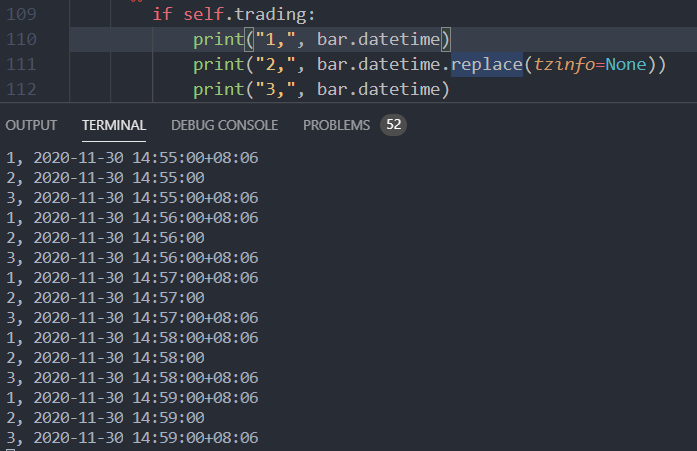
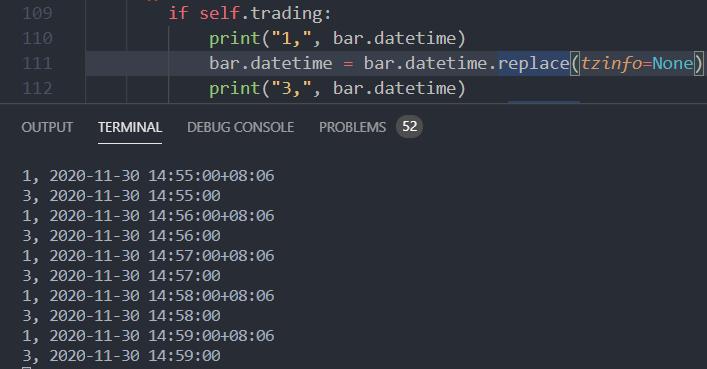
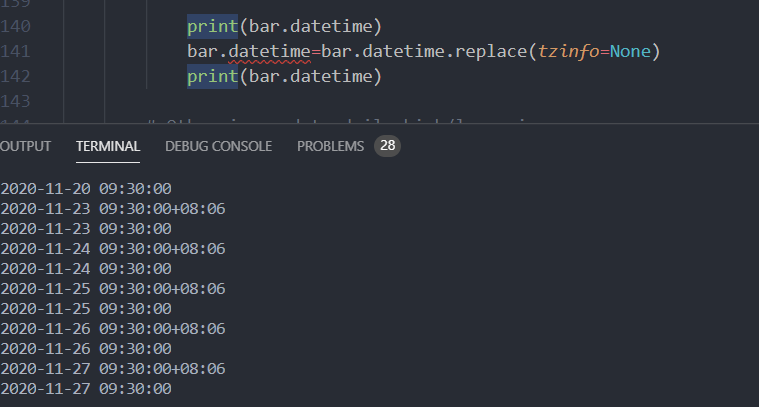
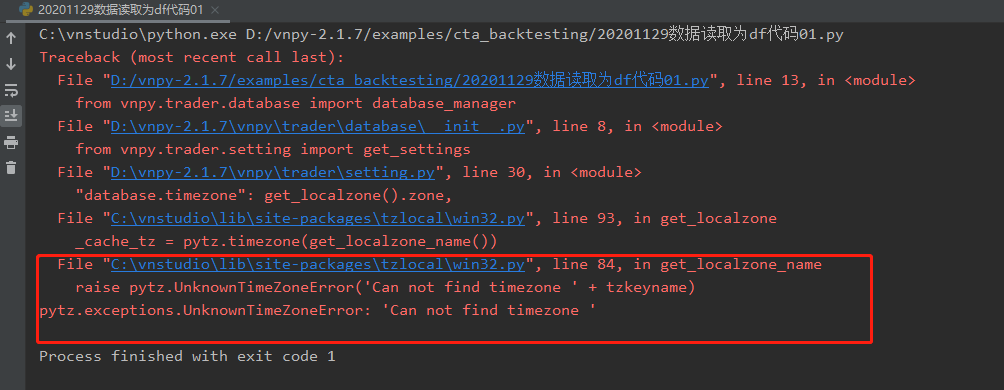
问题在于从数据库读取出来的时候 时间就错了,我觉得这算个小bug了
数据库存储的是+8:00,读取出来是+8:06
+
+
+
xiaohe wrote:
要=才能改变属性吧,直接去掉时区信息就可以了呀
+
+
+
+
+
+
++
大佬 问题的核心点在于不会在pandas中统一修改一整列的时区,for循环很费时
取一年的1分钟bardata,用for循环成功修改每个bardata的时区属性(还没成功),这样内置的循环,取一次数据将耗时20s左右,性能降低了,而且还没写成功
+
+
+
+
现在问题是我存入的数据时区是正确的的,但是我按照自定义的load—bar——data去数据的时候,时区又被识别为一个错误的偏离上海时区+6分钟的时区,导致我生成的pandas dataframe 索引有问题
new_tzinsfo_bar_list = []#正确时区bardata的list
for data in false_tzinsfo_bar_data_list:
data.datetime.replace(tzinfo=None)
new_tzinsfo_bar_list.append(data)```
不对这段代码应该这样写,但是经过测试还是错了,并没有改变bar对象的属性,
如果用data.datetime.replace(tzinfo=None)代码
只是获得了一个时间类型,没有获得一个正确时区的bardata对象
xiaohe wrote:
shunyuzhiqian wrote:
xiaohe wrote:
输出的时候请用replace(tzinfo=None)处理一下时间戳,2.1.3以后vnpy支持了全球时间戳,在数据后加了时区信息,中国地区是+08:06。但是你输出的时候可能被本地转成UTC时间了(+08:00)
+
+
++不会在输出的时候请用replace(tzinfo=None)处理一下时间戳。。
我把变通方法贴在这个帖子了,时区搞得头痛
https://www.vnpy.com/forum/topic/5171
+
+
+
+
+
+
+
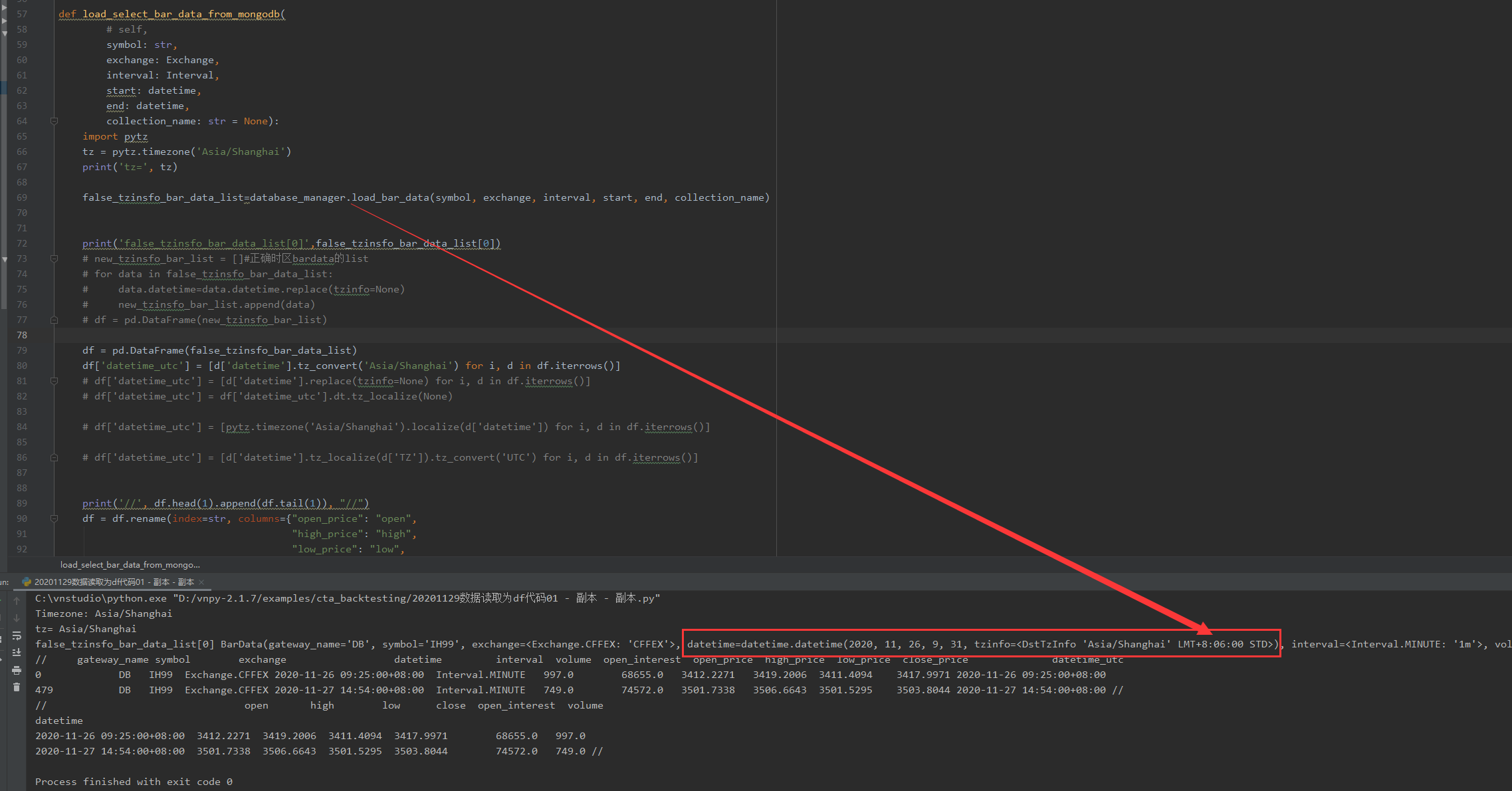
大佬,单独的一个bardata的时区信息我会改,我想一次性转化dataframe的那一列,如果在取数据那里嵌套一个for循环,我担心取1万个1分钟bardata是否会降低效率
def load_select_bar_data_from_mongodb(
# self,
symbol: str,
exchange: Exchange,
interval: Interval,
start: datetime,
end: datetime,
collection_name: str = None):
false_tzinsfo_bar_data_list=database_manager.load_bar_data(symbol, exchange, interval, start, end, collection_name)
new_tzinsfo_bar_list = []#正确时区bardata的list
for data in false_tzinsfo_bar_data_list:
new_tzinsfo_bar_list.append(data.datetime.replace(tzinfo=None))
df = pd.DataFrame(new_tzinsfo_bar_list)
df = df.rename(index=str, columns={"open_price": "open",
"high_price": "high",
"low_price": "low",
"close_price": "close",
})
data_select_columns = ["open", "high", "low", "close", "open_interest", "volume"]
df = df.set_index('datetime')[data_select_columns]
print('//',df.head(1).append(df.tail(1)),"//")
return dfxiaohe wrote:
on_bar里传进的BarData里不都有吗
+
+
+
对对 大佬 我恍惚了。。
MongoDB的collection_name可以再engine.add_strategy(AtrRsiStrategy, {这里传入})对吧
+
+
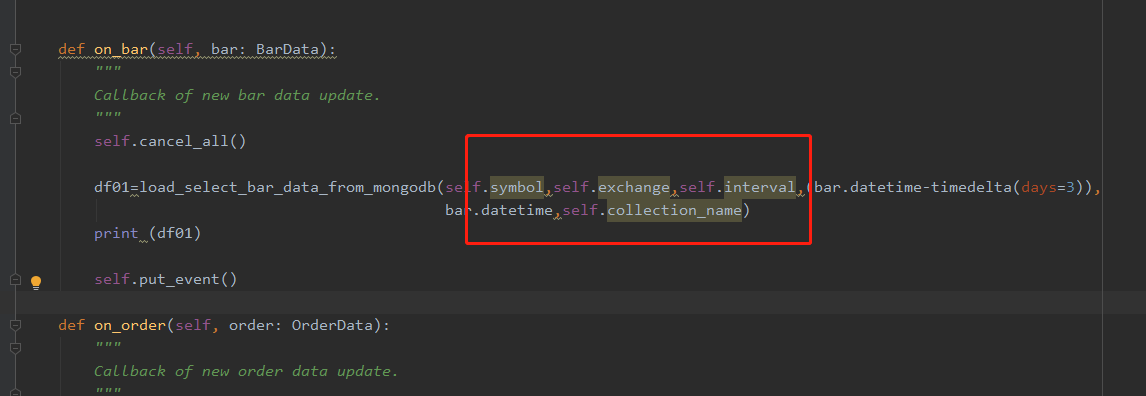
策略无法获得引擎设置的属性(如图)
1++++
首先在回测代码中通过引擎属性赋值参数如下:
#%%
engine = BacktestingEngine()
engine.set_parameters(
vt_symbol="IH99.CFFEX",
interval="1m",
start=datetime(2019, 6, 1),
end=datetime(2019, 6, 30),
rate=0.3/10000,
slippage=0.2*5,
size=300,
pricetick=0.2,
capital=1_000_000,
collection_name = "IH99"
)
engine.add_strategy(AtrRsiStrategy, {})+
+
2+++++
AtrRsiStrategy策略中onbar如下:
def on_bar(self, bar: BarData):
"""
Callback of new bar data update.
"""
self.cancel_all()
df01=load_select_bar_data_from_mongodb(self.symbol,self.exchange,self.interval,(bar.datetime-timedelta(days=3)),
bar.datetime,self.collection_name)
print (df01)
self.put_event()注:load_select_bar_data_from_mongodb是自定义的从MongoDB数据库读取bardata并生成dataframe的函数,有关于symbol等参数需要传入。
+
+
+
3++++++++++
回测运行报错如下:
2020-11-30 22:50:43.167187 Traceback (most recent call last):
File "D:\vnpy-2.1.7\vnpy\app\cta_strategy\backtesting.py", line 315, in run_backtesting
self.callback(data)
File "D:\vnpy-2.1.7\vnpy\app\cta_strategy\strategies\atr_rsi_strategy.py", line 129, in on_bar
df01=load_select_bar_data_from_mongodb(self.symbol,self.exchange,self.interval,(bar.datetime-timedelta(days=3)),
AttributeError: 'AtrRsiStrategy' object has no attribute 'symbol'+
+
+
4++++++++++
所以想请教大佬们,如何让策略接受到上述回测引擎engine.set_parameters所设置的属性?
如果大佬们有不用变通的方法 还请斧正分享
关于时区被格式化的位置在如下这行代码里
data01=database_manager.load_bar_data(symbol, exchange, interval, start, end, collection_name)
打印data01[0] 如下:
data01[0] BarData(gateway_name='DB', symbol='IH9902', exchange=<Exchange.CFFEX: 'CFFEX'>, datetime=datetime.datetime(2020, 11, 26, 9, 37, tzinfo=<DstTzInfo 'Asia/Shanghai' LMT+8:06:00 STD>), interval=<Interval.MINUTE: '1m'>, volume=997.0, open_interest=68655.0, open_price=3412.2271, high_price=3419.2006, low_price=3411.4094, close_price=3417.9971)++
+
+
尽管这里显示bardata的时区是tzinfo=<DstTzInfo 'Asia/Shanghai' LMT+8:06:00 STD>,但是经过pd.DataFrame(data01)之后,时间戳会被调整为正常如下:
// open high low close open_interest volume
datetime
2020-11-26 09:31:00+08:00 3412.2271 3419.2006 3411.4094 3417.9971 68655.0 997.0
2020-11-27 15:00:00+08:00 3501.7338 3506.6643 3501.5295 3503.8044 74572.0 749.0 //恍恍惚惚。。哈哈
复现上面结果的前提是必须把存入数据时的时区信息设为utc_86 = timezone(timedelta(hours=7,minutes=54))
不然最后的结果是偏离的
数据库读取代码(无内部for循环)如下:
def load_select_bar_data_from_mongodb(
# self,
symbol: str,
exchange: Exchange,
interval: Interval,
start: datetime,
end: datetime,
collection_name: str = None):
data01=database_manager.load_bar_data(symbol, exchange, interval, start, end, collection_name)
df = pd.DataFrame(data01)
df = df.rename(index=str, columns={"open_price": "open",
"high_price": "high",
"low_price": "low",
"close_price": "close",
})
data_select_columns = ["open", "high", "low", "close", "open_interest", "volume"]
df = df.set_index('datetime')[data_select_columns]
print(df)
return dfxiaohe wrote:
输出的时候请用replace(tzinfo=None)处理一下时间戳,2.1.3以后vnpy支持了全球时间戳,在数据后加了时区信息,中国地区是+08:06。但是你输出的时候可能被本地转成UTC时间了(+08:00)
+
+
++
不会在输出的时候请用replace(tzinfo=None)处理一下时间戳。。
我把变通方法贴在这个帖子了,时区搞得头痛
https://www.vnpy.com/forum/topic/5171
变通解决方法:将bardata时间偏离设置为7小时54分。即utc_86 = timezone(timedelta(hours=7,minutes=54)),这样读取出来的数据分钟就是正常的了
csv导入MongoDB代码如下:
from vnpy.trader.constant import (Exchange, Interval)
import pandas as pd
from vnpy.trader.database import database_manager
from vnpy.trader.object import (BarData,TickData)
from datetime import datetime, timedelta, timezone
# 中国时区是+8,对应参数hours=8
# utc_8 = timezone(timedelta(hours=8))
utc_86 = timezone(timedelta(hours=7,minutes=54))#变通
# datetime=row.datetime.replace(tzinfo=utc_8)
import pytz
tz = pytz.timezone('Asia/Shanghai')
print('tz=',tz)
# 封装函数
def move_df_to_mongodb(imported_data:pd.DataFrame,collection_name:str):
bars = []
start = None
count = 0
for row in imported_data.itertuples():
bar = BarData(
symbol=row.symbol,
exchange=row.exchange,
# datetime=tz.localize(row.datetime),
datetime=row.datetime.replace(tzinfo=utc_86),
interval=row.interval,
volume=row.volume,
open_price=row.open,
high_price=row.high,
low_price=row.low,
close_price=row.close,
open_interest=row.open_interest,
gateway_name="DB",
)
bars.append(bar)
# do some statistics
count += 1
if not start:
start = bar.datetime
print ('start=',start)
end = bar.datetime
# insert into database
database_manager.save_bar_data(bars,collection_name)
print(f'Insert Bar: {count} from {start} - {end}')
if __name__ == "__main__":
# 读取需要入库的csv文件,该文件是用gbk编码
imported_data = pd.read_csv('IH99_20101127_20201127_2.csv',encoding='gbk')
# 将csv文件中 `市场代码`的 SC 替换成 Exchange.SHFE SHFE
imported_data['exchange'] = Exchange.CFFEX
# 增加一列数据 `inteval`,且该列数据的所有值都是 Interval.MINUTE
imported_data['interval'] = Interval.MINUTE
# 明确需要是float数据类型的列
float_columns = ['open','high','low','close','volume','open_interest']
for col in float_columns:
imported_data[col] = imported_data[col].astype('float')
# 明确时间戳的格式
# %Y/%m/%d %H:%M:%S 代表着你的csv数据中的时间戳必须是 2020/05/01 08:32:30 格式
datetime_format = '%Y%m%d %H:%M:%S'
imported_data['datetime'] = pd.to_datetime(imported_data['datetime'],format=datetime_format)
品种代码='IH9902'
imported_data['symbol'] = 品种代码
# 因为没有用到 成交额 这一列的数据,所以该列列名不变
# imported_data.columns = ['exchange','symbol','datetime','open','high','low','close','volume','成交额','open_interest','interval']
# imported_data = imported_data.rename(index=str,
# columns={"时间": "datetime",
# "KQ.i@CFFEX.T.high": "high",
# "KQ.i@CFFEX.T.low": "low",
# "KQ.i@CFFEX.T.close": "close",
# "KQ.i@CFFEX.T.volume": "volume",
# "KQ.i@CFFEX.T.close_oi": "open_interest",
# })
# 筛选展示的列名
# imported_data = imported_data[["datetime","open", "high", "low", "close", "open_interest", "volume"]]
print('//',imported_data.head(1).append(imported_data.tail(1)),"//")
move_df_to_mongodb(imported_data,品种代码)+
+
+
+
用Python的交易员 wrote:
另一个帖子里回答你了,另外这是用的什么云服务器?Windows没有时区配置,可能引发很多奇怪的问题,这种云服务商建议不要用
感谢大佬指导!!确实是时区配置没设置,目前没用服务器,是个人电脑没有设置时区。。。
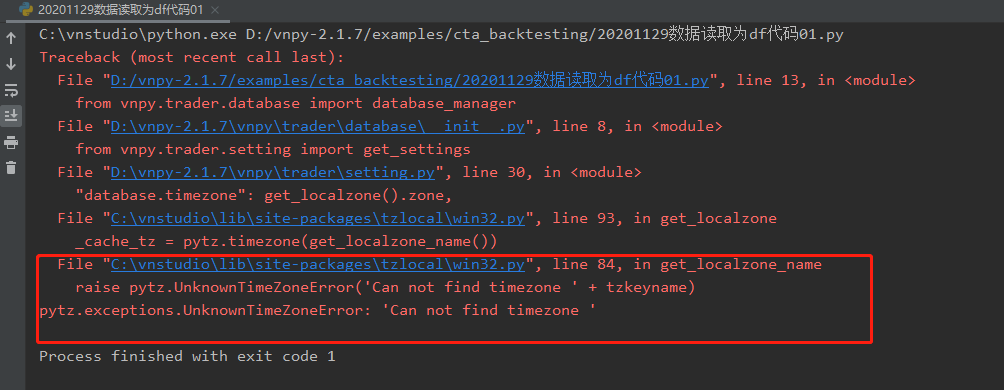
上面这个出现模块错误可以通过暴力设置 时区为china解决,
但是在取数据的时候,出现了6分钟的时间戳偏差,
所以我想用另外一种暴力方法解决导数据出来的时间戳偏差,
而不是纠结于外国人搞得这个垃圾tzlocal模块。。。。。。。。。。。。
主要是tclocal这个模块老报错
我就把他强行设置为 China
不知道是不是这个深层原因
def get_localzone_name():
# Windows is special. It has unique time zone names (in several
# meanings of the word) available, but unfortunately, they can be
# translated to the language of the operating system, so we need to
# do a backwards lookup, by going through all time zones and see which
# one matches.
handle = winreg.ConnectRegistry(None, winreg.HKEY_LOCAL_MACHINE)
TZLOCALKEYNAME = r"SYSTEM\CurrentControlSet\Control\TimeZoneInformation"
localtz = winreg.OpenKey(handle, TZLOCALKEYNAME)
keyvalues = valuestodict(localtz)
localtz.Close()
print ('keyvalues=',keyvalues)
if 'TimeZoneKeyName' in keyvalues:
# Windows 7 (and Vista?)
# For some reason this returns a string with loads of NUL bytes at
# least on some systems. I don't know if this is a bug somewhere, I
# just work around it.
tzkeyname = keyvalues['TimeZoneKeyName'].split('\x00', 1)[0]
else:
# Windows 2000 or XP
# This is the localized name:
tzwin = keyvalues['StandardName']
# Open the list of timezones to look up the real name:
TZKEYNAME = r"SOFTWARE\Microsoft\Windows NT\CurrentVersion\Time Zones"
tzkey = winreg.OpenKey(handle, TZKEYNAME)
print ('tzkey=',tzkey)
# Now, match this value to Time Zone information
tzkeyname = None
for i in range(winreg.QueryInfoKey(tzkey)[0]):
subkey = winreg.EnumKey(tzkey, i)
sub = winreg.OpenKey(tzkey, subkey)
data = valuestodict(sub)
sub.Close()
try:
if data['Std'] == tzwin:
tzkeyname = subkey
break
except KeyError:
# This timezone didn't have proper configuration.
# Ignore it.
pass
tzkey.Close()
handle.Close()
if tzkeyname is None:
raise LookupError('Can not find Windows timezone configuration')
# print ('tzkeyname=',tzkeyname)
# print('type(tzkeyname)=', type(tzkeyname))
# tzkeyname= "China"
# print('tzkeyname=', tzkeyname)
# print('type(tzkeyname)=', type(tzkeyname))
print('tzkeyname=', tzkeyname)
timezone = win_tz.get(tzkeyname)
if timezone is None:
# Nope, that didn't work. Try adding "Standard Time",
# it seems to work a lot of times:
timezone = win_tz.get(tzkeyname + " Standard Time")
# Return what we have.
if timezone is None:
raise pytz.UnknownTimeZoneError('Can not find timezone 123456' + tzkeyname)
return timezone不是存入数据的时间设置问题么?
我不会改输出时候的时区设置。。。。
我感觉我的浏览器时区 都是错的 现在是凌晨,却显示上午,看着贼别扭

时间驱动合成k线,目前我还没写出来。。。
发现应该是时区问题 但不知道如何解决
首先在CSV导入数据库的时候我对时间戳做了如下设置
中国时区是+8,对应参数hours=8
utc_8 = timezone(timedelta(hours=8))
bar = BarData(
symbol=row.symbol,
exchange=row.exchange,
datetime=row.datetime.replace(tzinfo=utc_8),#20201129发现vnpy需要时区数据
interval=row.interval,
volume=row.volume,
open_price=row.open,
high_price=row.high,
low_price=row.low,
close_price=row.close,
open_interest=row.open_interest,
gateway_name="DB",
)尽管我做了如上设置,在回测是打印每分钟的时间戳 ,打印信息如下:|
C:\vnstudio\python.exe D:/vnpy-2.1.7/examples/cta_backtesting/BACKTESTING20201129.py
tzkeyname= China
2020-11-30 00:33:26.563880 开始加载历史数据
2020-11-30 00:33:26.950880 历史数据加载完成,数据量:4560
--策略接受到的分钟bar时间戳为= 2019-06-03 09:31:00+08:06
open high ... open_interest volume
datetime ...
2019-05-31 09:25:00+08:00 2713.5703 2716.4436 ... 54422.0 767.0
2019-05-31 14:54:00+08:00 2702.3911 2704.0818 ... 55943.0 432.0
[2 rows x 6 columns]
--策略接受到的分钟bar时间戳为= 2019-06-03 09:32:00+08:06
open high ... open_interest volume
datetime ...
2019-05-31 09:25:00+08:00 2713.5703 2716.4436 ... 54422.0 767.0
2019-05-31 14:54:00+08:00 2702.3911 2704.0818 ... 55943.0 432.0可以看到“策略接受到的分钟bar时间戳为= 2019-06-03 09:31:00+08:06 ”
+08:06,应该是这个问题导致的上述6分钟,所以我现在该如何解决呢,是那个导入数据时设置的时区的参数不对是么,该怎么改呢,请教各位大佬
中国时区是+8,对应参数hours=8
utc_8 = timezone(timedelta(hours=8)) 是这里要明确分钟也是0么