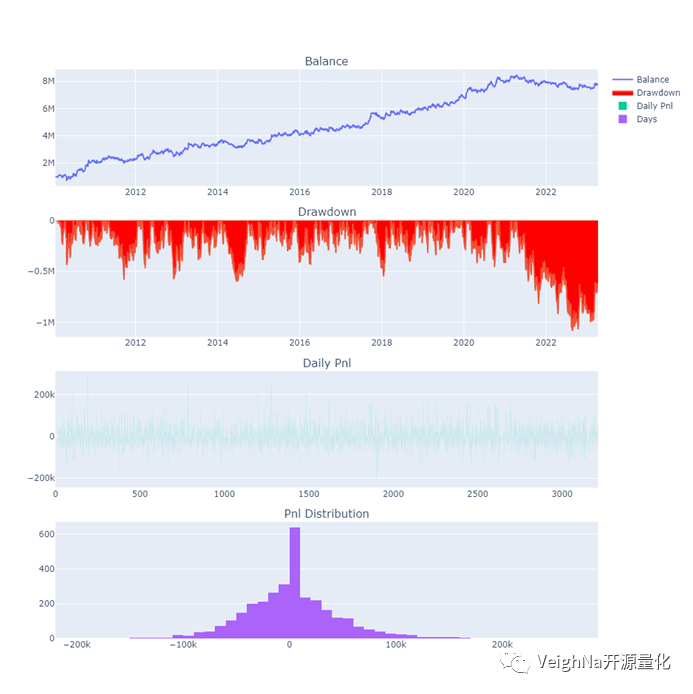
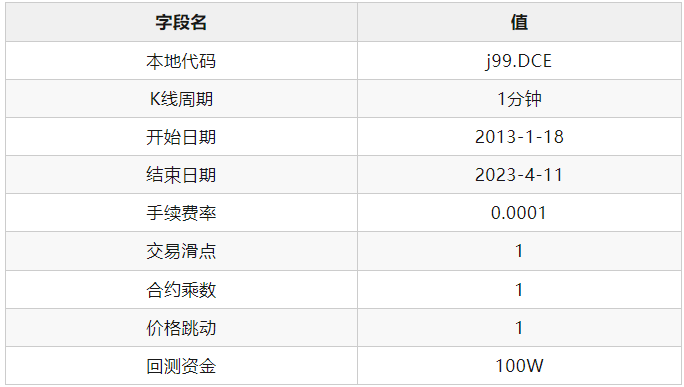
下图回测结果由米筐RQData提供的j99连续指数合约数据得到,回测配置如下:
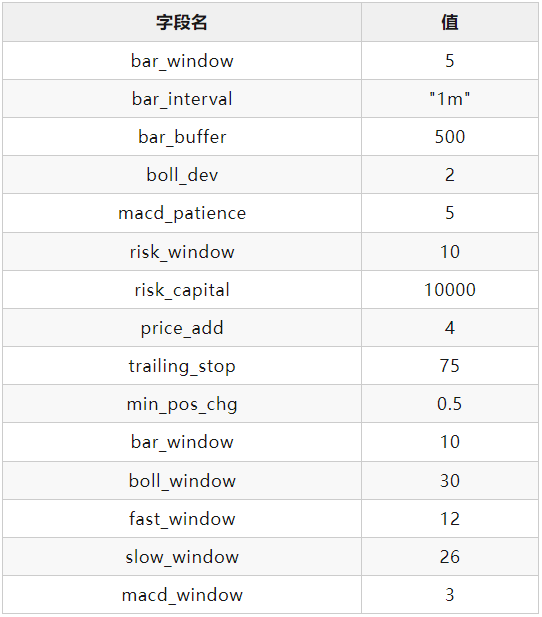
基于VeighNa Elite版CTA回测引擎中内置的R-Cubed统计指标,对BollMACD策略在j99.DCE的2013-2018时间段上进行遗传优化后,得到的策略参数如下:
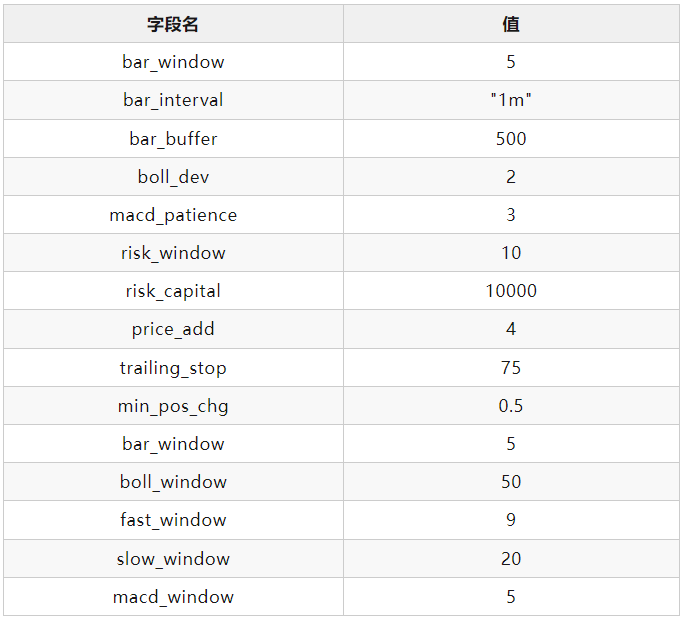
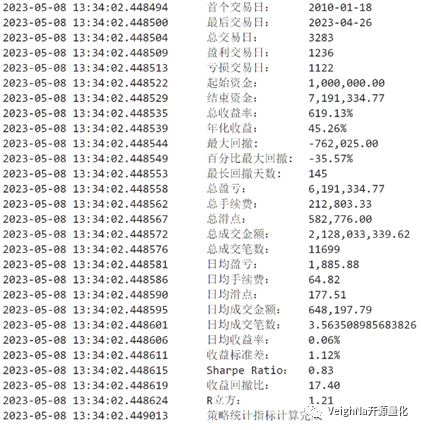
将该参数应用到2013-2023数据上的回测结果为(2019后为样本外):
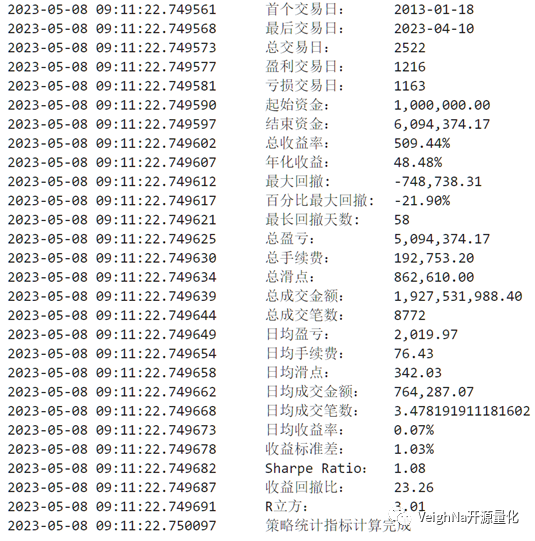
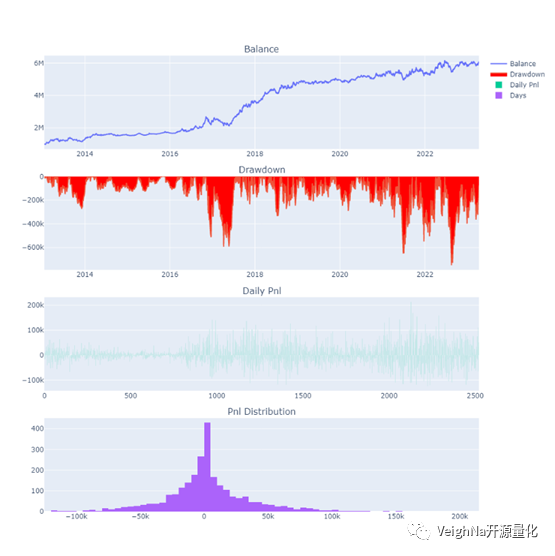
下篇文章将会进一步分享BollMACD策略在更多时间周期和期货品种上的回测绩效,欢迎关注。
VeighNa Elite版已正式上线发布1.0.3版本,目前对量化私募机构的投研人员提供一个月免费试用,感兴趣的同学请扫码添加小助手:

免责声明
文章中的信息或观点仅供参考,作者不对其准确性或完整性做出任何保证。读者应以其独立判断做出投资决策,作者不对因使用本报告的内容而引致的损失承担任何责任。
发布于vn.py社区公众号【vnpy-community】
原文作者:用Python的交易员 | 发布时间:2023-05-21
机器学习(Machine Learning,缩写ML)相关的技术已经在金融投资领域得到了非常广泛的应用,例如:价格(收益)预测、算法交易、组合优化、风险管理、基金评价等。
在大方向上,机器学习的具体分类包括:
监督学习(Supervised Learning)
非监督学习(Unsupervised Learning)
强化学习(Reinforcement Learning)
过去几年里,社区中已经有不少用户在尝试将各种机器学习技术和VeighNa平台结合起来,实现更加高效地开发量化交易策略。2023年VeighNa小班特训营将首次推出机器学习相关的主题,分享机器学习技术在CTA策略领域的应用!
目前已经有部分名额被提前报名锁定,感兴趣的同学请抓紧。老规矩还是放几张之前课程的照片:

准备完毕,静候同学们到达

学习量化,先从掌握核心框架

深入代码,分析策略逻辑细节
所有小班特训营时间定在周末两天,一共包含周六周日两个下午共计10+小时的课程,设立特训营专属答疑群,包括后续三个月的助教跟踪辅导,提供VeighNa小班特训营专属内部核心资料。
线下课程的地点在上海浦东,不方便来上海的同学我们也提供远程线上听课(直播+录播)。对于所有参加小班特训营的学员,在课程结束后都会拿到课程的完整录播视频,可永久回看。
VeighNa机器学习CTA
日期:2023年7月1日(周六)和7月2日(周日)
时间:两天下午1点-6点,共计10小时
大纲:
搭建机器学习环境
a. 选择合适的硬件机器和操作系统
b. VeighNa和GPLearn开发环境准备
c. 针对机器学习的高性能数据存储
认识遗传规划学习
a. 从【先有逻辑、后有公式】到【先有公式、后有逻辑】
b. 算法基础:种群生成、适应度评价、自然选择、组合变异
c. 数据集的拆分处理:训练集、验证集、测试集
上手CTA特征工程
a. 基础特征数据的清洗准备:加载、预处理、缓存
b. 梳理GPLearn内置特征函数:参数分类、边界情况处理
c. 时序类特征函数的扩展开发:技术指标类、统计模型类
适应度评价的选择
a. 适合量化交易的Fitness适应度评价体系
b. 简单的收益率相关性:不依赖历史回测
c. 全面的回测统计值:向量化策略回测框架
策略开发实战应用
a. 机器学习CTA的三部曲:特征、信号、策略
b. 趋势跟踪和震荡反转两种信号的实现
c. CTA策略中的细节:资金管理、止损风控、平仓出场
价格:11999元(老学员和Elite会员可享受相应折扣)
报名方式和之前一样,请发送邮件到vn.py@foxmail.com,注明想参加的课程、姓名、手机、公司、职位即可。或者也可以扫描下方二维码添加小助手咨询报名:

课程对于之前参加过小班特训营的学员优先开放。
职位职责
深入海量金融数据进行研究分析、挖掘有效信号,开发和优化量化模型策略,包括但不限于股票、期货、期权等市场,包括但不限于:
1、CTA策略、量化选股等策略的研发 ;
2、量化策略、交易系统的程序编写、调试,数据库优化等 ;
3、及时完成分配的研究任务,汇报研究进度及研究成果。
职位要求
1、国内外名校金融工程、数学、计算机、统计、物理或其他理工科相关专业研究生及以上学历(国内学校排名前15,国外学校QS前100);
2、熟练使用Python/ C++/C#编程语言;
3、具备扎实的数理基础,一流的概率统计能力,和严谨的研究习惯;
4、对大数据挖掘、概率统计、机器学习、深度学习、时间序列分析、模式识别、自然语言处理与提取有深入的理解和实践经验;
5、积极思考并积极求证,对解决复杂问题有强烈兴趣,能够自我驱动;
6、2024届及以后毕业应届生,实习期至少保证3个月以上,有留用机会。
其他信息
加分项:
1、国内外各种竞赛经历并取得优异成绩;
2、有计算机领域顶会或顶刊paper发表;
3、有券商金工、私募等中高频量化研究实习经历并取得一定的研究成果,包括但不限于股票/期货/期权等各类二级市场品种;
4、对机器学习有过实际项目经验。
联系方式
dyzczp@cfsc.com.cn,简历请以姓名+学校+专业命名
工作地点
上海
发布于veighna社区公众号【vnpy-community】
原文作者:用Python的交易员 | 发布时间:2023-05-16
【VeighNa Elite版】已经于3月底正式发布上线,采用多进程架构实现对多核心CPU算力的充分利用,解决GIL全局锁带来的性能瓶颈问题,同时提供了诸多面向专业交易员的量化功能:Elite策略引擎、内嵌算法执行、批量移仓助手、多账户支持、市场深度交易等。
《VeighNa全实战进阶》期权系列的第三阶段课程已经在计划准备中,预计将在今年下半年和大家见面。
在那之前可以先来回顾一下之前两阶段的课程,本篇基于《期权零基础入门》课程的内容,制作了这张【知识要点图】:
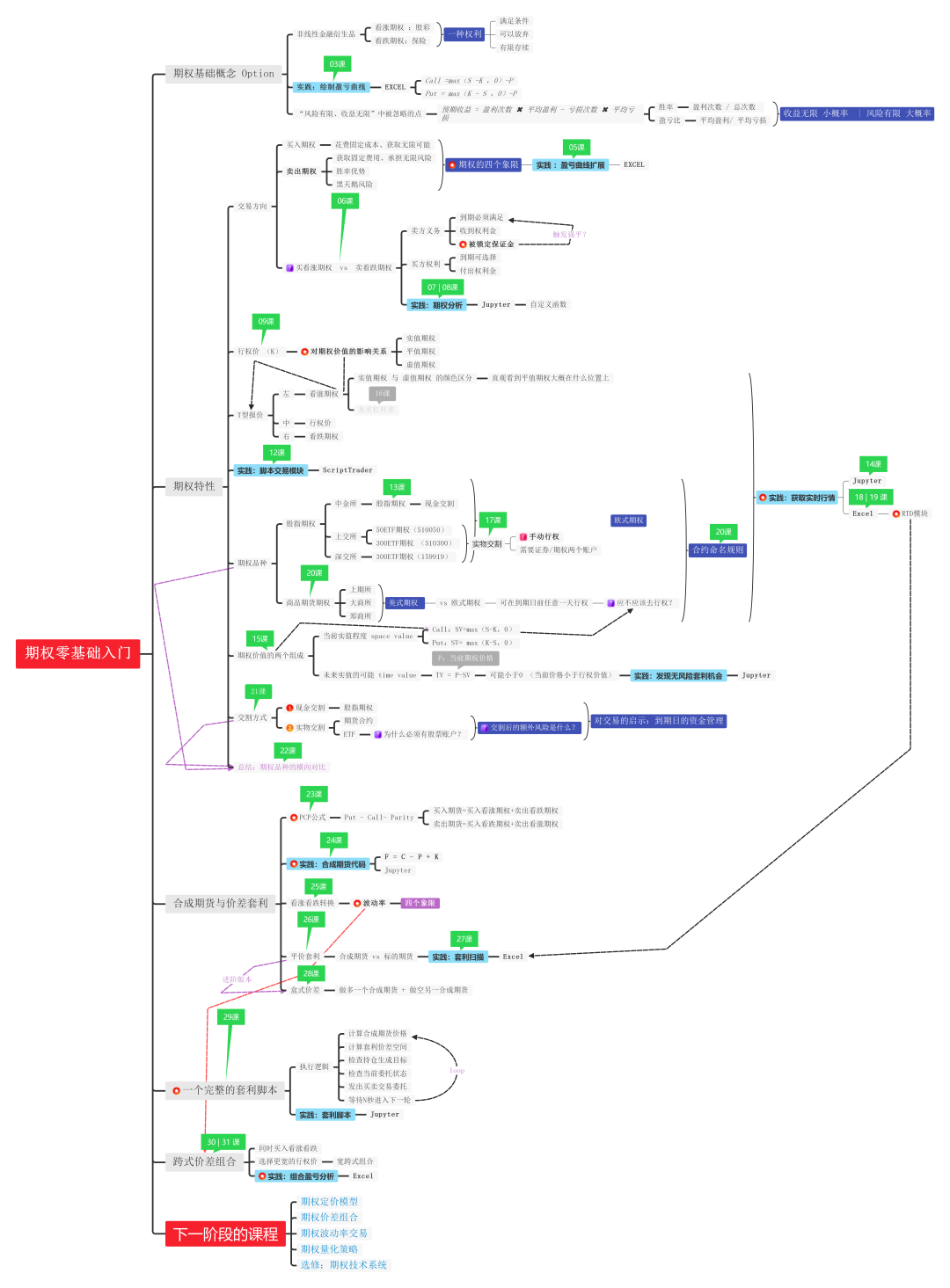
看完对课程感兴趣的话,请戳【课程传送门】。
本课程同样包含在【VeighNa Elite版】的会员权益范围内,其他会员权益包括:
感兴趣的同学请扫描下方二维码,或者点击底部的【阅读原文】跳转:

发布于veighna社区公众号【vnpy-community】
原文作者:用Python的交易员 | 发布时间:2023-05-10
《30天精进Python交易GUI》课程已经于2023年4月全部收尾!基于课程内容,我们制作了这张【知识要点图】:
看完对课程感兴趣的话,请戳【课程传送门】。
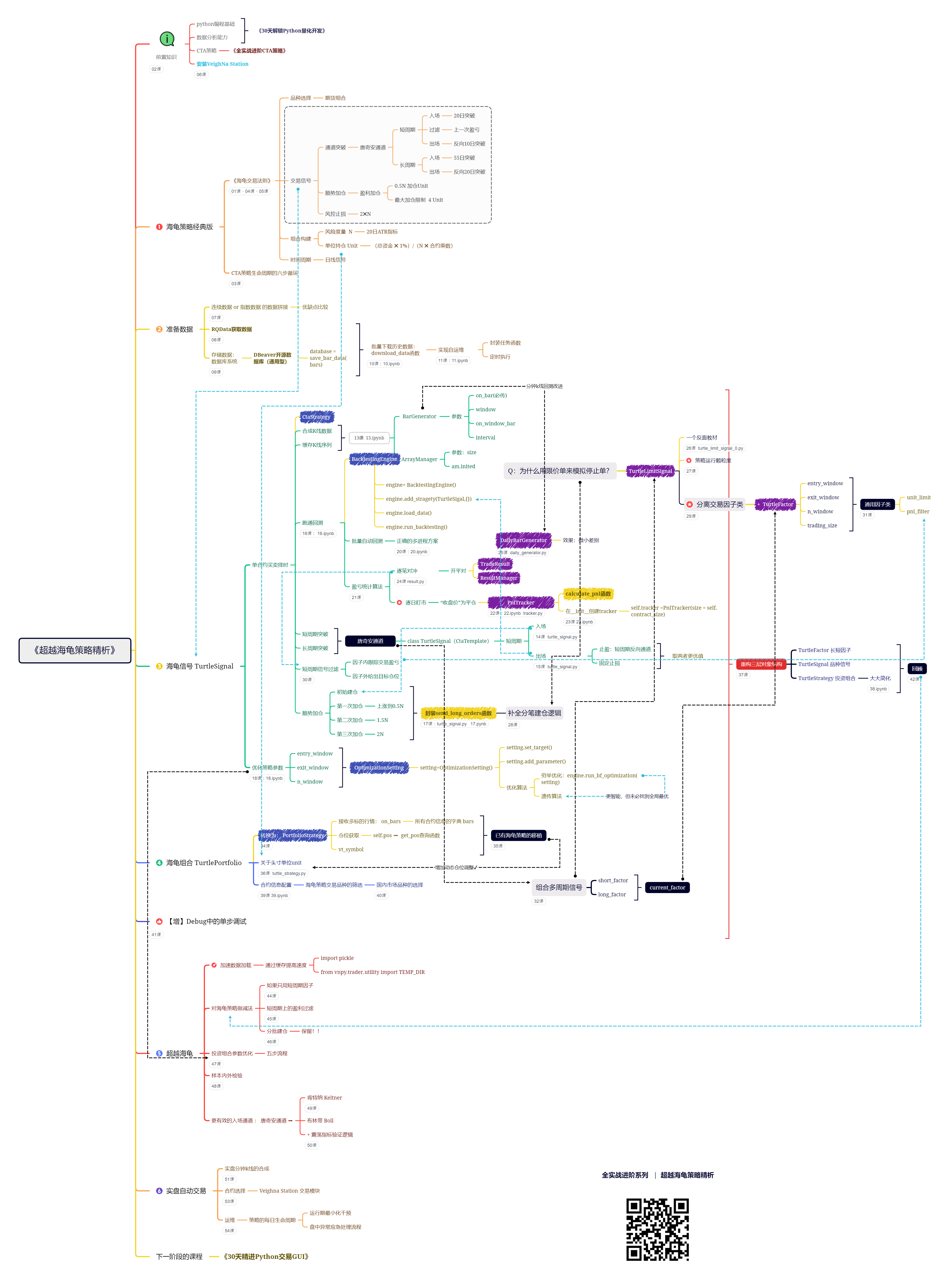
至此,【量化交易零基础入门系列】内容告一段落,下一阶段课程将会回归【VeighNa全实战进阶系列】的期权量化交易内容,预计将在7月下旬上线,感兴趣的同学欢迎关注!

